

March 7, 2017
Dr. Elephant Steps Up to Cure Hadoop Cluster Pains

Getting jobs to run on Hadoop is one thing, but getting them to run well is something else entirely. With a nod to the pain that parallelism and big data diversity brings, LinkedIn unveiled a new release of Dr. Elephant that aims to simplify the process of writing tight code for Hadoop. Pepperdata also introduced new software that takes Dr. Elephant the next step into DevOps.
The Hadoop infrastructure at LinkedIn is as big and complex as you likely imagine it to be. Distributed clusters run backend metrics, power experiments, and drive production data products that are used by millions of people. Thousands of internal users interact with Hadoop via dozens of stacks each day, while hundreds of thousands of data flows move data to where it needs to be.
The social media company appreciates a tidy cluster, just like everybody else, but getting things in an orderly manner on Hadoop was beginning to resemble an impossible task, according to Carl Steinbach, a senior staff software engineer at LinkedIn.
“We found that sub-optimized jobs were wasting the time of our users, using our hardware in an inefficient manner, and making it difficult for us to scale the efforts of the core Hadoop team,” Steinbach writes in a blog post yesterday.
While LinkedIn does have a team of technical Hadoop experts at the ready, it would be a waste of time to have them tune each user’s job manually. “At the same time, it would be equally inefficient to try and train the thousands of Hadoop users at the company on the intricacies of the tuning process,” Steinbach writes.
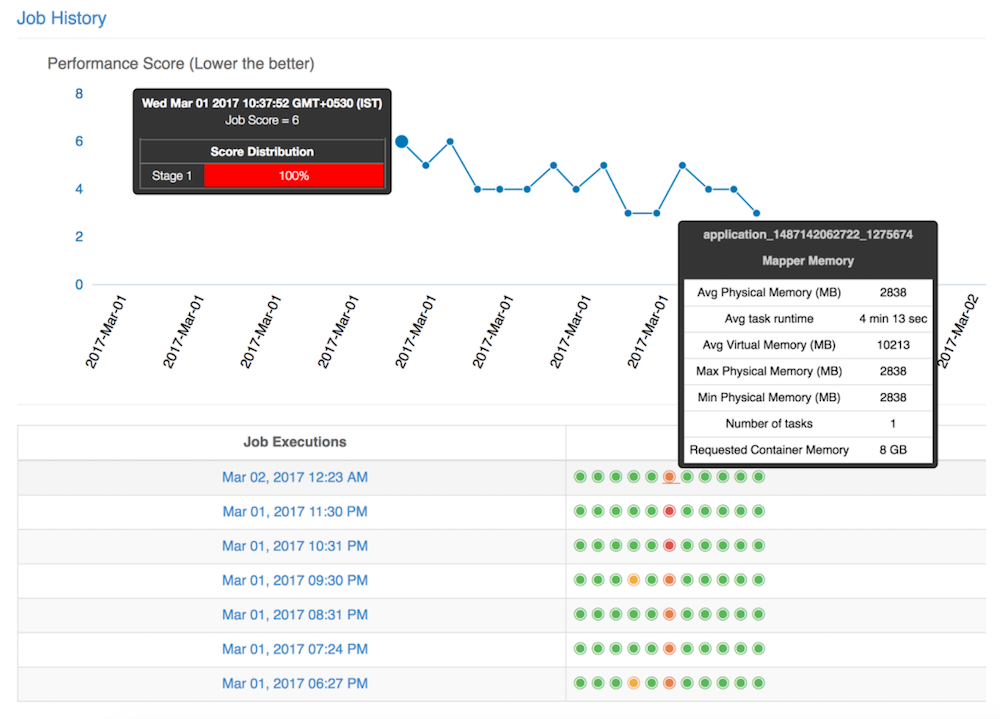
LinkedIn’s Dr. Elephant tool presents users with a Web-based dashboard that shows them how their Hadoop jobs are running
Instead, the company created Dr. Elephant. First released a year ago, Dr. Elephant was updated by LinkedIn yesterday with enhancements that should make it easier to get users and developers on the straight and narrow when it comes to writing well-crafted Hadoop jobs.
