

March 13, 2017
Fully Hydrate Your Lake in 8 Weeks or Less, Zaloni Says

Zaloni today rolled out Data Lake in a Box, a soup-to-nuts offering for getting a fully governed Hadoop cluster up and running in eight weeks or less. The offering includes Hadoop software, data management middleware, and implementation services. “Everything but the hardware,” Zaloni’s VP of marketing says.
While Hadoop clusters are powerful data storage and processing machines, they’re not easy to implement or manage. There are many configurations settings that require skill and experience to get right. And once the cluster is configured, getting the data ingested in a way that it can actually be worked with is not a trivial matter.
It’s not uncommon to hear about six-month Hadoop deployments. In these situations, much of the time spent is spent building and implementing data management processes that ensure the data is governed, discoverable, and accessible to the end-users who will (eventually) be allowed access into the cluster, or at least a part of it.
Zaloni is hoping to shortcut these extended deployments by bringing together all the software and services necessary to get a general-purpose and governed Hadoop cluster up and running in about two months.
“We’re helping companies get fully hydrated in under eight weeks,” says Zaloni vice president Kelly Schupp. “We’re reducing the time and effort it takes by up to 75%, and at the same time we’re providing the kind of visibility and governance support they’re going to need, because, as that data is getting ingested, it’s being tagged and cataloged.”
Data Lake in a Box combines Bedrock, its data lake management offering, and Mica, its self-service user access offering, with its Ingestion Factory software and users choice of Hadoop distribution, including plain vanilla Apache Hadoop or, for an extra fee, the Hadoop distributions from Cloudera or MapR.
It’s all about quickly creating a fully governed Hadoop cluster that will serve the needs of the business for many years, says Tony Fisher, Zaloni’s senior VP of strategy and business development.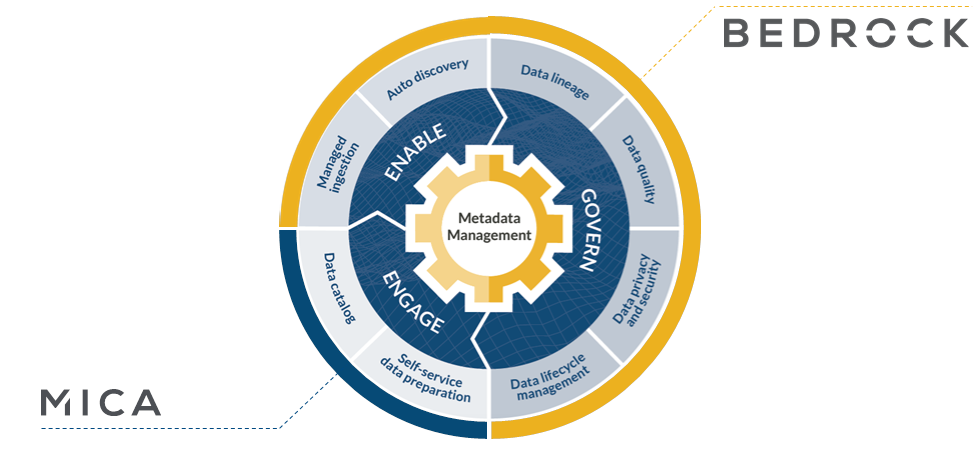
While eight weeks is a big improvement over six months, it’s still not as quick as some offerings that promise to create ready-to-use Hadoop clusters in a matter of days. The key difference there is quality, says Tony Fisher, Zaloni’s senior VP of strategy and business development.
“There’s a big difference between creating a data lake and a data swamp,” Fisher says “You can ingest anything into a data lake in three days. But the fact of the matter is it doesn’t’ have the data quality, the rigor, or the types of things you’re going to need to do productive analytics on it.”
The offering doesn’t include analytics; it’s up to the user to bring those. That’s fine because most customers these days are developing their own analytics in Python or R using data science notebooks, or hooking Excel, Tableau, or Qlik BI tools to visualize and manipulate data.
Companies that adopt Hadoop are finding that it takes more time and effort than they expected to get good results out of Hadoop, says Nik Rouda, an analyst with Enterprise Strategy Group.
“Operationalizing data lakes has proven much harder and taken much longer than most enterprises would want,” he states in Zaloni’s press release. “This process typically involves manually cobbling together a large number of disparate tools, and then trying to support that mess going forwards. Zaloni integrates all the essential capabilities and best practices and packages them up, delivering quality and productivity right out of the box.”
Zaloni says it’s getting traction with Bedrock and Mica, which come together in a single offering for the first time with the new Data Lake in a Box offering. The company says bookings and revenues grew by 3x from 2015 to 2016, and it’s hoping the new offering continues that momentum.
One of the Durham, North Carolina company’s customers, Emirates Integrated Telecommunications Company (also known simply as du), will be in San Jose, California this week to present at the Strata + Hadoop World show. The company will discuss its experience with Zaloni’s products. Other prominent Zaloni customers include SCL Health, CDS Global, and Pechanga Resort and Casino.
Related Items:
Dr. Elephant Steps Up to Cure Hadoop Cluster Pains
IBM Taps Zaloni to Ride Herd on Hadoop
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States