


June 26, 2014
Apache Spark Gets YARN Approval from Hortonworks

Hortonworks today announced that Apache Spark is certified to work with YARN, the quarterback calling plays in next-gen Hadoop v2 clusters. The YARN stamp of approval clears the way for Hortonworks to fully support Spark for machine learning analytic workloads in a new release of HDP later this year.
The prospect of running the in-memory Spark framework on Hadoop has garnered a lot of interest over the past year and a half, in particular as a faster and easier-to-program replacement for MapReduce. Developers like the idea that they can use a single API to access four Spark tools, including SparkSQL for interactive queries, Spark Streaming for streaming data, MLlib for machine learning, and Graphx for graph computation. They also like that they can work with Spark through Scala, and aren’t restricted to Java.
Spark became a full-fledged Apache project earlier this year, and is maturing quickly thanks to the work of more than 200 contributors. Databricks, the company behind the Cal Berkeley AMPLab creation, says Spark is the most active project in the Hadoop ecosystem. You’ll be hearing a lot more about Spark starting Monday, when the Spark Summit kicks off in San Francisco.
The folks at Hortonworks and Cloudera are fully aware of the Spark phenomenon, and are embracing it in their Hadoop distributions to varying degrees. In February, Cloudera announced support for Spark version 0.9 in CDH 4.4; it’s also supported Spark in CDH 5, which is built on Hadoop version 2, since it was in beta.
In April, Hortonworks announced limited support for Spark as a tech preview in HDP 2.1. As part of that tech preview, developers at Hortonworks and Databricks worked through the open source community to ensure that Spark can run on YARN. Hortonworks launched its YARN Ready program in June to help ISVs support YARN and to drive awareness of the importance of YARN as part of next-gen Hadoop deployme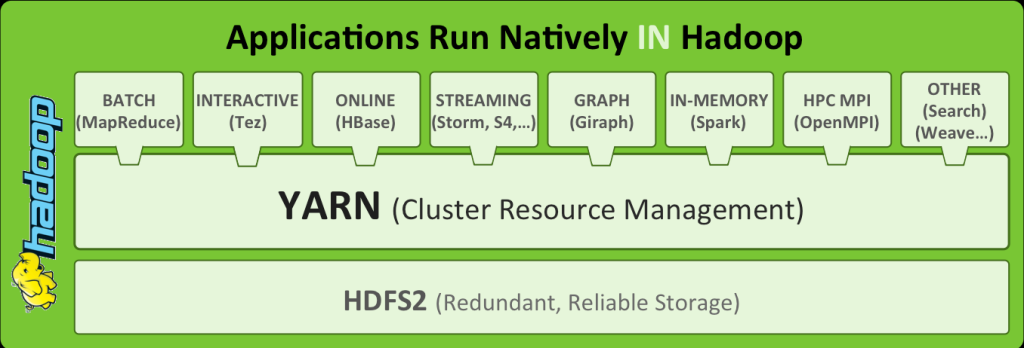 nts.
nts.
While Spark has Hortonworks seal of approval for YARN, that does not mean that Spark is ready for HDP, says Hortonworks vice president of corporate strategy Shaun Connolly. “Apache Spark on YARN has run through the test that we’ve done as part of the YARN Ready program,” he tells Datanami. “Once it finishes its tech preview mode, which it is still in…it will become part of the platform [HDP] and our existing customers will get support for that component as part of the platform.”
Spark supports YARN natively, which provides the lowest level of integration between the application framework and the Hadoop resource manager. Getting Spark supported on YARN was critical step because it ensures that Spark applications can co-exist with other applications running on Hadoop, such as Hive, Pig, HBase, and MapReduce. YARN support is also critical for ensuring that Spark can peacefully co-exist with other Hadoop components, such as the Ambari monitoring and management tool and the XA Secure tools that Hortonworks recently acquired and will soon bake into HDP, says Hortonworks founder and architect Arun Murthy.

Hortonworks co-founder and architect Arun Murthy
“As you’re bringing new technologies into the ecosystem, we have to make sure that we have a coherent experience all across the stack,” Murthy tells Datanami. “And typically it’s not code work. We like doing the code work. But we also have to do the hard work to make sure that it’s operational and consumable by the wide enterprise.”
One of the changes occurring with Hadoop version 2 is the shift from homogenous hardware resources in “traditional” Hadoop to a heterogeneous combination of hardware with different attributes. Spark, with its focus on in-memory processing, brings different resource demands to a Hadoop cluster than interactive SQL or batch MapReduce, and it’s up to YARN to handle those differences.
“As people get more comfortable with Spark over next 12 months, they’ll start asking questions like ‘How do I optimize some of my Spark workloads in YARN?'” Murthy says. “We’re adding support in YARN for adding labels to nodes. So an administrator can add a label to a node and say it’s a high memory node or Spark node. Then when an application comes in, the scheduler will be smart enough to say, ‘I know you’re a Spark application. I realize you need high memory. So now I’m going to go allocate resources to you only on the high-memory nodes.'”
These are the sort of technical challenges that Hortonworks is looking to address in YARN, Murthy says. “We’re investing all across the stack, whether it’s HDFS or YARN to make sure that Spark is a great citizen in the ecosystem,” he says.
While Spark brings a collection of in-memory capabilities to Hadoop’s table, Hortonworks sees the most potential at this point with MLlib machine learning library. “We view it as an in-memory oriented, data-scientist sandbox for machine learning and iterative analytics. It does that use case very well,” Connolly says. “That’s kind of how we see it. That’s how our customers are engaging us.”
The Spark Streaming and Spark SQL (which is replacing Shark) are “undergoing a bit of change and maturation,” he adds. Similarly, Graphx is still fairly new and needs some bolstering. “We’re still feeling out the market on the micro-batch [i.e. streaming] to see how much interest there is. That one could be interesting. But right now most folks are looking at it as just the data scientist, in-memory oriented sandbox, if you will.”
Hortonworks does not appear to be in a huge rush to support Spark, and would prefer to take it slow and allow its beta testers–such as Yahoo, which “beats the hell” out of code on behalf of Hortonworks and the entire Hadoop community–ensure the product is ready for enterprise adoption. The company doesn’t seem particularly swayed by the surge in interest in Spark from the open source community.![]()
Hortonworks’ position is understandable. The entire Hadoop ecosystem is in the midst of a massive transition from traditional Hadoop 1.x to Hadoop version 2 and its YARN-enabled allocation of resources, and Hortonworks seems to not want to take any chance of rocking the boat.
On the other hand, there’s also the thorny prospect of competitive differentiation, and the fact that Databricks has a formal business relationship with Cloudera and does not have one with Hortonworks. Hortonworks also appears to be a little concerned about the potential for fragmentation of Spark.
Databricks is ramping up its own business and its own certification program for a community of Spark-based applications. Databricks is concerned that the Spark shipped by different Hadoop distributors could be different, and introduce incompatibilities among applications built on Spark, such as those from Alpine Data Labs, Microstrategy, and Zoomdata, three of the 10 certified Spark apps at the moment. There are a lot of moving pieces here, and getting it wrong would cost a lot more than the cost of investing in the technology to get it right the first time.
Related Items:
Yahoo: We Run the Whole Company on Hadoop
Hortonworks Spins Up a YARN Readiness Program
Databricks Moves to Standardize Apache Spark
Apache Spark: 3 Real-World Use Cases
Leading Solution Providers
















