

July 1, 2022
Cloudera Picks Iceberg, Touts 10x Boost in Impala

(vladwel/Shutterstock)
Cloudera is now supporting the open source Apache Iceberg table format in its cloud data platform, or lakehouse, the vendor announced yesterday. The move will help to ensure transactional integrity in the big data environments of Cloudera customers, while giving Impala queries a 10x performance boost. It will also give the Iceberg project more momentum to become the center of the open data ecosystem.
Apache Iceberg emerged several years ago to address data engineering issues afflicting users of the Apache Hive metastore, which continued to be used to manage data access and control in complex HDFS and S3 environments even as use of Hive’s SQL engine waned as faster query engines emerged.
Data engineers at Netflix and Apple were frustrated with several issues with the Hive metastore, starting with the lack of transactional integrity, which could wreak havoc in busy big data environments, where multiple teams accessed data with a variety of engines and services, including Presto, Dremio, Trino, Apache Spark, and Apache Flink, among others.
Without support for atomic transactions, customers could get the wrong answers when querying their Parquet tables, unless extreme pains are taken to ensure data consistency. “Quite simply, tables shouldn’t lie to you when you query them,” Iceberg creator and PMC Chair Ryan Blue, formerly of Netflix (and a Datanami 2022 Person to Watch), said at a Dremio conference in 2021.
Iceberg addressed other issues with Hive too, including providing finer-grained file operations for data stored in object stores and support for in-place table evolution. The table format has been adopted by several big cloud vendors, including AWS and Snowflake, both of which announced support for Iceberg earlier this year.
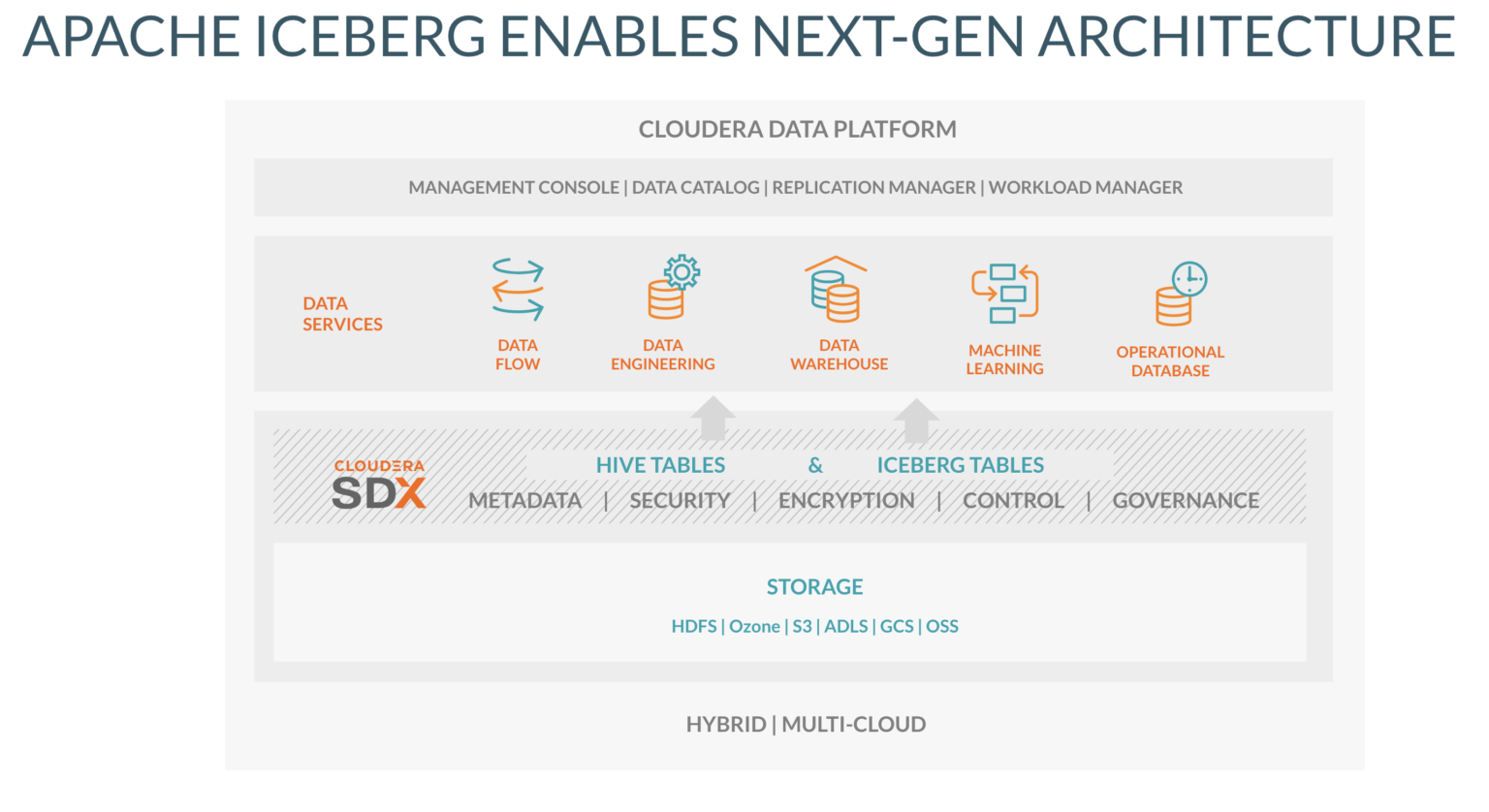
Cloudera is supporting the Iceberg table format across its Cloudera Data Platform (Image source: Cloudera)
Now Cloudera is throwing its weight behind Iceberg too. The once high-flying Hadoop distributor has been trying to re-invent itself as a cloud data platform provider, and this week’s announcement of support for Iceberg within key components of its Cloudera Data Platform (CDP) should bolster Cloudera’s claims of supporting an open data ecosystem, which it has taken to calling a lakehouse.
“Over the past decade, Cloudera has enabled multi-function analytics on data lakes through the introduction of the Hive table format and Hive ACID,” Cloudera employees Bill Zhang and Shaun Ahmadian wrote in a blog post yesterday.
