

November 21, 2014
Spark Just Passed Hadoop in Popularity on the Web–Here’s Why
Interest in Apache Spark surpassed Apache Hadoop for the first time last month, according to Google Trends. While it’s not a definitive statement of Spark’s actual impact on big data processing in the real world, it does indicate the enormous momentum the in-memory analytics software has garnered during a phenomenal run in 2014.
As you can see from the Google Trends graphic–which compares the relative popularity of search terms that people enter and prevalence of news articles about given topics–Apache Spark went from a relative unknown to big data superstar in a matter of months. Coming out of Cal Berkeley’s AMPLab, Spark was just one of a handful of promising distributed computing frameworks at this time last year.

In October Apache Spark (blue line) passed Apache Hadoop (red line) in popularity according to Google Trends
But from January through October of this year, interest in Spark skyrocketed. It went from next to nothing into the most talked-about and search-for big data technology in the land—even bigger than big data’s big daddy, Apache Hadoop.
So why has Spark risen so far and so fast? Spark’s popularity has largely been driven by developers who are tired of the complexity of MapReduce and who want an easier and faster way to build big data applications, primarily for Hadoop.
Setting up data flows is critical in today’s big data analytic apps, and Spark simply makes that task easier. When you get Spark, you get a variety of processing engines, including the Spark SQL capability, Spark Streaming, and the MLlib machine learning library (additional capabilites like GraphX for graph analytics, the SparkR capability for running R-based applications, and hte BlinkDB capability are also in the wings). Moving data from one processing engine to the next is more easily done under Spark than if you had to cobble together multiple Hadoop-based
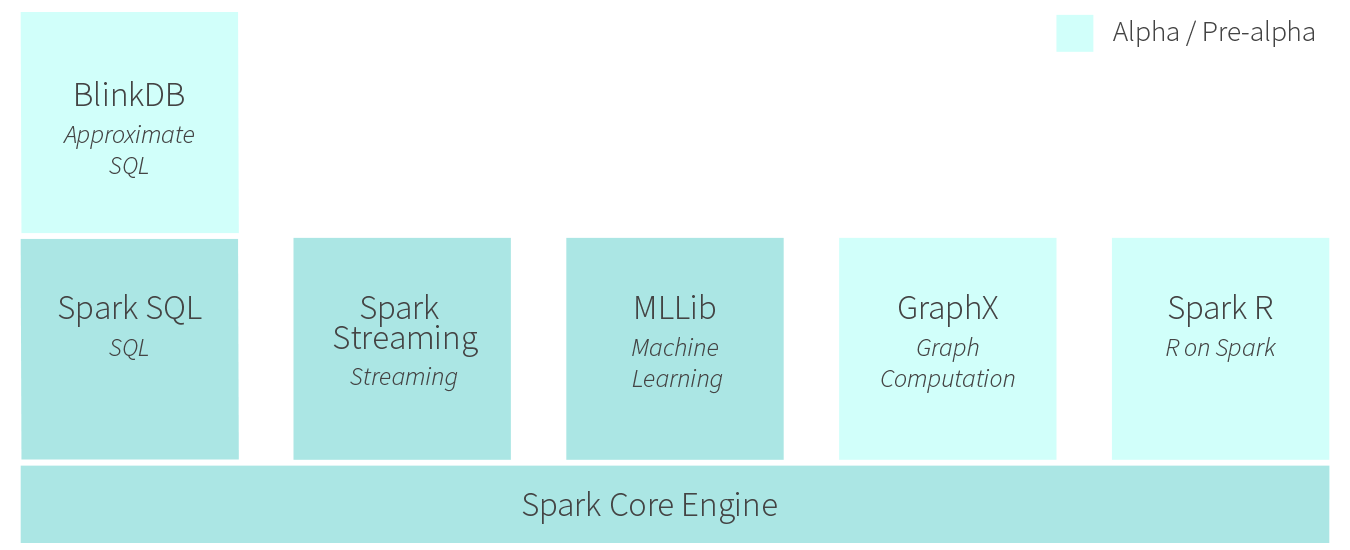 processing engines, such as MapReduce, Impala, Storm, Mahout, and Giraph.
processing engines, such as MapReduce, Impala, Storm, Mahout, and Giraph.
