

June 1, 2016
Merging Batch and Stream Processing in a Post Lambda World

(bluebay/Shutterstock)
It wasn’t long ago that developers looked to the Lamba architecture for hints on how to design big data applications that needed elements of both batch and streaming data. But already, the Lamba architecture is falling out of favor, especially in light of a new crop of frameworks like Apache Spark and Apache Flink that can do it all.
Nathan Marz, the creator of Apache Storm, first postulated the ideas behind the Lambda architecture in a 2011 blog post titled “How to beat the CAP theorem.” Marz postulated that one way to overcome the CAP theorem, which states that a database cannot simultaneously enforce consistency, availability, and partition tolerance, was to create a multi-layered system that processed the same incoming stream of data in different ways.
This Lambda architecture, as it would later become known, would combine a speed layer (consisting of Storm or a similar stream processing engine), a batch layer (MapReduce on Hadoop), and a server layer (Cassandra or similar NoSQL database). As data flowed into the system, it would be immediately processed by the speed layer and made available for queries by the server layer. Discrepancies in the results that arose from the speed layer (which was not intended to be 100 percent accurate) would later be ironed out by the batch processing, providing an accurate historical record.
In this manner, Lambda satisfied the data processing needs for a certain class of applications that valued high-throughput, low-latency, fault-tolerance, and data accuracy. Many organizations—in particular the big financial services companies–used Lambda as a blueprint to build big data applications that contained elements of both real-time stream processing as well as big batch jobs.
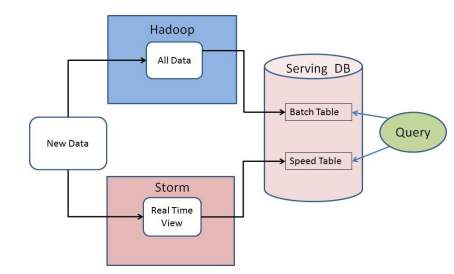
The classic Lambda architecture
Monte Zweben, CEO of Splice Machine, has been watching the big data architectural wars for some time. “The Lambda architecture was invented to be the next generation of big data,” he tells Datanami. “People have deployed it and done cool things with it. But it got too hard. It’s too complex.”
The big advantage that Lambda provided was avoidance of ETL, Zweben says. “You analyze directly on the data that’s coming from your operational environment and the IoT, because it streams right in and you didn’t have to wait for an ETL process,” he says. “But in order to do big analytics, as well as get the data immediately, you needed multiple engines, because some engines are good at analytics and some are good at operational types of workloads. The Lambda architecture deals with that by slapping together multiple engines and requiring the developer to synchronize all of that together.”
Almost before the ink dried on Marz’s theory, cracks began appearing in the Lambda architecture. While the system did work (even if it didn’t actually beat the CAP thereof), applications built on the Lambda architecture were very complex and expensive to operate and maintain. Keeping the three systems in synch was a giant headache for the developers and the administrators tasked with running them.
Enter Kappa
Jay Kreps, the co-creator of Apache Kafka and CEO of Confluent, was one of the first big data architects to espouse an alternative to the Lambda architecture, which he did with his 2014 O’Reilly story “Questioning the Lambda Architecture.” While Kreps appreciated some aspects of the Lambda architecture—in particular how it deals with reprocessing data—he stated that the downside was just too great.
“The Lambda architecture says I have to have Hadoop and I have to have Storm and I’m going to implement everything in both places and keep them in sync. “I think that’s extremely hard to do,” Kreps tells Datanami. “I think one of the biggest things hurting stream processing is the amount of complexity that you have to incur to build something. That makes it slow to build applications that way, hard to roll them out, and hard to make them reliable enough to be a key part of the business.
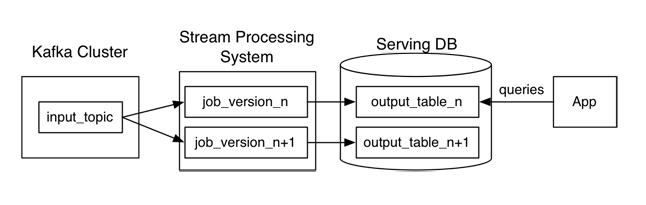
Jay Kreps’ alternative to the Lambda architecture, which he calls Kappa
In his 2014 story, Kreps proposed an alternative to the Lambda architecture, which he dubbed the Kappa architecture. Instead of maintaining two separate systems (or three, with the addition of Cassandra or similar NoSQL systems), Kreps’s alternative essentially puts all the eggs into the stream processing basket.