“The lakehouse pattern has evolved to the cloud,” they continued. “However, it still remains driven by table formats that are tied to primary engines, and oftentimes single vendors. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the data lake, without vendor lock-in. Organizations want modern data architectures that evolve at the speed of their business and we are happy to support them with the first open data lakehouse.”
Specifically, Cloudera is supporting the Iceberg table format in its data warehouse, data engineering, and machine learning offerings, which are available on all three major clouds as well as an on-prem offering. The implementation of Iceberg into CDP, which supports HDFS, S3, Azure Data Lake Storage, Google Cloud Storage, and open source storage options, was relatively straightforward, the Cloudera employees wrote.
“In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework,” they wrote. “By leveraging SDX and its native metastore, a small footprint of catalog information is registered to identify the Iceberg tables, and by keeping the interaction lightweight allows scaling to large tables without incurring the usual overhead of metadata storage and querying.”
While much work had been done by the open source community to enable Iceberg to work with Spark, the integration with Impala and Hive (for writes; Hive reads were already supported) was lacking. “So Cloudera contributed this work back into the community,” the authors wrote.![]()
Thanks to Iceberg’s more aggressive partitioning scheme, queries on Iceberg tables by Impala performed 10x better than the previously used Hive external tables using Impala queries, according to Cloudera.
“Previously this aggressive partitioning strategy was not possible with metastore tables because the high number of partitions would make the compilation of any query against these tables prohibitively slow,” the Cloudera authors wrote. “A perfect example of why Iceberg shines at such large scales.”
But Iceberg isn’t the only game in town when it comes to open table formats in support of the lakehouse. Databricks, which held its Data + AI Summit this week in San Francisco, this week announced that it would make its Delta Lake table format entirely open with the launch of Delta Lake 2.0. Previously, only the API and several other elements were open, but Databricks has committed to making it all open.
The big data market thrives on competition, and with Iceberg and Delta Lake providing competing visions of what an open table format can and should be, the market will get what it wants.
Related Items:
Why the Open Sourcing of Databricks Delta Lake Table Format Is a Big Deal
Snowflake, AWS Warm Up to Apache Iceberg
Apache Iceberg: The Hub of an Emerging Data Service Ecosystem?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States