

October 1, 2019
Kafka Transforming Into ‘Event Streaming Database’

Don’t look now, but Kafka is transforming into a database. That’s the new direction the popular event streaming platform is headed, according to Confluent CEO Jay Kreps keynote this morning, in which he gave a glimpse into new KSQL’s new “pull” query feature that’s due next month.
There are actually two new features that the Apache Kafka community is currently working on that will help transform Kafka into an event streaming database. The first is the capability to control Kafka Connect connectors directly from SQL. In a single line of code, users can connect to an external system, such as a database, and extract changes or load streams into Kafka, Kreps said.
The second new feature is the pull query, which will let users look up values from those computed tables within KSQL, the query component of Kafka that was introduced two year ago. “If I materialize some data set in a KSQL table, I can do point lookups for individual keys, what’s the current value for this,” Kreps said.
That will simplify the real-time analytics stack for some use cases and reduce complexity, he said. “I can have KSQL directly control the connectors to capture the changes. It can do the continuous processing and materialization. And then it can actually serve queries for the application to drive the UI,” he said. “So I’ve brought together the event streaming world and the more traditional database world into one system.”
This is the latest evolution of Kafka, the event stream processing system that emerged at LinkedIn when the social media company exceeded the capability of its relational database. In his Kafka Summit keynote on Monday, Jun Rao, a Confluent co-founder and co-creator of Kafka, discussed the series of events that led LinkedIn to abandon the traditional database architecture and instead focus on events.

Confluent CEO Jay Kreps delivered the keynote address at Kafka Summit October 1, 2019
Rao’s keynote emphasized the benefits one gets from breaking out and building around one key component of the database — its commit log. While the relational database uses the commit log to accept incoming data before updating the tables with the current state, relational databases don’t provide elegant mechanisms for querying the underlying events. “Database are really built for states, not for events,” Rao said.
Now the Kafka community is working to bring state back into the Kafka scheme. With the forthcoming new KSQL features that allow queries of materialized data — the official state record as maintained in the database — Kafka now appears to be looking more and more like a database.
Kreps elaborated:
“A stream processor, if it’s built properly, is actually not very different from a distributed database. It’s kind of like a database being run almost in reverse. And if you put these things together, I think it’s actually very natural and powerful. You get a version of KSQL that kind of works in both directions.”
RocksDB is the key-value database that will actually execute the new pull queries that KSQL will be generating, says Venkat Venkataramani, co-founder and CEO of Rockset.
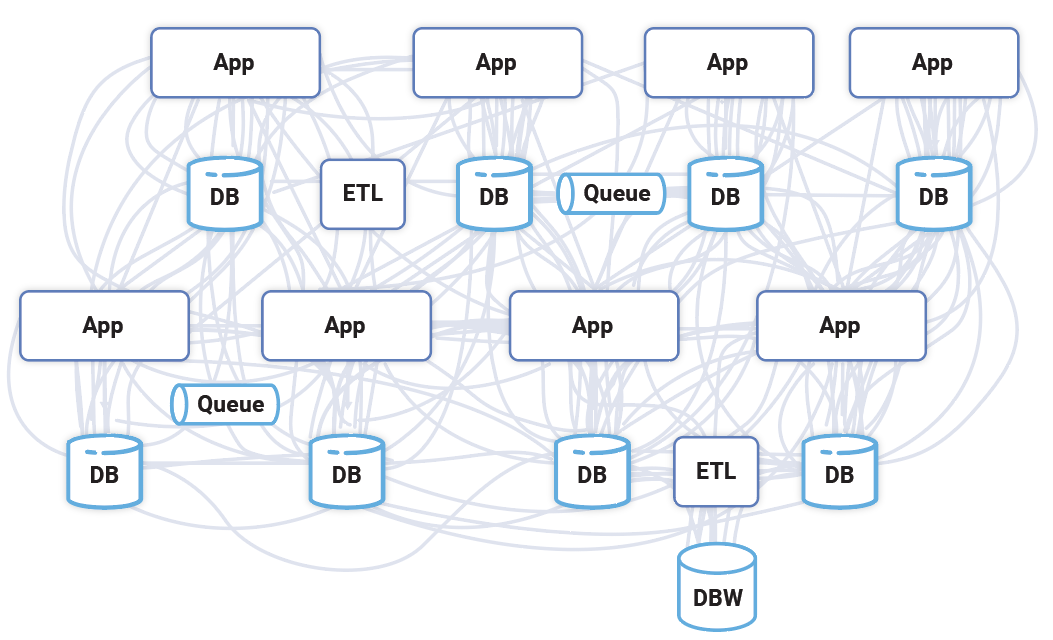
The current state of enterprise data integration is a mess of ETL (Image courtesy Confluent)
“They were already using RocksDB internally to build the stream processing engine, but it was not queryable,” Venkataramani tells Datanami. “And now they’ve added a simple SQL API to also be able to do what they call pull queries, so that you can actually do request-response out of the data that’s actually stored in RocksDB inside Kafka’s environment.”
