

September 20, 2018
Couchbase to Deliver Parallel JSON Analytics — Without the ETL

(Graf Vishenka/Shutterstock)
Couchbase yesterday unveiled a JSON-native analytics engine it claims will let users perform parallel ad-hoc analytics on operational data just milliseconds after it’s landed in the NoSQL store. The Analytics Service, which is based in part on the Apache AsterixDB and SQL++ projects from academia, has been dubbed “NoETL,” but don’t let the catchy phrase fool you.
The new Analytics Service is the cornerstone of Couchbase Server 6.0, which the company launched yesterday at its Couchbase Connect SV conference at the San Jose-McEnery Convention Center, and which is slated for delivery in October. The company dedicated a significant portion of the one-day show to explaining how it built the new analytics engine, what impact it will have on customers, and running a real-time demo where it spun up an analytics cluster in less than five clicks.
For many businesses, analytics is heavily dependent on the extract, transform, and load (ETL) process, whereby data is lifted out of a production system and shunted over to a data warehouse. But ETL processes can take months to define, are susceptible to shifting schemas, and typically require flattening of the rich hierarchical data structures that exist within JSON documents.
Numerous methods have been devised to bypass ETL, including the Lambda architecture, where data streams are split into separate pipelines and landed in various optimized stores for operational or analytics use case. Another technique, dubbed hybrid transactional analytical processing (HTAP), has been put forth by the smart folks at Gartner as a more efficient way to analyze data as it sits in production systems, usually scale-out relational databases. (Increasingly, real-time stream processing systems, in-memory databases, and even in-memory data grids are being called on to solve the same elemental problem, but that’s another story.)

Couchbase CTO Ravi Mayuram and UCI professor Mike Carey on stage at Connect SV September 19, 2018
Couchbase’s new Analytics Service takes a page out of Gartner’s HTAP playbook, but with substantial caveats, including provisions to maintain the rich JSON data structures that customers rely upon to serve their operational computing needs. The company began researching what a native-NoSQL HTAP system would look like four years ago, when Couchbase CTO Ravi Mayuram reached out to University of California Irvine computer science professor Mike Carey about a project he was working on called AsterixDB, which Carey started about 10 years ago in response to the seismic architectural shift that was occurring.
“There was an elephant in the room, Hadoop, which was starting to happen,” Carey told Mayuram on stage at Couchbase Connect SV. “Clearly the data was a mess. It was a much more complicated that rows and columns. And databases were kind of being forgotten. So people were kind of reinventing that technology without being aware of it. Those of us who were SoCal database people said, this is not the right way to go. Let’s build a parallel database for that kind of flexible data, and that was the Asterix project.”
Couchbase worked with Carey as an advisor, and used the open source AsterixDB as the foundational technology for the new database engine component of the Analytics Service that has been in beta for the past six months (and which will not be open source). There was a considerable amount of work that went into pairing the new database engine to work with the Couchbase database. Much of the work involved adapting Couchbase’s Data Change Protocol (DCP), which is basically stream protocol that provides very fast memory-to-memory replication of data sitting in the NoSQL engine, to work with the AsterixDB-based technology that would become Analytics Service.
“There were two big technical problems,” Cary said. “One is you were doing a lot of transactions on front end, gathering a lot of data that had get swallowed into the system where you could ask the big questions without perturbing the front end. So it was a data ingestion issue there. We had to look at how could get the data in so that it moved quickly, and how do it we get it at rest quickly so that you can query it.”
The solution hinged on the “data feeds” technology that Carey and his UCI researchers developed for AsterixDB, which Couchbase utilized as the basis for the log-structured merge trees, or LSM-trees, that do the work to land the data on the separate Analytics Service nodes in a way that makes them query-able.
Next, the company needed a query language to pair with the database engine and the table-like views of JSON data materialized by the in-memory LSM-tree algorithms. The company already had N1QL, which is very similar to SQL and provides some analytic capabilities for native JSON data. But N1QL had some shortcomings that made it a poor fit for the new service – namely, it did not run in a massively parallel fashion to leverage Couchbase’s shared-nothing distributed architecture. And N1QL needed data to be pre-organized with indexes, which eliminated analyst’s ability to run ad-hoc queries to explore the data.