Spark also has speed on its side. Last month Databricks, the company behind Spark, released benchmark results that demonstrated Spark running three times faster than MapReduce on a 100TB sort workload, using 10 times less computing power. It also out-sorted MapReduce by a factor of four on a 1PB workload, using significantly less hardware. In some instances, Spark can run upwards of 100 times faster than MapReduce applications, Spark backers have claimed.
In the beginning of the year, there were about 200 contributors to Spark, which made it a more active project than Hadoop MapReduce. Since then, more than 100 additional contributors have signed on to help develop Spark.
Where will it go in 2015? Don’t bet against it from continuing the rise. “Spark is a fast moving project,” Databricks Head of Engineering, Ali Ghodsi, told Datanami last month. “It’s actually the most active big data project now out there. There’s a lot happening to it.”
The community of Hadoop software vendors are also increasingly turning to Spark to power big data analytic applications. Platfora, ClearStory Data, and Alpine Data Labs have all committed to using Spark in their Hadoop-based applications, while Trifacta and Paxata are also counting on Spark’s speed to power big data transformation solutions. Datameer is re-architecting its solution with Spark in mind, and Glassbeam, which builds a NoSQL-based product that helps companies make sense of big data generated by devices connected to the Internet of Things (IoT), recently adopted Spark running under Cassandra.
Spark is outpacing Hadoop itself as the hottest big data technology at the moment. The fact that Spark doesn’t need Hadoop creates an interesting tension in the marketplace. The folks at Databricks will tell you that they learned from Hadoop’s early mistakes and are seeking to eliminate much of the complexity that plagues first-gen Hadoop and MapReduce implementations.
Unfortunately, getting Spark running on-premise is still hard, Databricks says. That’s where its Databricks Cloud implementation of Spark comes in handy. And while Databricks Cloud doesn’t use Hadoop, many of its early customers analyze HDFS-resident data.![]()
In many ways, Spark is helping to fulfill the big data promises and dreams of Hadoop and that has forced the Hadoop distributors to take notice. Cloudera was an early supporter of Spark and has been shipping the Spark software with its latest Hadoop distribution CDH 5, since it was in beta over a year ago. MapR Technologies has also supported the entire Apache stack since April.
It took a little longer for Hortonworks to catch the Spark wave. Hortonworks, which sticks closer to the core trunk of open source Hadoop and has openly questioned Spark’s readiness and ability to scale at the high end, started talking about making Spark a first-class citizen on Hadoop 2.0 and YARN during the summer. As it stands, Spark will be fully supported in Hortonworks Data Platform version 2.2, which it unveiled in October and is currently in tech preview.
Hortonworks is fully on board Spark bandwagon now and is ramping up efforts to fully integrate the technology with the rest of the Hadoop stack, which Hortonworks VP of strategic marketing John Kreisa recently described as a “shared vision for Apache Spark on Hadoop.”
“We’ve seen this unbridled excitement around Spark really over the past eight months,” Hortonworks Director of Product Marketing Jim Walker told Datanami recently. “It’s fascinating how quickly this is picking up in the broader enterprise.”
Related Items:
Hadoop ISVs Break Away from MapReduce, Embrace Spark, In-Memory Processing
Spark Smashes MapReduce in Big Data Benchmark
Apache Spark: 3 Real-World Use Cases
Applications:
Data Mining
Technologies:
Frameworks
Vendors:
Alpine Data Labs, ClearStory Data, Cloudera, Databricks, Datameer, Glassbeam, Hortonworks, MapR Technologies, Paxata, Platfora, Trifacta
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States