

July 5, 2022
Databricks Claims 30x Advantage in the Lakehouse, But Does It Hold Water?
Databricks CEO Ali Ghodsi at Data + AI Summit 2022 on June 28, 2022
Databricks CEO Ali Ghodsi turned some heads last week with a bold claim: Customers can get 30x price-performance advantage over Snowflake when running SQL queries in a lakehouse setup. However, Snowflake waved off the statement, claiming the comparison was all wet.
Databricks’ claim is based on an unpublished TPC-DS benchmark that it ran on its own data analytics offering as well as those of competitors. Ghodsi publicly shared the results for the first time during a press conference last week before detailing the results in his keynote address at the Data + AI Summit, which took place last week in San Francisco.
Databricks says the results show the relative costs to run the TPC-DS 3TB benchmark on different cloud data warehouses and lakehouses using external Parquet tables.
Information provided by Databricks shows the job cost $8 to run on “SQL L w/ table stats,” which the company said refers to its “large warehouse” offering using table stats. That means that Databricks “ran the analyze table statement to allow the query optimizer to find a more effective query plan,” Databricks’ Joel Minnick, vice president of marketing, told Datanami via email. Without the table stats provided by the query optimizer, the cost for the job went up to $18.67.
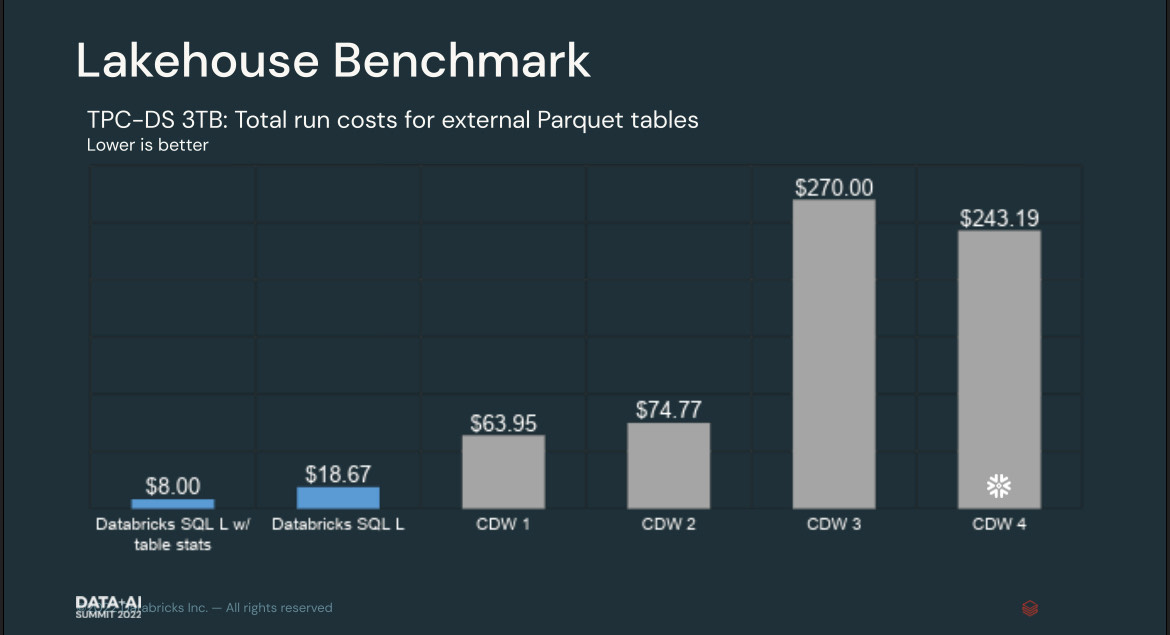
Databricks says the lakehouse benchmark it ran shows a large price-performance advantage over its competitors (Image source: Databricks)
When the same job was run on other cloud data warehouses, the cost increased to $63.95, $74.77, $270, and $243.19. The first three “CDWs” presumably refer to the three public cloud vendors—AWS, Google Cloud, and Microsoft Azure (we have no idea which ones are which). The graphic for CDW 4, however, bore Snowflake‘s logo.
It’s important to note that Databricks ran the queries as if the other cloud offerings were lakehouses. That means the data analyzed was contained in Parquet tables stored on a cloud object system. Querying data from Parquet files stored in object storage essentially eliminates the advantage that cloud data warehouses can get by loading the data into the unique format used by columnar analytic databases, which are at the heart of cloud data warehouses.
