

May 2, 2016
Spark Takes On Dataflow in Benchmark Test

Google Cloud Dataflow crunched data two to five times faster than Apache Spark in a benchmark test of batch analytics performed by Mammoth Data. While Dataflow’s raw power is impressive, don’t throw in the towel on Spark just yet.
If you’re looking to choose a framework to analyze your big data, good luck. With so many options out there, you’ve got your work cut out for you. This embarrassment of big data riches keeps the tech experts at North Carolina consulting firm Mammoth Data busy.
When Google (NASDAQ: GOOG) asked Mammoth Data to test its Google Cloud Dataflow service in a real-world setting, the company jumped at the chance. With funding by Google, Mammoth Data constructed a benchmark that compared how Dataflow and Spark performed on identically configured clusters running on the Google Compute Engine cloud.
To get an apples-to-apples comparison, Mammoth Data overrode the default instance for Google Cloud Dataflow (which is available only on the cloud, mind you) and selected a cluster consisting of “n1-highmem-16” nodes, which have lots of memory.
The source data for the benchmark test was event data generated by video playing devices, such as set-top boxes. The clusters would be asked to compute time-based computations against the CSV data, which will tell you how many times a user is logging into a service during a given period of time. It’s a fairly typical batch-oriented use case that’s useful for a variety of real-world analyses, such as fraud detection.
The results, which Mammoth Data is officially releasing tomorrow, showed that Dataflow completed the analysis 5.7 times faster than the Spark cluster on the smallest cluster (128 cores), while Dataflow’s advantage over Spark dropped to about 2x on the largest cluster (1,024 cores).
Dataflow was the hands-down winner for this use case. “It did do very well indeed,” Mammoth Data Lead Consultant Ian Pointer tells Datanami. “It was from 2 to 5x as fast as Spark and obviously, when you’re using Dataflow you don’t have any operational concerns that you might have when you’re running your own Spark cluster.”
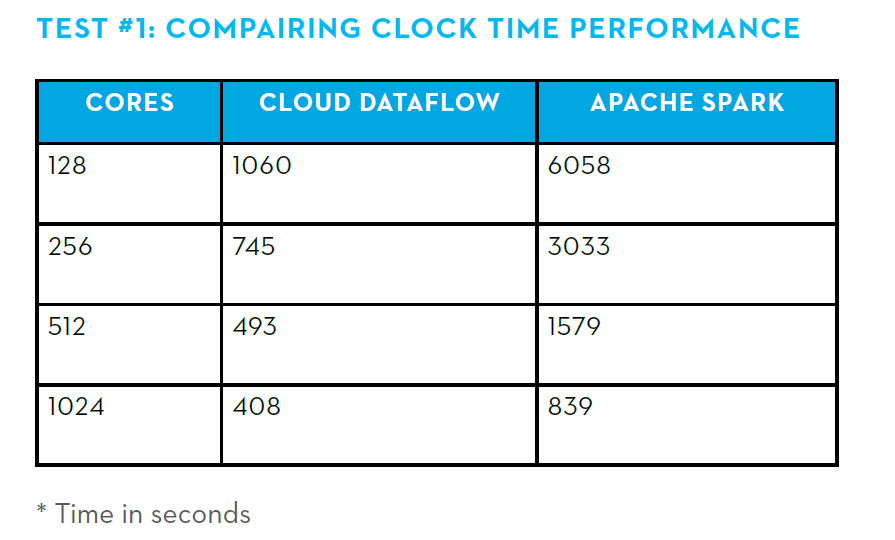
Comparison in time required to complete batch query. Source: Mammoth Data
The data shows that Spark’s performance scaled nearly linearly with the number of cores added to it, whereas Dataflow’s curve is more gradual. Mammoth Data talked with Google engineers and realized this was due to Dataflow’s design—in particular how its dynamic work rebalancing capability works to ensure that all processors are fully utilized. This design point of saturating the CPUs has the tendency to make Dataflow jobs more I/O bound.
The researchers also analyzed the cost and found that “it would take approximately 8X Spark resources to achieve the slowest Dataflow job runtime (128 cores),” Mammoth Data writes in its benchmark paper. “This is a key point when considering both cost implications and resource capacity planning.”
Picking Big Data Winners
While Dataflow is clearly fast, does that mean that it’s always the right choice for big data workloads? Not necessarily, says Mammoth Data founder and president Andrew Oliver. “It’s always going to depend on what your specific problem that you’re trying to solve,” says Oliver, who also writes a regular column at InfoWorld.
Deciding which technology to use isn’t easy, so to simplify the process, Oliver breaks the problem down into three parts. First, you’re looking for the fastest engine. Secondly, the workloads has to be factored into the mix. Lastly, you want to consider the operational aspect of the framework.
The benchmark shows Dataflow is clearly faster than Spark. But Spark has an ace up its sleeve in the form of REPL, or its “read evaluate print loop” functionality, which enables users to iterate on their problems quickly and easily. “If you have a bunch of data scientists and you’re trying to figure out what they want to do, and they need to play around a lot, then Spark may be a better solution for those sorts of cases,” Oliver says.
Dataflow is Google’s all-encompassing platform for uniting streaming, interactive, and batch analytics
While Spark maintains an edge among data scientists looking to iterate quickly, Google Cloud Dataflow seems to hold the advantage in the operations department, thanks to all the work that Google has done over the years to optimize queries at scale. “Google Cloud Dataflow has some key advantages, in particular if you have a well thought out process that you’re trying to implement, and you’re trying to do it cost effectively…then Google Cloud Dataflow is an excellent option for doing it at scale and at a lower cost,” Oliver says.
There are operational concerns in Spark that users should be aware of, Pointer says. “It has been getting a lot better in the last few versions, but there’s normally a lot of tweaking that goes on in order for you to pull the best out of it,” he says. “The Dataflow engine use the last two decades of research that Google has done to determine just exactly how to run your job in the most performant manner. You don’t have to worry about that, whereas if you’re running a Spark closer yourself, you do have to worry about that.”
There are cloud-based Spark clusters available too, with the service offered by Apache Spark backer Databricks among the most prominent. The folks at Databricks are proud of how they can optimize Spark, and event tweak the underlying framework, to increase performance. Since Dataflow isn’t open source, there’s really no way to make a direct comparison.
This makes picking a cloud provider tricky, says Oliver. “You may get cheaper cloud support from one vendor than another, but you may find your own operational costs are higher as a result,” he says. “We’ve been able to give you one more data point, which is the performance of [Google Cloud Dataflow] versus Spark to help people start to make some of these hard choices.”
Cold War of Tech
But in one very important respect, we all come out winners.
“This is a very much a cold war,” Oliver says. “A lot of people may complain about the number of options out there. But at the moment, this is benefiting everyone. The technology is evolving quickly, maturing quickly, and the operational features of these technologies are quickly maturing.”
In particular, Oliver points to Apache Beam–the open source implementation of the Google Cloud Dataflow API–as proof that we are all benefiting from the big data wars that are waging right now. Since Beam supports Spark, as well Apache Flink via “runners,” users may be taken off the hook in their tech decision-making.
“So whether or not you end up using Google Cloud Dataflow, you’re benefiting from its existence, at least indirectly, because now we have Apache Beam,” Oliver says. “I think Beam has a good chance to be that unifying API that gives us a nice way to write it once run it on three or four different engines on two or three cloud infrastructures, and pick the best one.”
Related Items:
Apache Beam’s Ambitious Goal: Unify Big Data Development
Google Reimagines MapReduce, Launches Dataflow
Google Releases Cloud Processor For Hadoop, Spark
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States