

August 3, 2016
Apache Flink Gears Up for Emerging Stream Processing Paradigm

We’re close to the next release of Apache Flink, the stream processing engine developed by the Apache Software Foundation. Flink version 1.1.0 will bring new SQL interface for working with streaming data, while bigger changes, like dynamic scaling, are set for the subsequent release. Meanwhile, Internet giants like Alibaba and Netflix are set to share their Flink stories at a conference next month.
Flink is one of the upstarts in the battle of the big data frameworks that’s currently waging across the Web and in the halls of big data development shops around the world. At this point, Apache Spark appears the odds-on favorite to win–or at least to survive another five years, which qualifies as winning in this rough-and-tumble sport.
But there are several frameworks that surpass Spark’s general-purpose capabilities in key areas, most notably stream processing. While Spark’s micro-batch approach to streaming will work for many use cases, it’s not a good fit when high volumes of data must be processed with low latency (i.e. less than a second). For these types of workloads, Flink is one of the frameworks that offers better performance characteristics with its “streaming first” approach; also in the running are Apache Beam, Apache Storm, Apache Apex, Concord, and others.
With more than 200 contributors, Apache Flink is building momentum among the all-important developer community. The software, which came out of the Stratosphere research project at the Technical University of Berlin in 2009 and today is backed by data Artisans, is one of the most popular Apache projects, and is beginning to see more widespread adoption since the release of version 1.0 earlier this year. Among the companies that will be presenting on the in-memory technology at the Flink Forward event in Germany next month are Alibaba, Netflix, and Zalando.
The biggest production user of Flink could be Alibaba, the so-called “Chinese Amazon,” which is running two clusters of more than 1,000 nodes each. Alibaba presented a session about their use of a modified version of Flink at the recent Hadoop Summit in California. The company is now working to merge those modifications back into the main open source version of Flink, according to data Artisans CEO and co-founder Kostas Tzoumas.
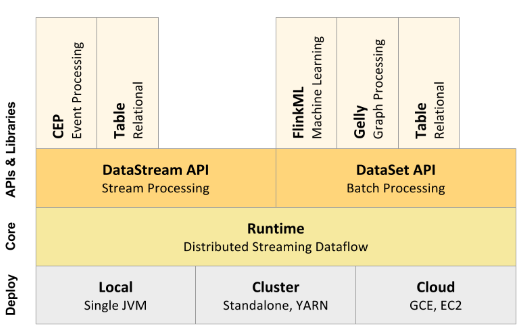
Apache Flink’s high-level archiecture
Flink is powering Alibaba’s recommendation engine, and is a key component of the company’s shift to a micro-services architecture, Tzoumas says. “They basically figured out if they can exploit real time information for recommendations, they can make much better recommendations,” he tells Datanami. “They were doing that once per day. But they figured out that if they can actually adjust that in real time throughout the day, they can provide much better recommendations.”
Streaming and Batch and SQL
Powering real-time recommendations is one of the use cases that Flink excels at, but it’s not the only one. Like Spark, Flink aims to provide a wide assortment of data processing capabilities to big data developers and architects, all presented through a streaming-first point of view.
To that end, the project’s DataStream API can be expected to get a lot of use. Flink also includes a DataSet API, which provides batch-like capabilities that essentially treats a static data set as a stream of data with a beginning and an end. It’s worth noting that data Artisans modified the DataStream API after the release of Flink 0.9 and remodeled it in the image of Google’s Dataflow. (“It became apparent to us that the Dataflow model…is the correct model for stream and batch data processing,” Tzoumas wrote in May.)
