


April 22, 2016
Apache Beam’s Ambitious Goal: Unify Big Data Development
If you’re tired of using multiple technologies to accomplish various big data tasks, you may want to consider Apache Beam, a new distributed processing tool from Google that’s now incubating at the ASF.
One of the challenges of big data development is the need to use lots of different technologies, frameworks, APIs, languages, and software development kits. Depending on what you’re trying to do–and where you’re trying to do it–you may choose MapReduce for batch processing, Apache Spark SQL for interactive queries, Apache Flink for real-time streaming, or a machine learning framework running on the cloud.
While the open source movement has provided an abundance of riches for big data developers, it has increased pressure on the developer to pick “the right” tool for what she is trying to accomplish. This can be a bit overwhelming for those new to big data application development, and it could even slow or even hinder adoption of open source tools. (Indeed, the complexity of having to manually stitch everything together is perhaps the most common rallying cry heard by backers of proprietary big data platforms.)
Enter Google (NASDAQ: GOOG). The Web giant is hoping to eliminate some of this second-guessing and painful tool-jumping with Apache Beam, which it’s positioning as a single programming and runtime model that not only unifies development for batch, interactive, and streaming workflows, but also provides a single model for both cloud and on-premise development.
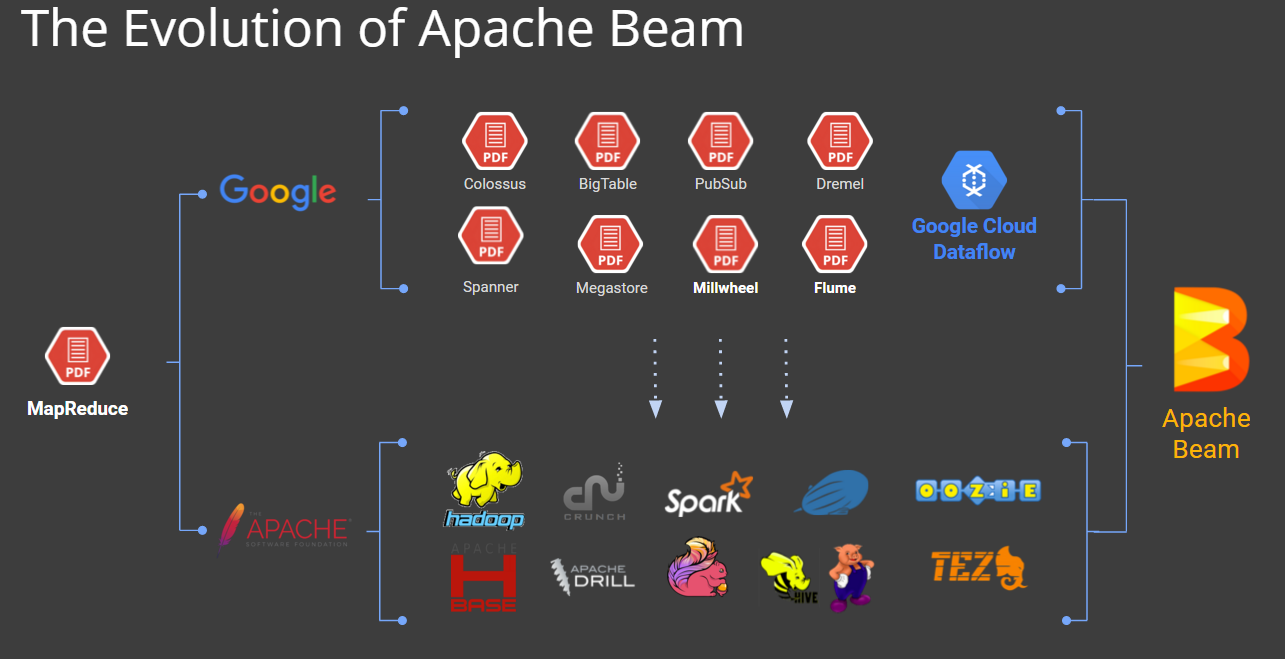
The software is based on the technologies Google uses with its Cloud Dataflow service, which the company launched in 2014 as the second coming of MapReduce for the current generation of distributed data processing challenges. (It’s worth noting that FlumeJava and MillWheel also influenced the Dataflow model).
