

August 19, 2020
Rethinking Log Analytics at Cloud Scale

(Mmaxer/Shutterstock)
Log analytics is soaring in popularity, and Elasticsearch has captured a lot of that growth. But running a performant Elasticsearch cluster at scale is notoriously difficult. Now a company called ChaosSearch is touting a unique approach to the scalability problem, which uses indexing and query optimization to effectively turn S3 into database that can feed huge amounts of data to upstream systems at a fraction of the cost.
“The joke is, you turn on your Kubernetes cluster, and your Elastic cluster falls down,” Grafana Labs CEO Raj Dutt told Datanami recently.
But it’s no joke to many companies that are struggling to effectively scale their log analytic systems to handle rapidly growing machine data flowing from increasingly complex IT stacks.
Thomas Hazel, the CTO and founder of ChaosSearch, became aware of the Elastic problem tangentially. After spending years developing his patented distributed database technology that makes S3 look and feel like a database, Hazel’s first instinct was to target his software at the business intelligence community with support for SQL and Presto APIs.
“Two years ago, we were going after SQL first, to be frank,” Hazel said. “But so many people asked ‘Can you support text search?’ The pain was so prevalent with the Lucene-Elastic cost complexity metric. When you’re dealing with tens of terabytes per day, logs get big, and real quick.”
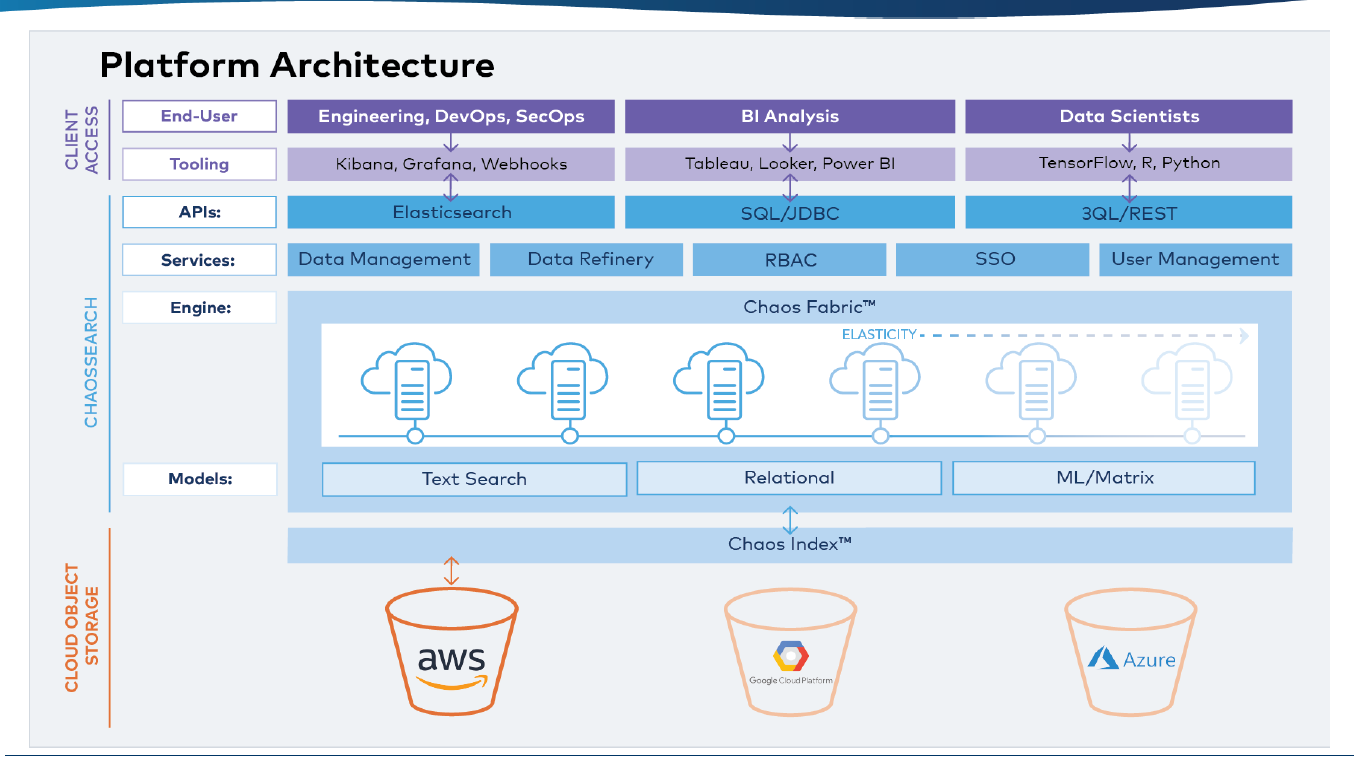
The ChaosSource architecture (Source: ChaosSearch)
It didn’t take much prodding for Hazel to shift gears and target Elasticsearch, which is based on Lucene and scales out horizontally by sharding data across nodes. To maintain good query performance, Elastic customers will often resort to caching data and using fast SSDs. But as data grows, the Elasticsearch indexes often get so big that customers are forced to limit their data retention to a certain period, such as 60 days.
ChaosSearch addresses that problem with its technology, which has two main components: an index and a data fabric. When incoming machine data arrives, it’s indexed and stored in S3, which has practically unlimited scalability and cost efficiency on its side. The data fabric (running atop an Akka message bus written in Scala) supports the Elastic APIs (among others), and turns those incoming API requests into GETS that execute against the S3 store.
Since ChaosSearch supports upstream APIs, customers can continue to use their ELK stack tools (plus things like Grafana) to analyze log data. Customers get the same performance and response times as they were used to with the ELK stack, but without the complexity of maintaining the backend Elastic/Lucene data store.

