

July 12, 2022
ScyllaDB Announces Latest Release of Its NoSQL Database
ScyllaDB has announced ScyllaDB V, the latest release of its NoSQL database that includes new features for its DBaaS, Scylla Cloud, as well as Scylla Enterprise and Scylla Open Source.
ScyllaDB says today’s new release “introduces a host of performance, resilience, and elasticity enhancements” meant to enable real-time performance for extreme scale datasets and can be scaled for use from gigabyte to petabyte scale.
The company also says these extreme scale enhancements are ScyllaDB’s next step in solving lingering challenges presented by legacy NoSQL databases (like Apache Cassandra and Amazon DynamoDB) and notes that modern data infrastructure is fundamentally different from a decade ago when many NoSQL databases were designed. Organizations now have increased access to more computing power, including servers with an abundance of CPUs, RAM, I/O, and NVMe storage. ScyllaDB asserts its database is uniquely built to capitalize on these hardware innovations to ramp up performance while using less of these infrastructure resources, resulting in less administrative management and a lower total cost of ownership.
“We not only anticipated this shift; we architected for it from the start,” said Dor Laor, CEO and co-founder of ScyllaDB. “That’s why we’re so uniquely well-poised to tap the power of new technology such as AWS I4is and Nitro SSD storage. ScyllaDB V marks an inflection point in the evolution of NoSQL – away from its roots in cloud-nascent infrastructure, and towards the future of low-latency, real-time distributed systems.”
ScyllaDB’s enterprise users include Comcast, Disney+, Starbucks, Instacart, and Discord, and the company mentions that Comcast recently experienced cost savings when it went from 962 Apache Cassandra nodes to 78 ScyllaDB nodes. Additionally, the company announced in April that its database is now available on AWS Marketplace.
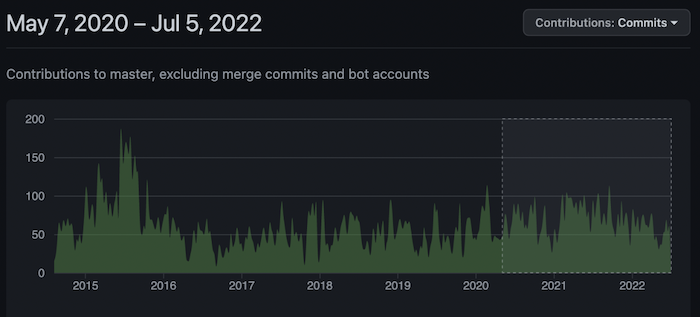
This graphic shows the number of commits to ScyllaDB/Scylla on Github, with the period since ScyllaDB Open Source 4.0 was released in May 2020 highlighted. Note that there are between 50 to 100 new code commits most weeks, and at times the company has exceeded 100 code commits per week. Source: ScyllaDB
The company lists the following highlights of ScyllaDB V’s new capabilities:
- Strong, immediate consistency for schema updates, topology changes, tables and indexes, and more. This eliminates schema and data conflicts, enables rapid and safe, increases in cluster capacity, and provides a leap forward in manageability, central to the ScyllaDB Cloud (DBaaS) strategy.
- New IO model and scheduler provide fine-tuned balancing of mixed read/write requests based on the disk’s capabilities. This boosts throughput, reduces latency, and minimizes the impact of admin operations. It also reduces latency for real-time requests while running admin operations like scaling out.
- AWS EC2 I4i support with 2X the throughput (and lower latency) vs i3 instances on the same number of vCPUs.
- A fully asynchronous Rust driver that will serve as a unified platform for other drivers going forward. Like the Rust programming language and the Tokio framework, ScyllaDB is built on an asynchronous, non-blocking runtime that enables building highly-reliable, low-latency distributed applications.
- WebAssembly for user-defined functions, which means that creating a UDF is as easy as providing its source code represented in WebAssembly Text Format. Wasm is a candidate for a user-defined functions (UDFs) back-end due to its ease of integration, performance, and popularity. This support is based on an open-source runtime written natively in Rust: Wasmtime.
As the first delivery of ScyllaDB V, the company released Scylla Open Source 5.0 for immediate availability. Features will be available in Scylla Enterprise and Cloud at a later date. In a blog post describing the new open source release, Tzach Livyatan explains the company’s progress since the 4.0 release back in May 2020, naming the past two years its most consistently productive era of coding with 7,720 code commits and 2,002 issues closed on Github. ScyllaDB will be hosting a webinar on July 19 for an in-depth look at the 5.0 release’s new features and capabilities.
The company also published a whitepaper on its petascale benchmarks for ScyllaDB that includes its configuration progress, results with and without workload prioritization, and lessons learned. The paper can be found here.
Related Items:
There’s a NoSQL Database for That
ScyllaDB Now Available on AWS Marketplace
ScyllaDB Announces Scylla Enterprise 2020
Applications:
Enterprise Analytics
Vendors:
ScyllaDB
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States