

January 12, 2015
Apache Flink Takes Its Own Route to Distributed Data Processing

Apache Flink, a distributed in-memory data processing framework project born out of Germany, this week graduated the Apache Incubator stage and became a Top-Level Project at the open source software foundation, paving the way for an acceleration of Flink development and deployment.
Originating from the Stratosphere research project at the Technical University of Berlin in 2009, the Flink framework is designed to run batch and streaming analytic workloads in a parallel manner. In a Hadoop cluster, Flink sits atop YARN and provides yet another alternative to MapReduce as the processing engine. But Flink doesn’t have to run atop Hadoop, and in fact can run on laptops, in the cloud, or even as a containerized Web app.
The creators of Apache Flink concentrated their efforts on building a scalable and performant framework. To that end, they developed unique type serialization, memory management, and query optimizers in Flink. These innovations continue to be the calling card for Flink and the source of the performance advantage over MapReduce-powered Hadoop touted by its founders.
According to Flink’s backers, the open source framework is particularly good at iterative processing, which is something that MapReduce has always struggled with. During tests, Flink ran the PageRank algorithm on a graph of  Twitter data nearly three times faster than MapReduce, with twice the number of iterations.
Twitter data nearly three times faster than MapReduce, with twice the number of iterations.
Currently, Flink offers programming APIs in Java and Scala, as well as Spargel, a specialized API that implements a Pregel programing model. The Flink community is currently working on a Python API, as well as an API for streaming data.
Most of the creators behind Flink are at data Artisians, a Berlin-based company founded to further the development of the software and to provide technical support for companies adopting the software. Kostas Tzoumas, co-founder and CEO of data Artisans, says becoming a Top-Level Project in the Apache Software Foundation is a great milestone for Flink, and reflects how quickly the community is growing.
“The community is currently working on some exciting new features that make Flink even more powerful and accessible to a wider audience, and several companies around the world are including Flink in their data infrastructure,” Tzoumas says.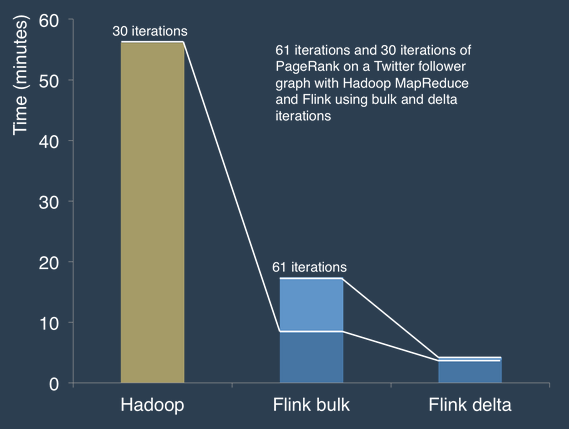
There don’t appear to be many wide-scale Flink deployments at the moment, which is understandable considering how young Flink is. But there are several prominent companies are experimenting with Flink, including the European travel giant Amadeus, streaming music site Spotify, and ResearchGate, a gateway for open scientific research.
“At Amadeus, we continually seek for better improvement in our analytic platform and our experiments with Apache Flink for analytics on our travel data show a lot of potential in the system for our production use,” says Denis Arnaud, head of data science development Amadeus Travel Intelligence.
“I have been experimenting with Flink, and we are very excited to hear that Flink is becoming a top-level Apache project,” said Anders Arpteg, Analytics Machine Learning Manager at Spotify.
ResearchGate uses Apache Flink in its production data infrastructure, according to Ijad Madisch, co-founder and CEO of ResearchGate. “We are happy all around and excited that Flink provides us with the opportunity for even better developer productivity and testability, especially for complex data flows,” Madisch says. “It’s with good reason that Flink is now a top-level Apache project.”
Related Items:
Hadoop Alternative Is Faster and Lighter, Proponents Say
Hadoop Alternative Hydra Re-Spawns as Open Source
Hadoop Alternative Lands on Amazon’s Cloud
Technologies:
Frameworks
Vendors:
data Artisians
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States