

September 16, 2016
Flink: Worth a Second Look

The big data ecosphere has evolved to the point where there are clear technology leaders. In the category of SQL engines that run on Hadoop, Hive and Spark are clearly the dominant products among open source developers. In the shadow of these leaders, there are a number of emerging technologies that, while they may have advantages over the leaders in certain use cases, have not yet established a very large user footprint.
This includes products such as Impala, Presto, Drill, Flink, Kylin, Tajo and Quasar. You probably haven’t heard of these new kids on the block, let alone understood what use cases they aim to solve or how well they work. One of these second-tier products, Flink, is certainly worth a second look (despite having a name that sounds like a villain in a spy movie).
Flink started as a German research project at universities in Berlin and Potsdam (“Flink” means “nimble” in German), and became an Apache Incubator project in 2014. Like Spark, it enables analysis of both batch and streaming data, replacing Hadoop’s MapReduce paradigm with a directed graph approach that leverages in-memory storage for massive performance gains.
So, how is Flink different than Spark? To explain, let’s look at a common use case.
Suppose you are developing an Internet of Things (IoT) system that collects data (e.g., temperature, pressure, distance travelled) from a number of sensors in a fleet of cars, once every two seconds. Your system should enable users to view statistics such as sum of distance travelled and daily average temperature over the past year or past week. Suppose you have hundreds of simultaneous users, and they expect results within seconds.
One approach would be to perform all calculations as the users request them. This would provide results that are accurate up to the current second, but it would take many minutes to perform these calculations on the fly, and your users will lose patience after a few seconds. An alternate approach would be to pre-calculate results for all possible requests, so they are ready to be served up as soon as users request them. But, those results would inevitably be inaccurate, because they would not reflect data received since the last time the canned results were pre-calculated.
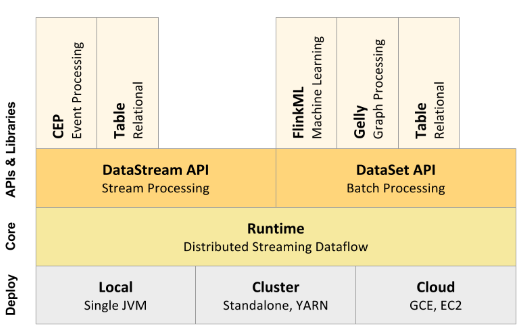
The Flink Architecture
To handle this use case, Nathan Marz defined a framework known as the Lambda Architecture, which proposes to analyze the batch data (e.g. all data received up to and including yesterday) separately from the real-time data (e.g., all data received today). Batch data is analyzed offline, while the real-time streaming data is analyzed on an ongoing basis, as it arrives. When a user issues a query, the system combines the pre-calculated batch analytics and the real-time analytics into a single result on the fly. This provides the best of both worlds – rapid response time and up-to-the-second accuracy.
A strict requirement of the Lambda Architecture is that the batch analytics and the streaming data analytics must be calculated in an identical fashion – otherwise, combining them will produce garbage. The best way to guarantee equivalence is to run exactly the same code base on both the batch data and the real time data, using the exact same analytic engine. But, this requires a single analytic engine that can analyze both batch and real-time data.
Fortunately, Spark fits the bill. Spark was originally designed to analyze batch data, then extended into Spark Streaming, which processes real-time data by breaking it into micro-batches that are periodically (e.g., once per minute) processed by the Spark engine. And, unlike other streaming analytics systems such as Storm, Spark guarantees that each message will be processed only once, which is exactly the behavior we need.
If we use Spark to solve our use case, we have to make a compromise: the answer we deliver will not be accurate up to the second – it will only be accurate up until Spark Streaming processed the last micro-batch, e.g., it could be up to one minute out of date. This is known as high latency, i.e., there could be a long wait until a message is processed. Let’s suppose that our users are willing to accept this slight time-lag inaccuracy. Now let’s add a new condition to our use case. Suppose there are some messages received from our fleet of cars that require immediate attention, e.g., a car is on fire. Your users will probably not agree to wait until the next micro-batch is processed (i.e., up to one minute) in order to receive this alert. So, Spark is no longer the right solution, because of its high latency.
For this use case, Flink would be your best choice. Like Spark, Flink uses the same calculation engine to process both batch and streaming real-time data, and it guarantees that each message will be processed only once, so it is a good choice for implementing the Lambda architecture. Unlike Spark, however, Flink processes streaming data in real-time, one message at a time as it arrives, rather than via micro-batches. So, unlike Spark, Flink supports low latency that can provide up-to-the-second analytic accuracy. And, unlike Spark, Flink can immediately spot an urgent message (e.g., the car is on fire) and trigger an alert in real time.
Flink has several other features that distinguish it from Spark:
- An aggressive optimization engine that analyzes the code submitted to the cluster and produces the best pipeline for running on that particular setup.
- An internal memory management system, separate from Java’s garbage collector. By managing memory explicitly, Flink clusters suffer from far fewer memory spikes than Spark clusters.
- Faster processing for iterative algorithms, where the same data must be analyzed multiple times, e.g., delta iterations that run only on those data elements that changed since the last iteration.
For all Flink’s advantages, Spark is still the 800-pound gorilla, with far more popularity and adoption, and far more trained developers. But, as we have seen, for use cases that require both batch and real-time processing with low latency, Flink is an excellent choice that is well worth a second look.
About the author: Moshe Kranc is Chief Technology Officer at Ness Digital  Engineering, a provider of digital transformation and software engineering services. Moshe has worked in the high tech industry for over 30 years in the United States and Israel, and has extensive experience in leading adoption of bleeding edge technologies. He previously headed the Big Data Centre of Excellence at Barclays’ Israel Development Centre (IDEC), and was part of the Emmy award-winning team that designed the scrambling system for DIRECTV. Moshe holds six patents in areas related to pay television, computer security and text mining. He has led R&D teams at companies such as Zoomix (purchased by Microsoft) and NDS (purchased by Cisco). He is a graduate of Brandeis University and earned graduate degrees from both the University of California at Berkeley and Boston University.
Engineering, a provider of digital transformation and software engineering services. Moshe has worked in the high tech industry for over 30 years in the United States and Israel, and has extensive experience in leading adoption of bleeding edge technologies. He previously headed the Big Data Centre of Excellence at Barclays’ Israel Development Centre (IDEC), and was part of the Emmy award-winning team that designed the scrambling system for DIRECTV. Moshe holds six patents in areas related to pay television, computer security and text mining. He has led R&D teams at companies such as Zoomix (purchased by Microsoft) and NDS (purchased by Cisco). He is a graduate of Brandeis University and earned graduate degrees from both the University of California at Berkeley and Boston University.
Related Items:
Apache Flink Gears Up for Emerging Stream Processing Paradigm
Merging Batch and Stream Processing in a Post Lambda World
Apache Flink Takes Its Own Route to Distributed Data Processing
Applications:
Predictive Analytics
Sectors:
Manufacturing
Tags:
Apache Flink, apache spark, batch, big data, iot, latency, micro-batch, real-time processing, sensors
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States