

September 3, 2019
Can We Stop Doing ETL Yet?

(Agor2012/Shutterstock)
Despite the advances we’ve made in data science and advanced analytics in recent years, many projects still are beholden to a technological holdover from the 1980s: extract, transform, and load, or ETL. It’s uncanny how those three letters strike fear into the hearts of data architects, but we seem powerless to move beyond it. Is there anything that can save us from the madness of ETL?
Before looking at potential successors to ETL, let’s look at the origins of the technology. As companies amassed ever-bigger amounts of transactional data in their production databases in the 1980s and 1990s, they realized they needed dedicated business intelligence (BI) systems for analysis and reporting. In many ways, BI put the “p” back into enterprise resource planning (ERP).
The data warehouse served multiple purposes. First, it provided a versatile place for joining and analyzing data from multiple sources, in addition to the core production systems. It also avoided impacting the server powering the production ERP system and its underlying relational database. Data warehouses also served as playgrounds for analysts to peruse data and try out new ideas.
Because the data for BI projects would be sourced from multiple sources — including online transactional processing (OLTP) systems, marketing and customer relationships management, or even purchased from third-party data brokers — companies needed more tailor-made database software specifically designed to handle the data types and workloads. Beginning with Arbor Software’s Essbase, a new class of multi-dimensional database emerged to power online analytical processing (OLAP) workloads.
But moving this rich OLTP and customer data into the OLAP system is not a simple task. Production databases store data in different ways, with special naming conventions for columns that must be painstakingly mapped into the data warehouse (with a notable emphasis on the “pain”). And some of the source systems weren’t even relational databases, but proprietary mainframe file systems or flat file storage approaches that upped the ante even more. And in addition to transactional data, there’s time-series and geographical data, all of which must be shaped and massaged to fit the chosen schema.

(Profit_Image/Shutterstock)
Transforming all this data into a consistent and usable format in the data warehouse remains a huge chore. Companies hire armies of specialists and consultants to write and maintain custom ETL scripts that could hammer the data into the specific schema used in their data warehouse. Whenever a source database table or file is changed, the downstream ETL scripts need tweaking to ensure the data warehouse continued to give the same result. CFOs hear the billable hours timeclock ticking in their sleep, but nobody hears their silent screams.
Beyond the maintenance nightmare of ETL, its batch nature is another big disadvantage, particularly in a world that favors the here and now. ETL jobs updating thousands or millions of tables in the data warehouse typically run at night, when production is at a lull. Other times, companies run multiple ETL jobs a day in the hopes of surfacing fresher, more profitable insights to analysts constantly hitting data warehouse with all manner of SQL queries.
Despite the time and money spent on ETL, companies still run into big problems. Elaborate processes put in place to ensure only clean and accurate data arrives through the ETL pipes fail and inaccurate and dirty data inundate the data warehouse. Many hands make quick work of big tasks, but keeping diverse stakeholders on the same page when it comes to data definitions lends itself to “multiple versions of the truth” syndrome. Data can also drift over time, skewing the results of analytical queries and making comparisons to earlier periods less accurate.
ETL is painful and expensive and prone to failure, but what can we do about it? In fact, many companies have undertaken various approaches to solving the dilemma. Here are four possible approaches to bypassing ETL.
1. Merge OLTP and OLAP
If ETL is the bane of your existence, one way you can start fixing it is by running everything on the same system. The best example of this approach is SAP‘s HANA, which began as a super-fast in-memory analytic database and has since grown to become the core transactional database for the ERP Business Suite side of the house too. The German software giant is said to run its entire business – both OTP and OLAP — on a relatively miniscule system. It doesn’t completely eliminate the need for ETL, but it minimizes the scope of what can go wrong.