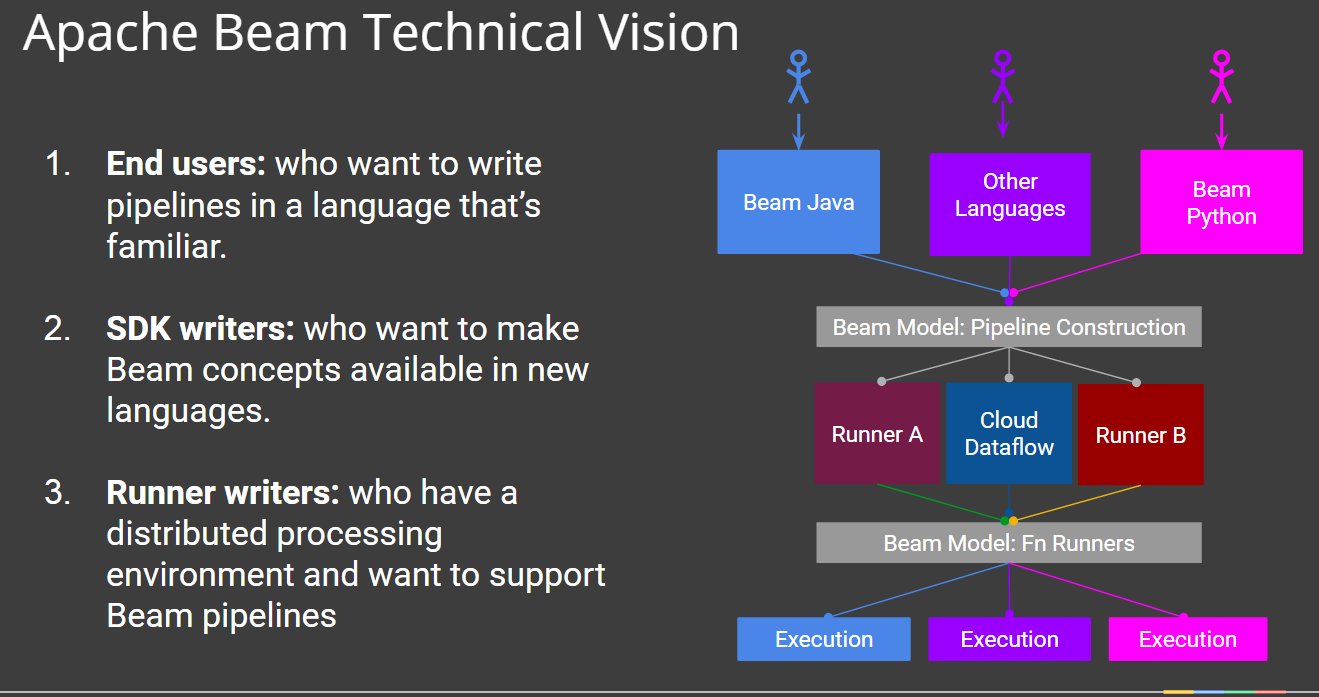
The open source Apache Beam project essentially is the combination of the Dataflow Software Development Kit (SDK) and the Dataflow model, along with series of “runners” that extend out to run-time frameworks, namely Apache Spark, Apache Flink, and Cloud Dataflow itself, which Google lets you try out for free and will charge you money to use in production.
Apache Beam provides a unified model for not only designing, but also executing (via runners), a variety of data-oriented workflows, including data processing, data ingestion, and data integration, according to the Apache Beam project page. “Dataflow pipelines simplify the mechanics of large-scale batch and streaming data processing and can run on a number of runtimes like Apache Flink, Apache Spark, and Google Cloud Dataflow,” the project says.
