

October 16, 2014
Hadoop ISVs Break Away from MapReduce, Embrace Spark, In-Memory Processing
Big data analytic software vendors who run on Hadoop are increasingly replacing their MapReduce engines with Apache Spark and other in-memory analytic engines as the runtime of choice. Many of these next-gen Hadoop vendors are showcasing their upgraded goods at this week’s Strata + Hadoop World conference.
One of the Hadoop vendors making the move to Spark is Platfora, which unveiled a new version of its Big Data Analytics offering during the first day of the Strata + Hadoop World show on Wednesday. Big Data Analytics is an end-to-end Hadoop application designed to enable business users to glean insights from big data sets without the assistance of a data scientist.
In earlier versions, Platfora’s software would generate batch-oriented MapReduce jobs to do the grunt work of finding patterns in the data, and used interactive SQL queries using the Hive engine for Hadoop. With Big Data Analytics version 4, Platfora will continue to use MapReduce for some data, but most processing will be transitioned to using the in-memory Spark engine.
“We’re now going to be translating all the work we do, all the data transformations and analytics, into Spark and executing that in Spark,” says Peter Schlampp, vice presidents of products for the San Francisco, California company. “We’re very excited about the fact that we’re going to now be built on Spark.”
![]()
Schlampp says Spark’s rich APIs will make it easy for Platfora customers to go beyond SQL and take advantage of advanced analytic capabilities. “A lot of the news over the past couple of years has been around how to get SQL running on Hadoop so we can connect our existing BI tools,” he tells Datanami. “This is a great example of how we need to go beyond SQL to allow different types of analytics, specifically around machine learning, predictive analytics, and graph processing–three things that you’re probably not going to be able to do very well using SQL.”
Datameer is another prominent Hadoop ISV presenting at the Strata + Hadoop World conference that has its eyes on Spark. Like other early pioneers in the Hadoop space, the San Francisco company has leveraged batch-oriented MapReduce jobs to enable customers to ingest, transform, and analyze huge amounts of data on commercial Hadoop clusters. The company enables this from its unique Workbooks interface, which allows users to work within an Excel-like environment and doesn’t require the services of a data scientist.
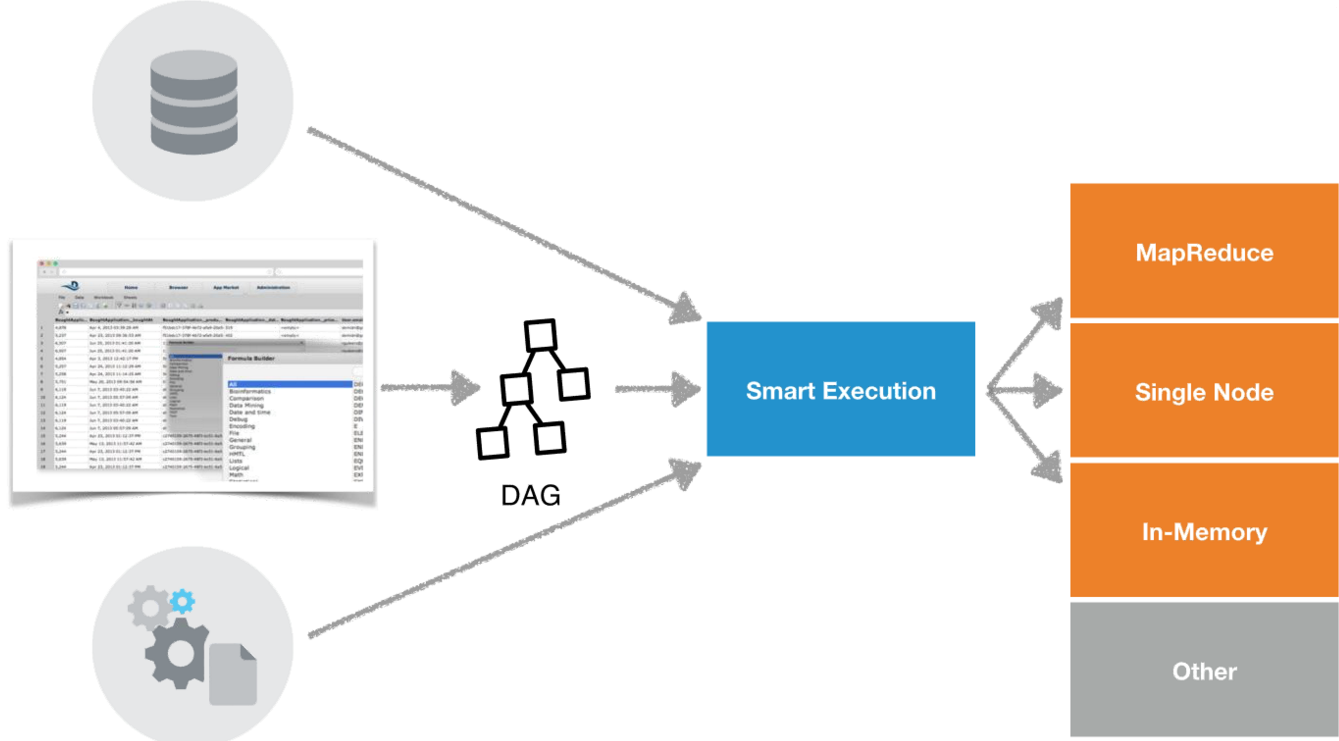
On Wednesday, Datameer unveiled version 5.0 of its eponymous product. The big news with version 5.0 is the introduction of a new in-memory data processing layer, deep support for the Apache Tez engine in Hadoop, and its Smart Execution concept.