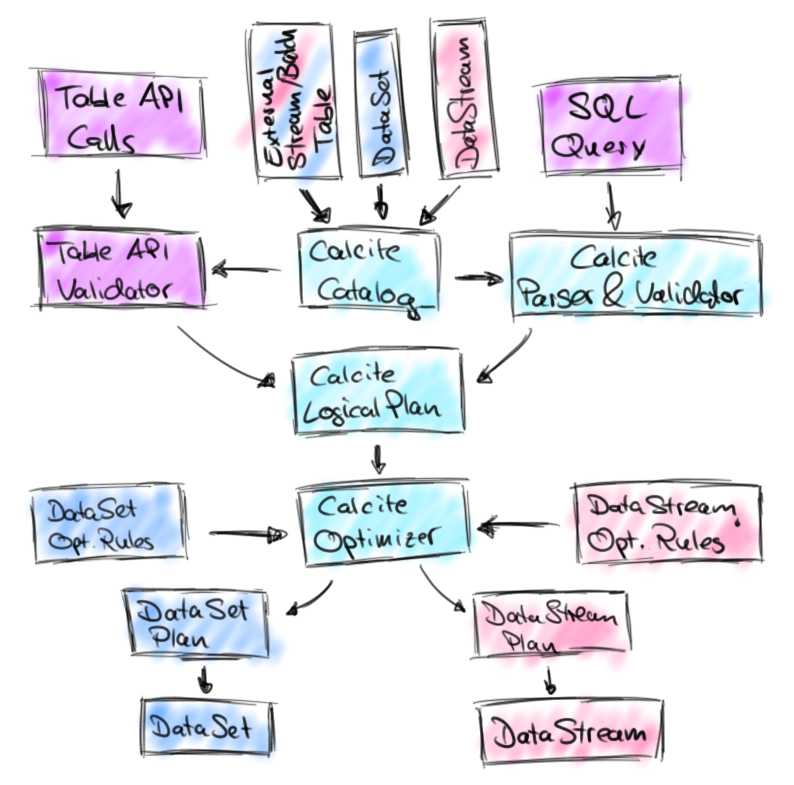
Apache Calcite features prominently in Flink’s SQL plans
On top of these two core APIs, Flink is delivering a set of libraries that offer additional capabilities. On top of the DataStream API, Flink offers the CEP for complex event processing and the Table library for using SQL functions on relational data. Atop the DataSet API, Flink offers the FlinkML machine learning library; the Gelly library for graph processing; and the Table library for SQL functionality.
The idea is to open up Flink to a wider audience, Tzoumas says. “Our goal is, number one, to make Flink really production ready,” he says. “We’re very much focusing on making it stable, making it easy to use, making it easy to integrate with other systems in the infrastructure.”
The Flink community is days away from announcing the next major release of Flink, version 1.1.0, which will feature a new version of the SQL library for both static data and streaming data. The idea is to support SQL “as a first class citizen” in Flink, Tzoumas says.
While you won’t be able to access all of Flink’s capabilities via SQL, it will offer the SQL-loving business analyst (or, presumably, BI projects that generate SQL queries) access to some of Flink’s streaming capabilities. According to data Artisans co-founder Fabian Hueske, adding SQL capabilities just makes sense.
“[A] SQL interface for stream data processing will make this technology accessible to a much wider audience,” Hueske writes in a recent blog post. “Moreover, SQL support for streaming data will also enable new use cases such as interactive and ad-hoc stream analysis and significantly simplify many applications including stream ingestion and simple transformations.”
The new Table API that’s about to debut builds heavily on Apache Calcite, a popular SQL parser and optimizer framework that’s used by many other SQL on Hadoop offerings, including Apache Hive and Apache Drill, as well as Cascading. However, while those projects utilize Calcite for powering SQL queries on static data, Flink enjoins Calcite for creating SQL queries on streams of data, which is a goal that’s also part of Apache Calcite’s roadmap, Heuske says.
New connectors for Amazon Kinesis, Cassandra, and ElasticSearch are also among the new version 1.1.0 features.
Dynamic Scaling
As version 1.1.0 marches toward the door, the Flink community is gearing up for the next major initiative: version 1.2.
“Basically we see this [version 1.1.0] as a stepping stone to 1.2, which will be released later and have a lot of new features like the ability to dynamically scale and go up and down during run time, and to query the state,” Tzoumas says.![]()
Dynamic scaling will enable Flink customers to scale Flink clusters up and down with a minimum of downtime. According to Tzoumas, the feature will essentially enable users to push a button to save the state of the computation, stop processing, and then resume processing at a higher state of parallelism.
“If the volume is very high, you will be able to give more resources and Flink will redistribute
within the space … and continue the program with higher parallelism from a safe mode,” he says. “We call it dynamic scaling.”
Queryable state, meanwhile, will expose to developers some of the internal functions that Flink currently uses to maintain its exactly-once processing guarantees. According to the project, exposing this will help to eliminate the need for Flink users to build additional systems, such as key value stores, to be able to query the state of processing.
Lastly, the project is working on adding support for the Mesos resource scheduler. About half of Flink deployments currently run atop Hadoop and YARN, according to Tzoumas. But in many cases, Hadoop brings too much computational overhead for stream processing, he says.
Related Items:
Apache Flink Creators Get $6M to Simplify Stream Processing
Apache Flink Takes Its Own Route to Distributed Data Processing
Sectors:
Retail
Vendors:
data Artisans
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States