Here at Kafka Summit San Francisco, there was some confusion around the announcement, which was not made officially by the company. Some attendees wondered whether it was appropriate to call Kafka a database when there is no index. Others noticed that Kreps has called Kafka a database previously.
Whatever the short-term response is, Venkataramani predicts that Kafka customers will be very receptive to the change in Kafka and KSQL once they discover what it lets them do. For anything beyond basic key-value lookups, however, a more full-featured database will be required.
“I think it’s a welcome addition, and the focus towards doing this via SQL is great. I think the community will love it,” he said. “At a high level, the whole space is figuring out SQL is king and SQL-based data management solutions, whether it’s streaming or online operational system or warehouse and offline batch and analytics — all of them are converging to SQL. This announcement I think is a step in the right direction for all data management starting to come around one open standard, like SQL.”
Kreps says the new capability will give customers powerful capabilities, albeit in a relatively narrow range of use cases.
“I think it changes in some sense what KSQL is, from being kind of a streaming engine, almost like a SQL dialect for using Kafka streams, to something more general — a kind of event streaming database,” he said. “And this actually makes a lot of sense. You’re issuing remote queries to a system that’s materializing and storing distributed state. It’s available to do processing. And I think this is actually a really natural generalization of what databases do.”
Relational databases, including data warehouses built on relational databases, are always playing catch up. They host the state of the world in their tables, but companies struggle to keep those tables updated with the latest, greatest information by keeping the tables fed with ETL tools and repeatedly hitting the database with batch SQL queries.
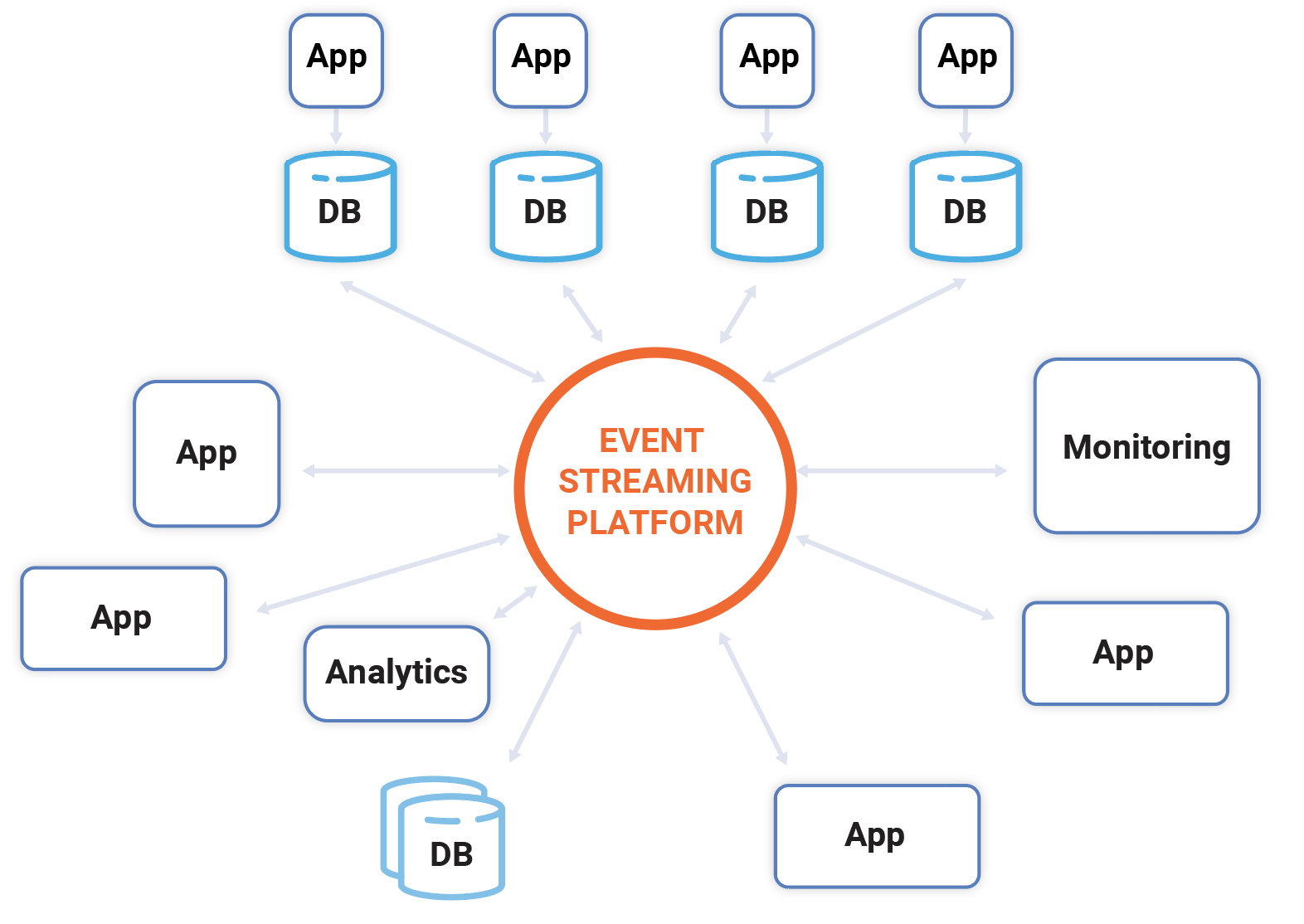
Confluent is reimagining Kafka as a “event streaming database” (Image courtesy Confluent)
“I would argue that most ETL products are kind of the world’s worst stream processing, with a UI on top,” Kreps said. “You’re trying to build this other side of the database. But you’re trying to do it by gluing on external products, and the result is something that isn’t continuous. It’s not up to date with the state of the business.”
Although data warehouses are great for serving up insights from the traditional transactional systems that businesses have built over the past few decades, Kreps argues that they’re not so good for making decisions upon the new flows of non-transactional data that’s flowing into modern businesses.
“Which is why a data warehouse can’t be this kind of central nervous system for additional business,” he said. “It’s a powerful thing. It’s the basis for analytics. It remains incredibly important and successful. But that central nervous system of where all the data comes together increasingly is becoming this kind of event streaming platform.
“We think that KSQL, especially with these new features, can really play an important role in this ecosystem and make it really easy to capture and transform and load and serve these kinds of event streaming applications that are emerging around us.”
The new KSQL features should begin to emerge in November, Kreps said.
Related Items:
When Not to Use a Database, As Told by Jun Rao
Higher Abstractions, Lower Complexity in Kafka’s Future
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States