Datameer wrote its own in-memory analytical engine to enable it to quickly process smaller data sets. This will enable users to get their answers more quickly, without waiting for long-running MapReduce jobs to give them the answers they need. The Smart Execution layer will automatically route the job to the appropriate engine, eliminating complexity for the user.
“What users need is a system that intelligently and dynamically selects and combine the different computation frameworks to execute the data pipeline,” says Matt Schumpert, director of product management for Datameer. “Today it’s a real pain for users who don’t know whether they should use Impala or Pig or Hive or Spark or Hawk or whatever the case may be. And we want to avoid that.”
![]() The smart execution layer, combined with the in-memory processing and Tez-optmized MapReduce jobs will result in a better use of Hadoop cluster resources. “The smart execution engine cobbles together,” Schumpert says. “It doesn’t just look at what the user has done, but it looks at the size of the data being processed, the size of Hadoop cluster, how much memor and CPU is viable. It cobles together a sequence of steps in the peipline, which combines optimized MapReduce through Tez, but also in-memory engine we’ve built, either distributed or on single node. So it will orchestrate multiple engines to get the job done.”
The smart execution layer, combined with the in-memory processing and Tez-optmized MapReduce jobs will result in a better use of Hadoop cluster resources. “The smart execution engine cobbles together,” Schumpert says. “It doesn’t just look at what the user has done, but it looks at the size of the data being processed, the size of Hadoop cluster, how much memor and CPU is viable. It cobles together a sequence of steps in the peipline, which combines optimized MapReduce through Tez, but also in-memory engine we’ve built, either distributed or on single node. So it will orchestrate multiple engines to get the job done.”
Datameer wrote its own in-memory processing layer instead of using Spark, but it’s a strong possibility that it will support Spark in the future. The work it’s done on Tez and the smart execution framework paves the way for using other engines, like Spark and Storm, in the future. “We believe eventually that Spark will be useful for certain use case, but primary in areas of iterative learning and stream processing,” Schumpert says. “We’ll see how things play out with the evolution and maturity of Spark.”
(ClearStory Data, one of the first Hadoop ISVs to adopt Spark due to its capability to merge and analyze multiple data sets quickly, also unveiled a new release of its core platform. We’ll cover that in a separate story.)
While vendors like Datameer, Platfora, and ClearStory are including data transformation capabilities as part of their suites, there continues to be a market for separate data transformation tools. Here, too, Spark is having an impact.
Two competitors in the data cleansing and transformation space, Paxata and Trifacta, recently moved to adopt Spark in their products. Trifacta unveiled its support for Spark last week while Paxata used the Strata + Hadoop World show as a springboard to Spark.![]()
The first generation of Paxata’s Adaptive Data Preparation product, which it launched at last year’s Strata + Hadoop World conference, helped users cleanse and transform their data using intelligent indexing, textual pattern recognition, and statistical graph analysis. However, it worked in a batch-oriented paradigm, and relied on MapReduce jobs.
With the new release, the company has moved to adopt Spark, which provides a faster, more interactive experience for the user and the capability to iterate more quickly. The company also announced that it has 150 customers. “This release underscores our commitment to innovation with our ability to address the data preparation needs of everyone in the organization, regardless of their technical skills, their analytic use cases, and the types or volumes of data they experience,” says Prakash Nanduri, co-founder and CEO of Paxata.
Trifacta, meanwhile, has also moved beyond MapReduce. Its support for an in-memory Spark engine now enables users to work and train sample data sets interactively. “It allows you to get much more interactive rates than you would normally get by pushing into a batch system like MapReduce,” Trifacta co-founder and CTO Sean Kandel says. “Also, by maintaining the data in ![]() memory, you can run lots of interactive algorithms over it, which is good for us in terms of how we do data profiling and for driving predictive interaction.”
memory, you can run lots of interactive algorithms over it, which is good for us in terms of how we do data profiling and for driving predictive interaction.”
Other vendors within the Hadoop community area also adopting Spark, including Tableau Software. Tableau this week announced that it’s released a new data connector for Spark SQL, one of the Apache Spark data engines. It also announced that is has qualified for the Spark certification program run by Databricks, the commercial entity behind the open source phenomenon.
These are not the last Hadoop ISVs you’ll see moving to Spark, which has built a tremendous amount of momentum since coming onto the scene just 18 months ago. “Spark is winning,” Platfora’s Schlampp says. “I don’t know if you’ve noticed, but there’s a huge watershed of developers that have been going from the other big data open source projects and started to develop on Spark. The number of commits to the other open source big data projects within the Hadoop ecosystem has gone down dramatically and the commits to the Spark project has shot up dramatically.”
Related Items:
Spark Smashes MapReduce in Big Data Benchmark
How Spark Drives Midsize Data Transformation for Trifacta
How Spark Helps ClearStory Achieve Data Harmony
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








{kind=link}
Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States