

May 13, 2021
ChaosSearch Widens the Zone for Data Lake Analytics

(ramcreations/Shutterstock)
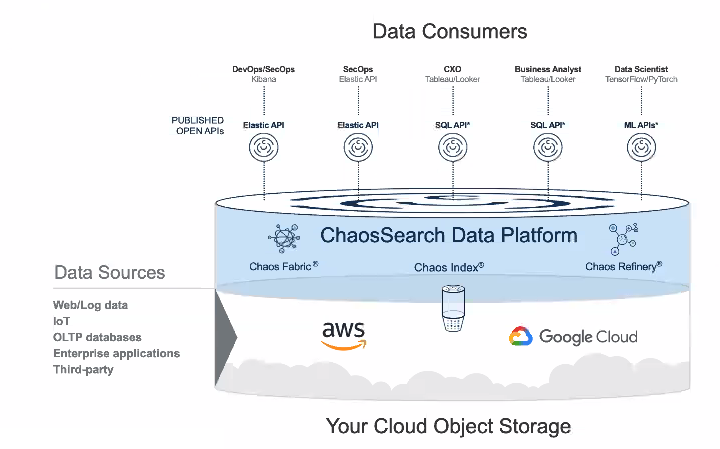
When ChaosSearch emerged from stealth last year, its mantra was all about enabling customers to run log analytics on massive amounts of data in Amazon S3 using familiar tools, like Kibana. With today’s update, the company is not only supporting Google Cloud’s data lake, but it’s adding support for SQL analysis using familiar BI tools, like Looker and PowerBI.
In the ongoing war between data lake and data warehouses, ChaosSearch comes down squarely on the side of data lakes. Instead of building endless ETL pipelines to transform data to meet every user’s particular needs, ChaosSearch advocates leaving all the data in the data lake, where it can apply patented indexing technology to make the S3 data appear as if it’s in a relational database, and then expose that data to open APIs (like Elastic, and now Presto) to let users access it.
“We’re delivering on the true promise of data lakes, which is largely delivered,” says Ed Walsh, who joined the company as its CEO in the summer of 2020. “The idea is to put things in a data lake. Don’t take time to structure it. Just land it there, and we’ll show you how to get insights out of it.”
As we wrote last year, ChaosSearch’s co-founder and CTO, the computer scientist Thomas Hazel, initially developed the product with a SQL API in mind. The idea was to enable companies to use traditional BI tools to access S3-resident data using the Presto API. But enormous demand for scalable log analytics right off the bat changed his plans, and the company came to market with what is effectively a clone of ElasticSearch that runs at scale on data in S3 (scaling Elastic is notoriously difficult).
Source: ChaosSearch
According to Walsh, business has been brisk. The Boston-based company, which raised $40 million in venture funding in December, now has over 50 customers now, including bigger companies like Blackboard, Equifax, and Armor. “We have multiple clients with multiple use cases, each over a petabyte,” Walsh says. “So the technology is really scaling, and scaling well in production.”
Today ChaosSearch announced support for SQL in its data lake platform. So in addition to letting users treat the data lake platform like Elastic and slice and dice machine data using tools like Kibana, it’s now allowing users to treat it like Presto and slice and dice the data using tools like Tableau, Looker, and PowerBI.
According to Walsh, having a multi-modal data lakes enables customers to offer different analytics experiences and use cases to different users.
“We have a data lake platform that allows you to do a lot of use cases, at scale,” he says. “What are the right use cases? Logs? No brainer…You can also use SQL on the same log data for a different user set. You can also do machine learning on logs.”
ChaosSearch will officially support machine learning on machine-generated data at some point later this year. It also will add support for Microsoft Azure, likely in 2022, giving the company full coverage of the three big public clouds, whose data lakes are growing very quickly at the moment.
Support for the Presto API will allow ChaosSearch users to get up and running with traditional BI use cases, and thereby avoid the “big bang theory” that is common in data warehousing projects, Walsh says.
“In a normal scenario, you have different data views for a client, then you’ve got to get a data scientist, get a pipeline,” he says. “It ends up for enterprises to be three weeks to three months, what we’re able to do without these skills in under five minutes.”

SQL remains the lingua franca of business analytics (Wright-Studio/Shutterstock)
The secret sauce that enables that turnaround is the patented indexing and data fabric technology developed by Hazel. As data arrives in S3, it’s run through the ChaosEngine Index, which shrinks it by over 10x. The offering also includes a data fabric (running atop an Akka message bus written in Scala) that mediates between the GETS and PUTS that S3 (and other data lakes) understand and the Elastic or Presto SQL APIs (support for Python, R, and Tensorflow APIs, as well as REST endpoints, is due next).
“Our platform indexes your cloud data, in your environment, in place,” Hazel says. “We fully index it and publish an open API. You can search it through an Elasticsearch type API but also do SQL type use cases. It’s really a data lake philosophy–that comes out pretty strongly.”
In many ways, ChaosSearch is the anti-ETL product. Instead of changing data and optimizing it for analyses in certain tools, the company advocates keeping the raw data as is, in one place. That not only eliminates governance issues that arise when data is moved and changed, but it enables users to bring new type of analyses later on.
“The issue is you don’t know what the VP or his or her team wants to ask the data, so you’ve got to keep it all,” Walsh says. “Let’s keep the machine generated data in its natural state. It’s easy to land there. Don’t do a massive ETL that, at this scale, is near impossible. But also don’t throw out data you don’t know what you’re going to ask it.”
This won’t work in all instances. Even Walsh, a former IBMer, admits that data warehouses still have their place. And through its Chaos Refinery, ChaosSearch will allow customers to do data transformations (although the transformations are basically filters on the data, and the changes aren’t ever written back to the data lake). In the current battle, data lakes have advantages in the areas of scale, cost, and data unification. But for production analytics environments that demand high query volumes and sub-second latency on queries, data warehouses still have an edge.
But for many use cases, data lakes are clearly the better option. If you’re sitting on huge amounts of machine-generated data and are tantalized by the prospect of letting employees use something like Elasticsearch or Presto to get useful information out of it, then Walsh would like a word with you.
“What we’re doing is solving the promise of data lakes,” he says. “You put it there. And I’m going to light it up and let you get after it with your tools.”
Related Items:
Rethinking Log Analytics at Cloud Scale
Cloud Data Warehouses and Cloud Data Lakes: There’s No Need to Choose
Applications:
Enterprise Analytics
Tags:
business intelligence, data lake, Ed Walsh, elastic, elasticsearch, Kibana, log analytics, presto, s3, sql
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States