

April 3, 2017
Flink Aims to Simplify Stream Processing

Apache Flink has emerged as a powerful framework for building real-time stream processing applications that has gained traction by some of the most progressive tech companies in the world, including at Netflix, Uber, and Alibaba. But with the latest version 1.2 release of Flink, the framework developers have delivered a new functions and API that offer a simpler path to streaming productivity.
Some of the most powerful stream processing use cases in Flink involve its DataStream API, which is largely based on the DataFlow model developed by Google and its Apache Beam project. DataStream is a high-level API that supports advanced functions like time windowing to the Java or Scala developer, while other low-level APIs provide developers other capabilities.
The new ProcessFunction that was just released in Flink version 1.2 falls somewhere in between, according to Kostas Tzoumas, the co-founder and CEO of Flink-backer data Artisans.
“It’s a place where you can subscribe to streams, where you keep state, and you can manage time and schedule timers,” Tzoumnas said during the recent Strata + Hadoop World conference. “It’s a very easy way to create state machines, and also to build applications that are stream processing applications but don’t fit into the model of time windows.”
Another way to build streaming applications without the deep level of technical understanding required to use the DataStream API is the Table API. Technically a combination of the Table & SQL API, the Table API essentially exposes the data stream as a change log in a dynamic database table, according to a recent blog post on the Table API by data Artisans software engineer Timo Walther.
“Over the past year, the Table API has been rewritten entirely,” Walther wrote. “Since Flink 1.1, its core has been based on Apache Calcite, which parses SQL and optimizes all relational queries. Today, the Table API can address a wide range of use cases in both batch and stream environments with unified semantics.”![]()
Specifically, the Table API in Flink 1.2 gained support for tumbling, sliding, and session group-window aggregations over streaming tables. These Table API enhancements should help to make streaming applications more accessible to other developers, Walther wrote.
“There is significant interest in making streaming more accessible and easier to use,” he wrote. “Flink’s Table API development is happening quickly, and we believe that soon, you will be able to implement large batch or streaming pipelines using purely relational APIs or even convert existing Flink jobs to table programs. The Table API is already a very useful tool since you can work around limitations and missing features at any time by switching back-and-forth between the DataSet/DataStream abstraction to the Table abstraction.”
Meanwhile, the new Queryable State function in Flink 1.2 should also simplify development of streaming applications. Previously, if Flink users wanted to query a piece of data that’s flowing through their application, and get an answer in return, they had to land it first, perhaps on Redis or some other database. Of course, Flink could act on the streaming data or transform it with its various operators (that is it’s core mission in life). But users could not expect to get an answer in response to a question without incorporating additional applications and systems.
That paradigm changes with Queryable State, a new experimental feature in Flink 1.2 that allows a user to ask a question and get a response without landing the data first, which has always been the bottleneck, Tzoumas said.
“You can see Flink as a sort of a key-value store, where the state is stored in the Flink nodes, and it’s updated continuously by the stream, and this gives you the ability to go and query it,” he said. “You can query a live stream as if it were a database table.”
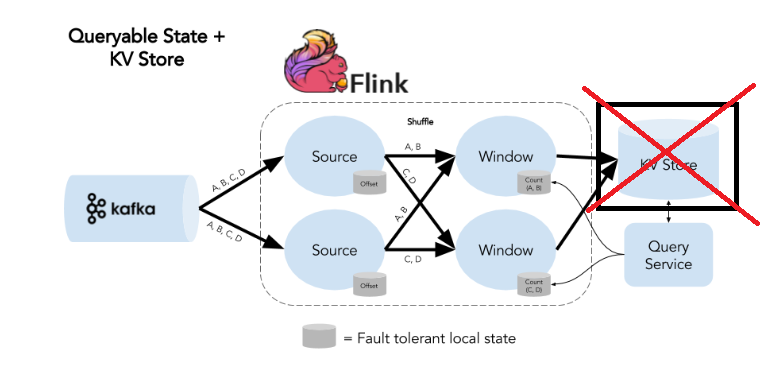
The Queryable State feature in Flink 1.2 enables users to eliminate a key-value store from the streaming application’s architecture
Flink’s robustness should improve with the new Dynamic Scaling/Key Groups functionality added to version 1.2. This capability essentially changes the parallelism of a streaming job by restoring it from a savepoint with a different parallelism, all without any downtime. “Dynamic scaling is the ability [of a Flink cluster] to rescale itself while it’s running, including the state,” Tzoumas said.
Version 1.2 also brings support for Mesos and DC/OS; support for Kerberos authentication via external Zookeeper, Kafka, HDFS, and YARN services; and a backwards compatible savepoint that allows rolling upgrades from older Flink releases.
Looking ahead, data Artisans is working on a number of additional features designed to bolster the Flink framework, including features such as: incremental checkpointing; enhancements to the Complexed Event Processing (CEP) library; and extensions to support deep learning frameworks like TensorFlow.
The new features in Flink 1.2 and forward-looking enhancements will all be discussed at Flink Forward, a Flink conference that data Artisans is hosting next week in San Francisco, where it has an office (headquarters is in Berlin). Netflix, Uber, and Alibaba are also expected to talk about their experience using Flink, which is challenging other frameworks like Spark Streaming and Storm for emerging stream-processing use cases.
Tzoumas is confident that Flink’s approach is the right one for a certain set of use cases for stream processing.
“The right thing is to ask yourself ‘What is my use case? What is the best tool for the job?’ You don’t need to pick a platform that does everything,” he said. “The line between what we call analytics and applications has become more blurry. What Flink is really, in essence, is a way to write applications, and keep the state fault-tolerant.”
Related Items:
Apache Flink Gears Up for Emerging Stream Processing Paradigm
Apache Flink Takes Its Own Route to Distributed Data Processing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States