

May 23, 2018
Okera Emerges from Stealth with Big Data Fabric

(Spectral-Design/Shutterstock)
While data platforms like Hadoop and object stores like S3 have become popular places for organizations to stash massive amounts of data, the platforms haven’t solved companies’ data management challenges. In fact, they’ve exacerbated them in some ways. Now a company backed by former Cloudera executives is launching a new data fabric that’s aimed at simplifying how analysts access data while centralizing security and governance controls.
Okera yesterday announced a $14.6 million round of financing and the general availability of its Active Data Access Platform, which has been in development for about two years and which becomes available today after testing at CapitalOne and other beta sites.
In aiming to solve a tough problem, Okera certainly does not suffer for lack of ambition. “We are about solving data management in a data-centric manner,” Amandeep Khurana, Okera co-founder and CEO, tells Datanami. “Our goal is to enable data platform teams in enterprises to serve their different users and stakeholders without custom engineering and plumbing, regardless of what data platform choices they’re making or what workloads or tools they’re using.”
Khurana says the platform vendors like Cloudera and Hortonworks have solved data security and governance, but only for their own platforms. His goal with Okera is to create an extensible abstraction layer that provides secure and governed data access for data analysts and data scientists while providing security and governance and for heterogeneous storage and analytics environments.
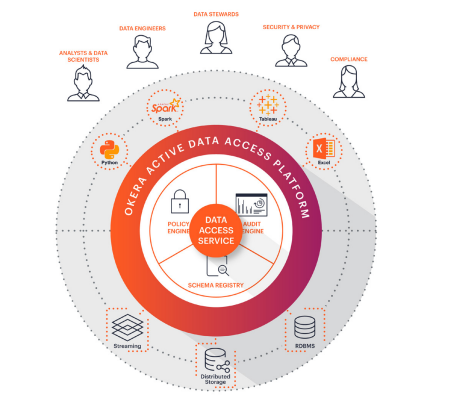
Okera serves multiple groups of users
“Does the security offering of Cloudera apply to a data lake built on S3 and that you use with Databricks?” he asks. “No, it does not. It’s very limited to the Cloudera environment. So it’s not data centric. It’s platform centric.”
Okera’s product includes server and client components. The server component includes a schema registry that provides a unified view of data assets; a policy engine that defines who has access to what data, including whether data should be masked or tokenized; and an audit engine that tracks how data is being used. There are also various client libraries that enforce security and governance functions in the consuming software, which could be a BI tool like Tableau, a Spark cluster connected to S3, or a Python script running on a laptop connected to Hadoop.
The software essentially takes data that’s stored in source systems, like HDFS, S3, or Ceph, and exposes it as a table. Because Okera exposes data as collections of rows and columns, it can execute fine-grained access control upon that data — no matter what file system or file format it’s actually stored in, which gives administrators more power over whom accesses it than they currently have, the company says.
“The approach that we’ve taken is to abstract away that underlying system complexity and give users a much more intuitive abstraction, in this case being tables that they can consume using various standard APIs,” Khurana says. “At that abstraction, it’s much more natural to do fine-grained access control. You can do column-level access control on a table, but you can’t do it on a file, because there is notion of a column in a file.”

Okera aims to simplify access to secure and governed data
This point is critical to the value that Okera is trying to add. For example, if the security policy for a given company says that Social Security numbers must be masked, and the Teradata database supports that level of control but S3 does not, then the company either has the option of building a custom pipeline that gives them that control on the S3 data or shutting off access to the data entirely, Khurana says.
“Our goal is to eliminate this tradeoff people are having to make between agility and governance, between data access and security,” Khurana says. “When you look at the flexibility of data lakes and scale-out platforms built in the cloud…there’s a huge gap. That’s why data platform teams end up spending so much time building and maintaining custom plumbing for each application.”
That usability gap extends to the big data file formats that are often used to make data storage and processing more efficient. “We don’t expect users to have to deal with internals of data lakes,” Khurana says. “It’s not very useful to know whether it’s in ORC or Parquet. [Data scientist and analysts] don’t really care. They deal with higher abstractions of tables.”
As a middleware component, Active Data Access Platform can speed up or slow down data access. Because it offloads things like file I/O parsing and processing of application metadata, it can have a beneficial impact. When used with Spark, Khurana says the software can actually speed up performance by 15% to 20%. In a worst case scenario, it could bring a 5% hit, he says.![]()
Khurana founded Okera in 2016 in San Francisco with Nong Li after spending five years working on the field services team with Cloudera, and before that working on the Elastic MapReduce (EMR) engineering team at AWS. “I had the perspective of the customer and the perspective of how these scale-out solutions are built, where the challenges are, where people end up getting tripped because of platform functionality,” Khurana says. “It was a very unique vantage point.”
Li also spent time at several big data firms, including Cloudera, where he was tech lead for the Impala project and also the author of the Record Service project, and at Databricks, where he led performance engineering for Spark core and SparkSQL. Li also was one of the original authors of the Apache Parquet project and is a monitor to other Apache projects, including Apache Arrow.
The company had been in stealth before yesterday, when it announced the $14.6-million Series A funding round, which was led by Bessemer Venture Partners. Other investors include Felicis Ventures, Capital One Growth Ventures, Menlo Ventures, and Nexus Venture Partners.
Related Items:
Big Data File Formats Demystified
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States