Ed Walsh, formerly the Storage GM at IBM, is the new CEO of ChaosSearch
“It’s not the performance that matters,” Hazel said. “People can make things fast. The question is how much was that performance to you in cost, and how much complexity was needed to get there. That’s what we’re solving.”
Indexing 1PB of data in Elasticsearch/Lucene typically results in indexes that are 5PB in size. But 1PB of data indexed with ChaosSearch results in an index that is 250TB in size, the company said. Customers can use that indexing advantage to either increase the performance of queries, decrease their costs, or increase their data retention periods, Hazel said.
“When your index is 10x smaller, you can provide 10x more performance, or you can be 10x cheaper,” he said. “To do it in a high performance way in S3, you remove caching, remove extra memory, remove extra compute, and now obviously you don’t have to cache off to disk if the queries get too big.”
“We changed the game on this,” Hazel continued. “As a database and information theory guy, this over indexing was causing us to shard these column stores, b-trees…All these things had real big issues.”
Making S3 look and feel like a database wasn’t easy but it was the right solution to tackle this problem, Hazel said. “It’s really just a new modern architecture with an innovative indexing technology and philosophy of using object storage as a first-class citizen,” he said.
Last week, ChaosSearch announced that it has successfully lured Ed Walsh, IBM’s former general manager of storage, to be ChaosSearch’s new CEO. Walsh, who was the CEO of Storwize when IBM acquired it back in 2010, is convinced that ChaosSearch has cracked the code on enabling log analytics at scale.![]()
“It’s the right architecture for what people are trying to do,” Walsh told Datanami.
ChaosSearch is supporting Elastic APIs and targeting log analytics as its first use case, but it’s planning to support SQL and Presto APIs too. At some point, it could support data science workloads and REST requests from Python, R, and TensorFlow models as well.
“If we made them change their APIs, okay, that’s a different company. But that’s not the case,” Walsh said. “That’s what I was most impressed with, how easy they made it for clients to cut over without changing anything out.”
ChoasSearch is getting a lot of interest from banks and brokerage houses that are struggling to keep up with the pace of data creation in their log analytics environments. He related one of the comments that he heard:
“It feels so good to stop beating your head against the wall,” the client said, according to Walsh. “Because log analytics is like air. Everyone just does it. It’s coming from all different direction. And now I can finally focus on the applications, not on keeping the cluster up and running and cost effective.”
ChaosSearch is available on AWS now, with plans to support Google Cloud this year. Support for Microsoft Azure is slated for 2021.
Related Items:
Data is Cheap, Information is Expensive
Wrestling Data Chaos in Object Storage
How Big Data Improves Logging and Compliance
Applications:
Enterprise Analytics
Sectors:
Financial Services
Tags:
AWS, ChaosSearch, cluster, distributed computing, Ed Walsh, ELK, Grafana, s3, sharding, Thomas Hazel
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States