Databricks ran the test for a couple of reasons. First, it did it to show off the work it has done in Delta Lake, which blends elements of data warehouses and data lakes, as well as its Photon engine, the C++ rewrite of Spark SQL, which also became generally available at the show. Secondly, Databricks has become a little miffed that its competitors have started calling themselves lakehouses, which the company’s leadership says waters down the meaning of the term.
“If you look at all the big cloud vendors, they’re all talking about lakehouses,” Ghodsi said during a press conference last week. “They claim they are lakehouses. So we’ll use you as a lakehouse, which means we are not going to copy the data inside of these systems. We’re going to store it on the lake, because that’s where lakehouses are, and we’ll access it from there.”
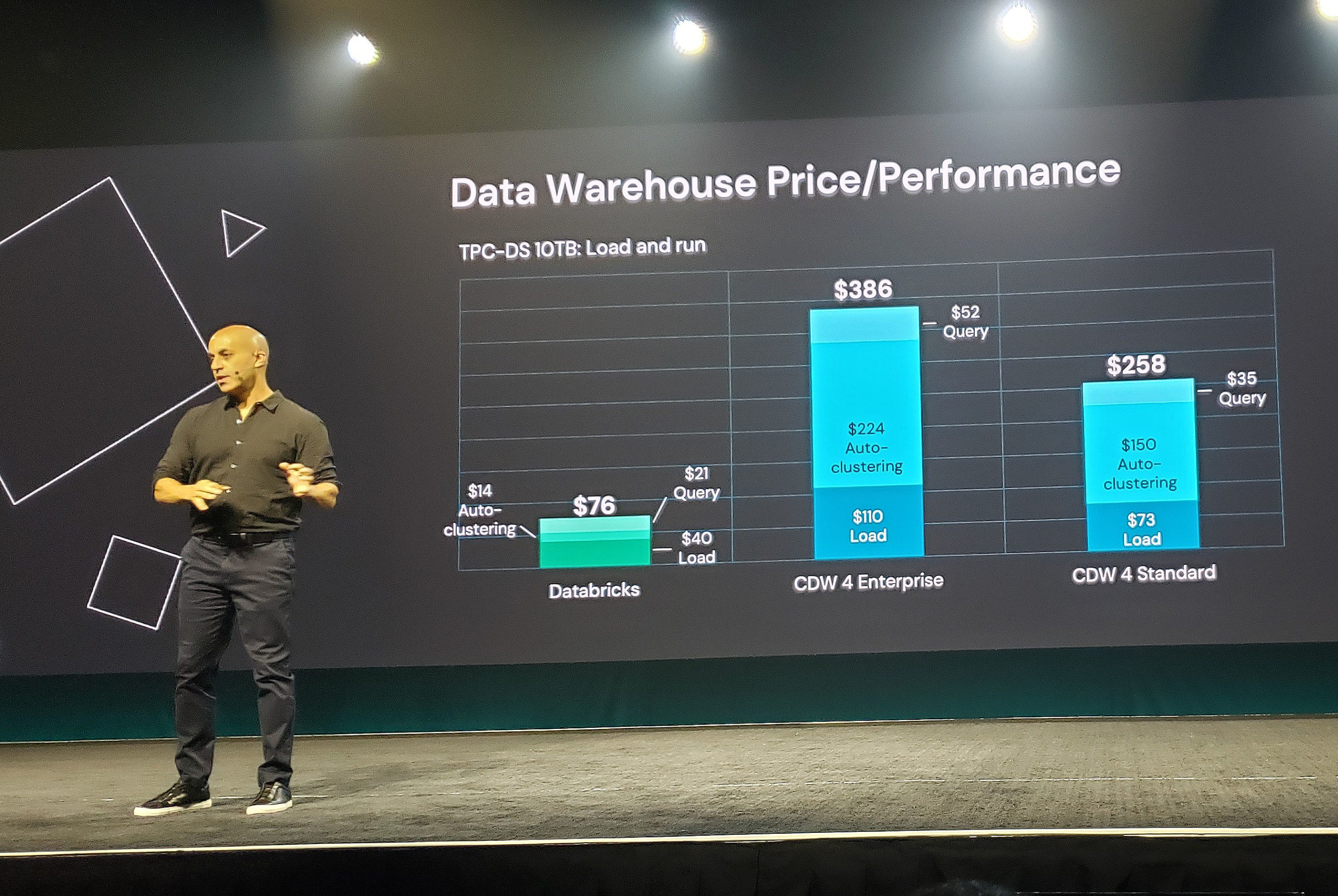
Databricks shared information from a second benchmark that measured the cost of loading and running the TPC-DS 10TB test, which provided more of a fair comparison from the cloud data warehouse vendors’ points of view, according to Ghodsi.
