

Tag: benchmark
Pandas on GPU Runs 150x Faster, Nvidia Says
Data scientists and others who work in pandas may be interested to hear about a new release of Nvidia’s RAPIDS cuDF framework that it says results in a 150x performance boost for pandas running atop a GPU. Pandas is Read more…

Microsoft Benchmarks Distributed PostgreSQL DBs
Which distributed PostgreSQL database is tops when it comes to transaction processing throughput? It’s a good question, and Microsoft attempted to find answers when it commissioned GigaOM to benchmark its Azure Cosmos Read more…

Fivetran Benchmarks Five Cloud Data Warehouses
ETL software maker Fivetran this week released results of a benchmark test it ran comparing the cost and performance of five cloud data warehouses, including BigQuery, Databricks, Redshift, Snowflake, and Synapse. The bi Read more…

Stanford Researchers Develop HELM Benchmark for Language Models
Foundation models like GPT-3, BLOOM, and BERT have garnered much attention as of late, for good reason. These versatile models, often trained with a vast amount of unstructured data, have immense capabilities that can be Read more…
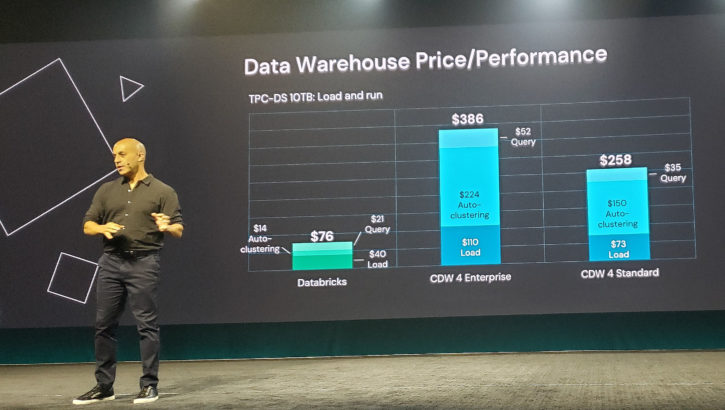
Databricks Claims 30x Advantage in the Lakehouse, But Does It Hold Water?
Databricks CEO Ali Ghodsi turned some heads last week with a bold claim: Customers can get 30x price-performance advantage over Snowflake when running SQL queries in a lakehouse setup. However, Snowflake waved off the st Read more…

Nvidia Destroys TPCx-BB Benchmark with GPUs
Editor's note: TPC announced on January 27, 2021, that the benchmark tests claimed by Nvidia, as described in this story, are a violation of its fair use policy. Traditionally, vendors have used CPU-based systems fo Read more…

Can On-Prem S3 Compete with HDFS for Analytic Workloads?
In the battle for big data storage supremacy, Hadoop is still in the running. It may no longer be the 800-lb gorilla, but the demonstrated scalability of the Hadoop Distributed File System (HDFS) makes it a potent conten Read more…

Benchmarking NoSQL Databases
Developers have a large number of databases to choose from today, particularly when it comes to newer NoSQL databases. Figuring out which databases excel in different areas can be tough, but the folks at Altoros aimed to Read more…

Graph Query Engine Claims Record
Cambridge Semantics, the graph-based provider of analytics and data management services, claimed a benchmark record this week for database query performance running on a public cloud platform. The Boston-based analyti Read more…

Big Performance Gains Seen Across SQL-on-Hadoop Engines
You can't really go wrong these days when it comes to picking a SQL-on-Hadoop engine. As long as you stick to the mainstream open source products like Hive, Impala, Spark SQL, and Presto, your SQL queries are likely runn Read more…

Big Data Benchmark Gauges Hadoop Platforms
In another indication of a maturing technology and growing demand, an industry group has released a big data analytics benchmark designed to gauge the performance of Hadoop-based systems. The Transaction Processing Pe Read more…

Spark Takes On Dataflow in Benchmark Test
Google Cloud Dataflow crunched data two to five times faster than Apache Spark in a benchmark test of batch analytics performed by Mammoth Data. While Dataflow's raw power is impressive, don't throw in the towel on Spark Read more…
New TPC Benchmark Puts an End to Tall SQL-on-Hadoop Tales
You take certain things for granted in the big data world. Data will continue to grow at a geometric rate. Amazing new technologies will regularly appear out of nowhere. And software vendors will squabble endlessly over Read more…

Does InfiniBand Have a Future on Hadoop?
Hadoop was created to run on cheap commodity computers connected by slow Ethernet networks. But as Hadoop clusters get bigger and organizations press the upper limits of performance, they're finding that specialized gear Read more…
Spark Smashes MapReduce in Big Data Benchmark
Databricks today released benchmark results for Apache Spark running the Sort Benchmark, a competition for measuring the sorting performance of large clusters. Spark running on Hadoop sorted 100 TB of data in 23 minutes, Read more…
TPC Crafts More Rigorous Hadoop Benchmark From TeraSort Test
While Moore's Law has made computing and storage capacity less expensive with each passing year, the amount of data that companies are storing and the number and sophistication of the algorithms that they want to employ Read more…
Live from SC11: Data Intensive System Showdown
The results of a relatively new benchmark that falls under the purview of the Graph500 effort were announced at the annual Supercomputing conference in Seattle, showcasing the prowess of IBM and others in tackling data-intensive problems. Read more…
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States