The phrase “NoETL” was first coined by Alexy Khrabrov, according to Wikipedia, and is currently the subject of a trademark application by By the Bay LLC (Image source: OpturaDesign/Shutterstock)
This is where Couchbase dipped into the academic waters a second time, and it pulled out a technology called SQL++, which is a declarative query language for JSON data that’s backwards compatible with the ANSI SQL standard. SQL++ is the subject of an ongoing research project at University of California, San Diego under computer science and engineering professor Yannis Papakonstantinou, which has been funded in part by a grant from Couchbase.
There was more work in getting SQL++ to work with Couchbase before it delivered it as the first commercially supported implementation of SQL++, which the comapny is doing with N1QL for Analytics, which utilizes SQL++ under the covers. “We had to optimize it, number one to understand DCP, then bring it into the Couchbase domain,” Sachin Smotra, director product management at Couchbase, told Datanami. SQL co-creator Don Chamberlin, who is an advisor to Couchbase and appeared on stage yesterday, has been involved with SQL++ and also helped the company with the implementation.
The fourth piece of the puzzle revolved around maintaining isolation from the transactional side of the Couchbase cluster. The company did some work to ensure that customers would not be subject to the “noisy neighbor” problem, whereby big SQL++ queries (via NiQL for Analytics) begin to consume resources and impact performance of the transactional cluster. The company, which recently introduced a Kubernetes operator, says customers can get separation either with dedicated hardware or containerized workloads.
When you put all this together, you get Analytics Service, which is the fourth fifth optional component in the NoSQL data platform, along with mobile, eventing, and N1QL query. During a demo on stage, Smotra and Mayuram went through the process of “re-balancing” data from the production Couchbase cluster into an Analytics Service (in only four clicks) and then running a series of queries to discover what was occurring with hypothetical IoT data set from a connected car system. There were anomalies detected in tire pressure monitoring system (TPMS) systems, and the Couchbase execs demonstrated how quickly customers could ask questions of the data, visualize the results (through a Knowi layer), and then run new queries based on the results (such as determining if there were patterns in the data, like specific models or years exhibiting the same TPMS anomalies). Such free-ranging inspection of the data comes intuitively for humans, but it’s actually a really challenging technical thing to pull off with machines that haven’t organized the data that way.