The project, which was originally named Apache Dataflow before taking the Apache Beam moniker, is being championed by Jean-Baptiste Onofré, who is currently an SOA software architect at French data integration toolmaker Talend and works on many Apache Software Foundation projects. Joining Google in the project are data Artisans, which developed and maintains the Beam runner for Flink, and Cloudera, which developed and maintains the runner for Spark. Developers from Cask and PayPal are also involved.
Onofré describes the impetus behind the technology in a recent post to his blog:
“Imagine, you have a Hadoop cluster where you used MapReduce jobs,” he writes. “Now, you want to ‘migrate’ these jobs to Spark: you have to refactore [sic] all your jobs which requires lot of works and cost a lot. And after that, see the effort and cost if you want to change for a new platform like Flink: you have to refactore [sic] your jobs again.
“Dataflow aims to provide an abstraction layer between your code and the execution runtime,” he continues. “The SDK allows you to use an unified programming model: you implement your data processing logic using the Dataflow SDK, the same code will run on different backends. You don’t need to refactore [sic] and change the code anymore!
There are four main constructs in the Apache Beam SDK, according to the Apache Beam proposal posted to the ASF’s website. These constructs include:
- Pipelines–the data processing job made of a series of computations including input, processing, and output;
- PCollections–Bounded (or unbounded) datasets which represent the input, intermediate and output data in pipelines;
- PTransforms–A data processing step in a pipeline in which one or more PCollections are an input and output;
- and I/O Sources and Sinks–APIs for reading and writing data which are the roots and endpoints of the pipeline.
“Beam can be used for a variety of streaming or batch data processing goals including ETL, stream analysis, and aggregate computation,” the . The underlying programming model for Beam provides MapReduce-like parallelism, combined with support for powerful data windowing, and fine-grained correctness control.
Many of the concepts behind Beam are similar to those found in Spark. However, there are important differences, as Google engineers discussed in a recent article.
“Spark has had a huge and positive impact on the industry thanks to doing a number of things much better than other systems had done before,” the engineers write. “But Dataflow holds distinct advantages in programming model flexibility, power, and expressiveness, particularly in the out-of-order processing and real-time session management arenas…. The fact is: no other massive-scale data parallel programming model provides the depth-of-capability and ease-of-use that Dataflow/Beam does.”
Portability of code is a key feature of Beam. “Beam was designed from the start to provide a portable programming layer,” Onofré and others write in the Beam proposal. “When you define a data processing pipeline with the Beam model, you are creating a job which is capable of being processed by any number of Beam processing engines.”
Beam’s Java-based SDK is currently available at GitHub (as well as on Stack Overflow), and a second SDK for Python is currently in the works. The developers have an ambitious set of goals, including creating additional Beam runners (Apache Storm and MapReduce are possible contenders), as well as support for other programming.
Beam developers note that the project is also closely related to Apache Crunch, a Java-based framework for Hadoop and Spark that simplifies the programming of data pipelines for common tasks such as joining and aggregations, which are tedious to implement in MapReduce.
Google announced in January that it wanted to donate Dataflow to the ASF, and the ASF accepted the proposal in early February, when it was renamed Apache Beam. The project, which is in the process of moving from GitHub to Apache, is currently incubating.
“In the long term, we believe Beam can be a powerful abstraction layer for data processing,” the Beam proposal says. “By providing an abstraction layer for data pipelines and processing, data workflows can be increasingly portable, resilient to breaking changes in tooling, and compatible across many execution engines, runtimes, and open source projects.”
Related Items:
Apache Flink Creators Get $6M to Simplify Stream Processing
Google Releases Cloud Processor For Hadoop, Spark
Google Reimagines MapReduce, Launches Dataflow
Technologies:
Frameworks
Sectors:
Other
Leading Solution Providers
