“Stream processing systems already have a notion of parallelism,” he wrote in his 2014 story. “Why not just handle reprocessing by increasing the parallelism and replaying history very, very fast?”
Rise of the Stream
Since Kreps wrote his story about the Kappa architecture, we’ve seen stream processing technology evolve very, very quickly. First, Apache Kafka has emerged as the defacto industry standard message bus for moving big data streams. And secondly, we’ve seen stream processing engines like Spark Streaming, Apache Flink, and Apache Beam emerge to become popular ways of acting upon fast moving streams of data.
Beyond the sheer popularity of these stream processing engines, however, what’s notable about Spark, Flink, and Beam is that developers can use the same tools and skills to develop both batch applications and real-time streaming applications. So when a developer uses one of these frameworks to develop an application that works in batch, streaming, or interactive mode, they’re basically enacting versions of the Kappa architecture that Kreps espoused back in 2014.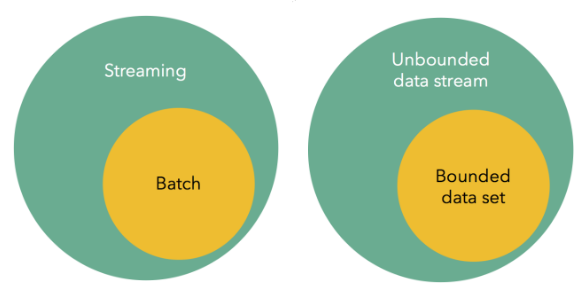
“The future generation of these other stream processing systems, I think certainly the way the Flink people are headed, I thinks that’s [the direction Spark is headed] and the Google teams working on stream processing with Beam have been taking that approach as well,” Kreps says. I think that’s actually a huge deal. It’s about the stream processing area becoming a thing in its own right that works independently, which makes it A. much more applicable to more problems and B. much easier to adopt and put it into process.”
If data Artisans CEO and Apache Flink committer Kostas Tzoumas’ September 2015 blog post, “Batch is a special case of streaming,” is any indication, then the Flink folks are certainly on board with Kreps’ Kappa architecture.
“We are not the only ones to make the point that streaming systems are reaching a point of maturity which makes older batch systems and architectures look less compelling,” Tzoumas writes. “But is batch dead already? Not quite, it’s just that streaming is a proper superset of batch, and batch can be served equally well, if not better, with a new breed of modern streaming engines.”
With the upcoming release of the Structured Streaming capability in Apache Spark 2.0, developing batch and streaming applications with the same set of tools and skills will be easier than ever.
“We’re making it very easy to have the same programming model for both,” Databricks Chief Architect Reynold Xin tells Datanami. “There’s a lot of value in the Lambda architecture in a broader sense….[but] it’s pretty annoying to have to run multiple different systems.”
Splice Machine is also keeping an eye on all the moving technological parts, which it uses for the Hadoop-resident relational database management system (RDBMs). “The secret of the Splice Machine RDMBS is we expose just a relational database to the developer that they’re used to using with all the functions they need to do the analytics and fast operational stuff,” he says. “And we also do it with dual engines. But the secret is the engines are under the covers with Splice Machine. We take care of that duct tape and glue in a really efficient way.”
As frameworks like Spark, Flink and Beam mature, it appears that Kreps’ Kappa architecture and its focus on treating everything as a stream of data, will provide the most bang for the big data developer’s buck. Considering how much simpler these approaches are compared to the Lambda architecture, it clearly is worth considering for future big data projects.
“The future is certainly going to be stream processing that stands and work on their own, with any kind of batch processing in the back being an optional thing you may or may not add on,” Kreps says. “I’m 100 percent convinced that as those limits fall away in the stream processing that things that want to operate in real time will be able to build against the stream processing system on its own and not need to incur that complexity.”
Related Items:
The Real-Time Rise of Apache Kafka
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
Apache Flink Creators Get $6M to Simplify Stream Processing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States