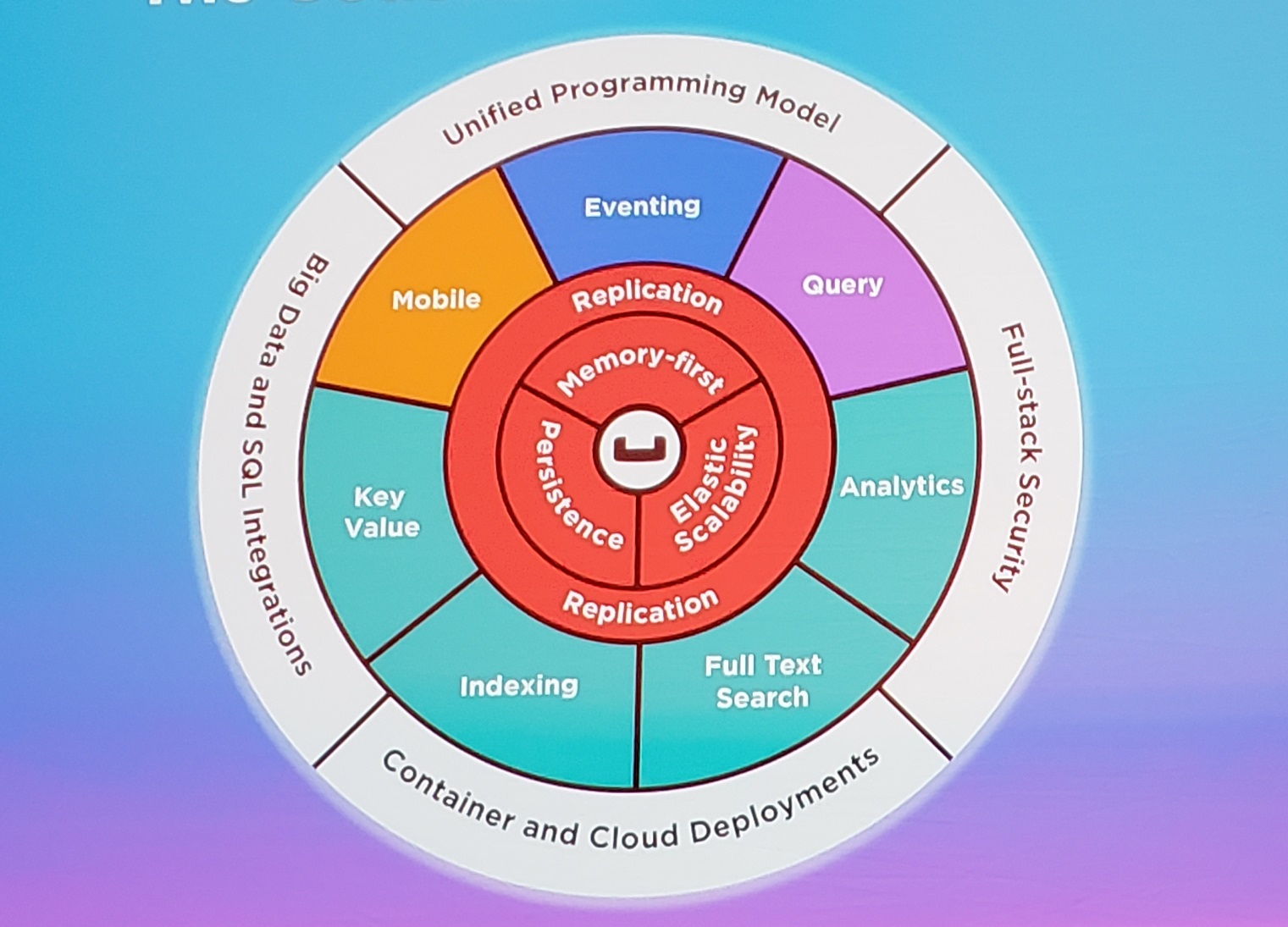
The delivery of Analytics Services with Couchbase Server 6.0 will be the third major feature delivered in 12 months, following eventing and mobile, according to Couchbase’s SVP of products Scott Anderson
One early Analytics Service adopter that’s impressed so far is Steven Wyant, the data architect for the Cincinnati Reds, which started using a beta copy of the service about six months ago when the Reds started their baseball season. “I didn’t necessarily know what we were going to use Couchbase for off the bat,” Wyant told Datanami. “We had a bunch of things we wanted to look at.”
The Couchbase Analytics Service allowed the Reds organization to track what tickets people bought and where they actually sat within the 42,000-seat Great American Ballpark for (almost) an entire season, which delivered better in-game understanding of what’s happening during games, as well as better insight into potential price changes for 2019. “The [Analytics Service] allows for that in a quicker manner than N1QL, where you have to kind of know operationally what you’re after,” said Wyant, who previously helped Kroger build a Hadoop cluster for Hive analysis. “That’s really why we brought it in, to look at that in a more digestible and more interactive manner than what we can do in our current infrastructure.”
In the end, Couchbase pulled off its NoETL pledge in the demo, which was impressive. But equally remarkable is how it enabled analytics on JSON data via SQL++, without modifying it. That could appeal to a lot of Couchbase customers, who today must build and maintain ETL pipelines that flatten the JSON. “This is a really significant problem to solve,” says Scott Anderson, Couchbase’s senior vice president of product management. “You have this incredibly rich data structure, nested objects and so forth. How do you derive the intelligence beyond what we do with NIQL and how do we extend the capacity, and then solve some of the problems that Ravi talked about, which is the fragility of the pipeline?”
Couchbase executives fretted that they had hid too much of the complexity that went into Analytics Service and made it seem too simple in the demo. That led Mayuram to warn the attendees: “Don’t try this at home. Don’t think that you can solve this problem by hodge podging three different open source projects together. That’s not the case here….This is some serious stuff that we’ve built here.”
Related Items:
Couchbase’s Engaging Plan for Customer Victory
The New Math Driving NoSQL Analytics
New CEO, Same Strategy for Couchbase
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States