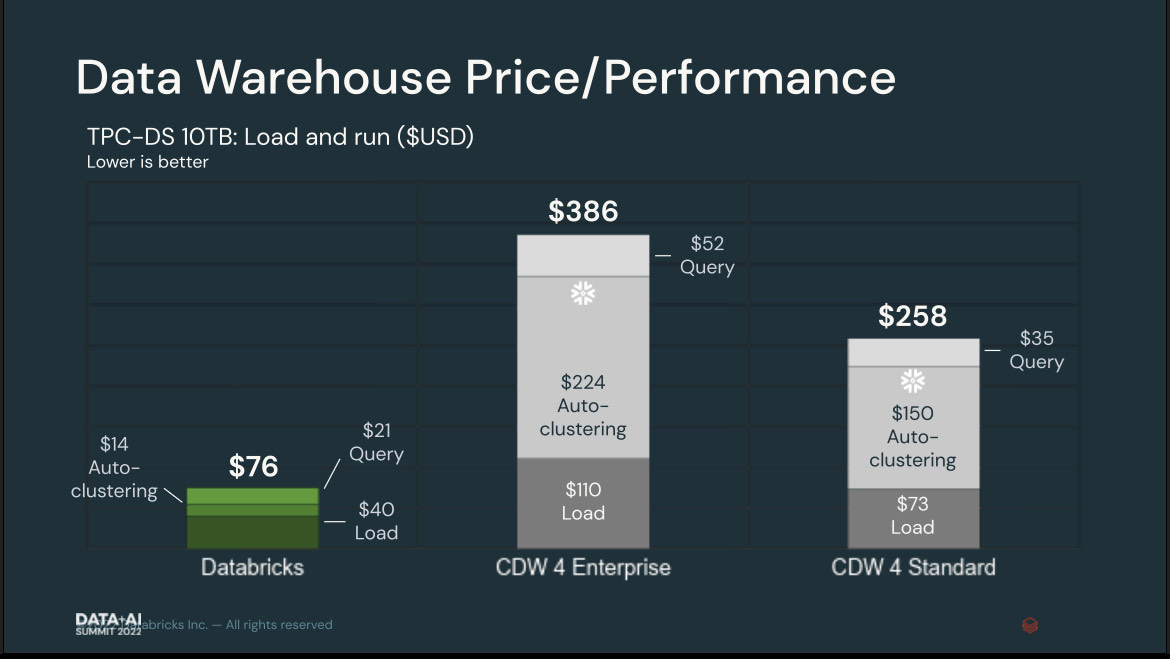
Databricks says it still had price performance advantages even when using its competitor’s data warehouse as designed (Image source: Databricks)
Databricks charged $76 to load, auto-cluster, and query the data, while Snowflake charged $386 in the enterprise version and $258 in the standard version, representing a 5.1x and 3.4x advantage for Databricks, the company’s data showed.
A lot of the additional work measured by the benchmark in the other four cloud data warehouses was in loading the data into the warehouse, according to Ghodsi. The benchmark also computed how much it cost to optimize the tables. “That turns out to be a significant cost,” he said.
Some of these costs can be avoided in the lakehouse, Ghodsi said. “Using the lakehouse, if you already have your data on a lake, you don’t need to do the load portion,” he said.
Snowflake refused to be drawn in, stating that it was focused on serving customer needs, which includes delivering better price-performance.
“We are focused on innovating and delivering value for our customers,” Snowflake SVP of Product Christian Kleinerman told Datanami. “Our price performance is a key reason that our customers are migrating more and more workloads to Snowflake, inclusive of Spark workloads. We are continuously delivering new performance enhancements to make real customer workloads run faster.
“We also believe in passing on the associated economic savings to our customers, which compounds the price/performance benefits for them,” he continued. “We encourage anyone interested in the comparison to do their own assessment. We will continue to stay focused on customer outcomes.”
Smack-talking is a time-honored tradition when it comes to hardware and software companies, and it would appear that Databricks is now doing its part to uphold the tradition with the company that has become its closest competitor.
Related Items:
Cloudera Picks Iceberg, Touts 10x Boost in Impala
Why the Open Sourcing of Databricks Delta Lake Table Format Is a Big Deal
All Eyes on Snowflake and Databricks in 2022
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States