The idea behind Dr. Elephant is to identify poorly executing jobs, diagnose the root cause, and then provide developers and other users with recommendations on how to improve the performance of a job without impacting overall cluster efficiency. It’s all about helping users navigate through the bewildering array of choices they have for configuration settings and how to accomplish specific tasks on different frameworks, like MapReduce and Spark.
Just as real doctors don’t impose treatments on patients, the Dr. Elephant software doesn’t automatically make changes and doesn’t force users to accept its recommendations. Instead, it offers suggestions that users are free to adopt or to ignore. (You can bring an elephant to water, as the saying goes, but you can’t make her drink.)
This approach has worked well for LinkedIn, which says Dr. Elephant has been very well received by users. The company says the ease of checking the Dr. Elephant dashboard to see how well (or badly) Hadoop jobs are running creates a bit of positive peer pressure.
“No one wants to have a poorly tuned Hadoop job on the Dr. Elephant dashboard, just like no one wants to submit poorly-written code to an open source project,” Steinbach says.
LinkedIn’s success with Dr. Elephant has spilled over into open source, where the community has driven additional development work in areas like Oozie, Airflow, Azkaban, and Spark integration. It’s also been adopted by Foursquare, Pinterest, Hulu, and other companies, as well as commercial vendors.
One of those commercial vendors is Pepperdata, which today announced that it’s releasing a new product called Application Profiler that is based on Dr. Elephant.
![]() Combined with other Pepperdata products, including the Cluster Analyzer—which collects more than 300 metrics per task in real time—the Application Profiler will provide Hadoop shops with a boost for their DevOps cycles, says Chad Carson, co-founder of Pepperdata.
Combined with other Pepperdata products, including the Cluster Analyzer—which collects more than 300 metrics per task in real time—the Application Profiler will provide Hadoop shops with a boost for their DevOps cycles, says Chad Carson, co-founder of Pepperdata.
“Application Profiler and Dr. Elephant are really bringing the Hadoop knowledge, the understanding of the different phases of the overall job, to the developer,” Carson tells Datanami. “A given job might be touching thousands of nodes, and App Profiler and Dr. Elephant understand that and can help the developer to understand how much parallelism to use.”
In some cases, Application Profiler may encourage a user may to totally rewrite a given application, says Pepperdata CEO Ash Munshi.
“They may find the algorithm they’re using has too much communication, too much network traffic, that it relies on storage too much, or that it doesn’t have the right type of locality,” says Munshi, who joined Pepperdata last year. “All of those are things that become evident in this case, and then they have changes they can make, which is how much parallelism you want to do, or make structural changes in the code, which is the algorithm I’ve got is not really a match for what I want to do.”
There are aspects of developing and operating Hadoop and big data clusters that are very different than traditional systems, and customers are struggling with that learning curve at the moment. Much of it boils down to how much parallelism a developer should strive to include in the code. But with hundreds of configuration switches to set, nailing the right pattern can be difficult for those lacking extensive experience, Carson says.
“You have a much more complex parallelism that than you do in traditional code,” he says. With so much complexity in modern distributed systems, it can be difficult to get jobs to return results in an acceptable period of time. This is a problem that many Hadoop users are struggling with, particularly as they seek to bring jobs from the lab into production.
“We like to say that performance can mean the difference between business critical and business useless,” Carson says. “Because with big data, you have not just a bunch of nodes doing things independently, but you’ve got a very complex computer system working at scale. You have lots of complicated interactions among the different jobs, among the different nodes.”
Related Items:
LinkedIn Diagnostics Help Tune Hadoop Jobs
Enforcing Hadoop SLAs in a Big YARN World
Shining a Light on Hadoop’s ‘Black Box’ Runtime
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States