

October 15, 2014
Hortonworks Goes Broad and Deep with HDP 2.2
From full support for Apache Spark, Apache Kafka, and the Cascading framework to updated management consoles and SQL enhancements in Hive, there’s something for everybody in Hortonworks’ latest Hadoop distribution, which was revealed today at the Strata + Hadoop World conference in New York City.
Hadoop started out with two main pieces: MapReduce and HDFS. But today’s distributions are massive vehicles that wrap up and deliver a host of sub-components, engines, and consoles that are desired and needed for running modern Hadoop applications. Ensuring that each of the pieces in the Hadoop stack works with all the others is what Hadoop distributors like Hortonworks do.
Jim Walker, director of product marketing for the Palo Alto, California company, breaks it down into vertical and horizontal approaches. “Vertically, we’re going to integrate each one of these engines…both into YARN and then deeper into HDFS,” he says. “But we’re also making sure that I’m not integrating those horizontally across the key services of governance, security and operations.”
A shiny new engine in the guise of Apache Spark is undoubtedly the highlight of Hortonworks Data Platform (HDP) version 2.2. Hortonworks had offered Spark–the in-memory processing framework that’s taken the Hadoop community by storm in 2014–as a technical preview earlier this year, but HDP customers should get better value from Spark with version 2.2. thanks to the work Hortonworks has done to integrate Spark into Hadoop.
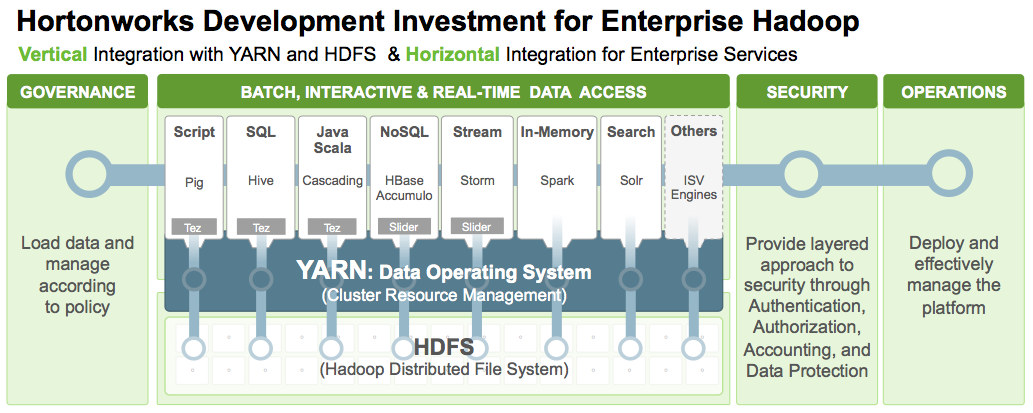 Likewise, support for the Apache Kafka messaging layer in HDP 2.2 should help Hortonworks customers add real-time data feeds for Hadoop applications. The vendor seeks Kafka–which was originally developed by LinkedIn–front-ending real-time streaming applications built in Storm and Spark. It also sees Kafka as a key player in enabling “Internet-of-Things” types of applications.
Likewise, support for the Apache Kafka messaging layer in HDP 2.2 should help Hortonworks customers add real-time data feeds for Hadoop applications. The vendor seeks Kafka–which was originally developed by LinkedIn–front-ending real-time streaming applications built in Storm and Spark. It also sees Kafka as a key player in enabling “Internet-of-Things” types of applications.
Hortonworks has been working closely with Concurrent, the company behind the Cascading framework, to integrate Cascading into Tez and YARN, two key components of the modern Hadoop 2 architecture. That work is complete and now the Cascading development framework is a first-class citizen in Hadoop 2, and fully supported in HDP 2.2. For Hortonworks customers, it means they can now write scalable Hadoop apps applications using an easy-to-use Java or Scala API, which shields them from the complexity of low-level MapReduce coding.
HDP 2.2 also brings a host of Apache Hive enhancements for running interactive SQL queries against Hadoop data, as well as the completion of the first phase of the Stinger.next initiative. While Hive .14 hasn’t been finalized yet, that’s almost certainly the nomenclature that will be carried in HDP 2.2 when the Hive community finalizes version .14.
Among the Hive enhancements are support for ACID transactions during data ingestion, which will make it easier to prepare data to be queried, Walker says. “If I’m streaming data in via Storm, I can write these things directly into Hive in real-time, so it’s instantly accessible via a SQL engine as well,” he says. “I couldn’t do that before because basically we were just kind of appending to rows. Now with support for updates and deletes and inserts, we can do these sort of workloads or accommodate these cross engine workloads in Hive.”
The version of Hive that will be in HDP 2.2 when it ships in November will also include a cost-based optimizer, which will give Hive some of the more advanced query capabilities–such as support for star schema joins and complex multi-joins–that are commonplace in established data warehousing products.
 Hortonworks is also rolling out a new release of Argus, its centralized console for establishing and enforcing security policies within a Hadoop cluster. Argus is based on the technology Hortonworks obtained (and subsequently donated to open source) in its June acquisition of XA-Secure, and is currently in the incubation stage at the Apache Software Foundation. With HDP 2.2, Hortonworks extended Argus so that it can work with the security aspects of the Spark, Storm, Hive, and HBase engines.
Hortonworks is also rolling out a new release of Argus, its centralized console for establishing and enforcing security policies within a Hadoop cluster. Argus is based on the technology Hortonworks obtained (and subsequently donated to open source) in its June acquisition of XA-Secure, and is currently in the incubation stage at the Apache Software Foundation. With HDP 2.2, Hortonworks extended Argus so that it can work with the security aspects of the Spark, Storm, Hive, and HBase engines.
There’s also work being done around Apache Ambari, the open source centralized management and control console for Hadoop. With HDP 2.2, Hortonworks is supporting the Ambari Views Framework, which allows third-parties to create custom views within the Ambari console. It also introduces Ambari Blueprints, which simplifies the process of defining a Hadoop cluster instance.
As Hadoop clusters go into production, downtime becomes a bigger issue, so Hortonworks introduced the concept of rolling upgrades with this release. The feature uses the HDFS High Availability configuration to allow users to upgrade their clusters without downtime.
HDP 2.2 marks the second major release of the product since the company unveiled its first Hadoop 2 offering a year ago. A lot of water has passed under the Hadoop bridge since then, says Walker, and the promise of Hadoop as a big data architecture keeps growing.
“It’s nothing short of astonishing how much work is going on in and around the Hadoop ecosystem,” Walker says. “We have digitized our society. We have changed the way we think. We changed the way we differentiate ourselves. And it’s all comes back to the data, to becoming a data-driven business and undertaking some sort of journey to get to that end.”
Related Items:
Hortonworks Hatches a Roadmap to Improve Apache Spark
Hortonworks Drives Stinger Home with HDP 2.1
Hortonworks Keen on Cascading-Tez Combo
Vendors:
Hortonworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States