Two databases merging as one (Dima Zel/Shutterstock)
Many of today’s new scale-out relational databases also advocate merging operational and analytical operations in a “translytical” approach to speed up time-to-insight. Vendors like Aersospike, MemSQL, Splice Machine, and VoltDB combine clustered architectures and in-memory processing to enable very fast SQL query processing – enough to power Web and mobile applications and real-time analysis into them (but not necessarily the core business applications like ERP).
“Traditional [ETL] processes fail to deliver real-time changes,” Forrester analysts Noel Yuhanna and Mike Gualtieri wrote back in 2015. “Translytical overcomes this challenge by delivering a real-time, trusted view of critical business data, ensuring that the source of information is accurate to guarantee consistency across the organization.”
Gartner has backed a similar approach dubbed hybrid transactional analytical, or HTAP, which accomplishes much of the same thing. NoSQL database vendor Couchbase has espoused this approach with its embedded SQL++ engine for querying JSON data, which Amazon is now doing too.
2. Give ELT a Shot
One popular twist on ETL is to switch the order of the processing. Instead of conducting the all-important data transformation in the middle of the ETL process, then do it after it has been loaded into the data warehouse – hence ELT instead of ETL. This approach is popular with more modern data lakes, where data semantics and schemas are not enforced as strictly as they are in traditional data warehouses (if they’re enforced at all).

(Image courtesy Holistics)
ELT is popular with Hadoop, where customers can stash huge amounts of raw data quickly and then run massive batch transformation jobs at a later time to prepare the data for downstream processing, including SQL analytics and machine learning.
If your data engineer is using Apache Spark to develop data transformation pipelines for downstream data science and analytic workloads, then surprise! She’s essentially writing ELT jobs, which is one of Spark’s biggest use cases. Databricks, the company behind Spark, in 2017 launched Delta, which is basically ELT and data transformation as-a-service. The ELT approach also is used with some NoSQL databases too.
3. Real-Time Streaming ETL
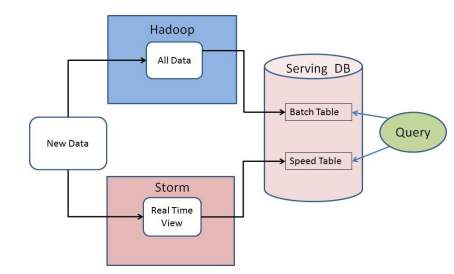
The Lambda architecture is composed of a speed layer and a batch layer
Instead of transforming data after the fact in a batch orientation, some companies have adopted streaming ETL methods, whereby data is continually processed and refined as it arrives on the wire. This approach may not work with traditional ERP-type data, but it may become absolutely necessary for getting a handle on ever-growing volumes of data from Web and mobile apps, which is basically time-series in nature.
By processing the data directly as it arrives, developers can avoid the need for a separate ETL stage to process the data. This is essentially the Lambda architecture that Apache Storm creator Nathan Marz theorized back in 2011, whereby a speed layer (Storm) processes the data quickly but perhaps not 100% accurately, while a batch layer (Hadoop) would fix any errors later.
Apache Kafka co-creator Jay Kreps had a similar solution in mind when he conceived of the Kappa architecture, a streamlined version of the Lambda that doesn’t include separate speech and batch layers. Instead Kafka plays a central role in streaming event data as it’s generated.
4. Direct Data Mapping
Another option to minimize ETL is called direct data mapping, whereby source data is queried directly where it sits instead of moving it to a data warehouse. This is the approach espoused by Incorta, which was founded several years ago by former Oracle executive Osama Elkady.
Incorta’s direct data mapping approach still requires users to move the data to a data lake, such as HDFS, S3, or Azure Data Lake, where it’s stored as a highly compressed Parquet file. But by injecting a metadata tag between the “extract” and “load” steps, it can allow customers to skip the “T” part.![]()
“Incorta simply tried to say, What happens if we just load data as is to another database that is only meant for analytics, and what if we take the data as is without having to do flattening of the data,” Elkady tells Datanami. “It takes the queries from hours to seconds.”
Incorta’s approach is promising, as the recent $30 million Series C financing round suggests. The Silicon Valley company is attracting sizable customers, including Apple, Broadcom, and Starbucks, which uses the software to accelerate its in-store sales analytics. “It can cost customers millions of dollars if they’re not able to look at the operational data in real time, whether it’s a manufacturing operation, whether it’s retail operations, or warehouse management,” Elkady says.
There’s no silver bullet for ETL, no way to entirely bypass the pain. Until we have fully converged systems that all use the same consistent data format, there will be a need to take data from one place, prep it for its destination, and then load it. But with some creativity, alternative approaches show that fresh approaches to data transformation can help to eliminate some of the pain associated with ETL.
Related Items:
Merging Batch and Stream Processing in a Post Lambda World
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States