

July 22, 2021
There’s a NoSQL Database for That

(whiteMocca/Shutterstock)
While relational databases still dominate IT budgets, many new development projects are turning to NoSQL databases, which have emerged in recent years to serve all sorts of interesting use cases. Relational databases will be around for many years, but NoSQL databases today are giving their relational cousins a run for their money, which is a great benefits to users.
Databases, in one form or another, have been around for the past 60 years. In 1970, E.F. “Ted” Codd proposed the relational model of data, which centers around the idea of grouping data by content as the first-order principle. Four years later, Donald Chamberlin and Raymond Boyce proposed Structured Query Language (SQL) as a way to query data in a relational database.
These core elements–the relational database management system (RDBMS) and SQL–have proven quite powerful, and have been the foundation of a huge number of applications and computer systems. With proven relational algebra providing a solid foundation, it’s not a stretch to say that trillions of dollars have invested in relational technology. It’s literally the backbone of IT as we know it.
Well, as we used to know it, anyway. By the early 2000s, the limitations of the relational model–such as strict schemas and strong consistency–along the explosion of data and data types led architects to begin exploring alternative data models. This was the beginning of the NoSQL movement, which avoided the strict requirements of the RDBMS/SQL line to give developers and architects greater freedom to store and recall data in new and innovative ways.
There are four main types of NoSQL database. This includes:
Key-Value Stores
The most basic of the NoSQL databases is the key-value store, which is composed of a key and an associated data value (which can be a number, a string, or even another set of key-value pairs). While key-value stores lack much of the sophistication of RDMBS (such as pointers), the simplicity lends itself to speed and performance gains over RDBMS.
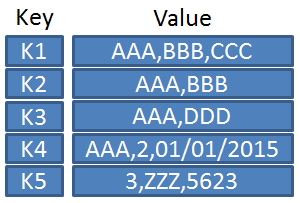
Key-value stores are the simplest databases (Image courtesy Clescop)
Many key-value stores are designed to run entirely in memory, while others can work on solid-state drives or traditional hard drives. Thanks to their basic structures, key-value stores are amenable to scaling horizontally.
Key-value stores are used primarily when the customer requires high performance for serving queries on read-only data, such as for large, heavily trafficked websites. There is no query language for key-value stores, instead using basic CRUD (create, retrieve, update, and delete) commands. Popular key-value stores are Memcached, Redis, RocksDB, and Riak. Key-value stores also form the foundation for other NoSQL databases that can offer multiple database modalities, called multi-model databases.
Wide-Column stores
One step up the complexity ladder from the key-value store is the wide-column store. Like an RDBMS, wide-column stores use rows, columns, and tables to store data, but unlike relational system, the columns can vary from row to row in the same table in a wide-column store. The column names can also be changed as needed, which provides a level of schema flexibility that does not exist in an RDBMs. One way to think of wide-column stores is as a two-dimensional key-value store.

Wide-column stores resemble two-dimensional key-value stores (Image courtesy Michael-Joseph-Mior)
One key characteristic of a wide-column store is the ability to store a large amount of data in a single column, which can significantly speed up data access times and minimize resource usage for returning database queries. This makes wide-column stores popular for write-heavy uses cases such as storing log data, IoT data, time-series data, and data that describes attributes (such as temperatures or financial trading). Wide-column stores often have a query language associated with them. This database family is also amenable to distributed architectures, in which data is sharded across nodes in a cluster, making them suitable for petabyte-scale data sets and beyond.
Google’s Bigtable is the grandfather of the wide-column store family. Other databases in this type include Apache Cassandra, Accumulo, HBase, CosmosDB, and Scylla. DataStax, which backs the Apache Cassandra project, sells a commercial version of that database called Datastax Enterprise.
Document Databases
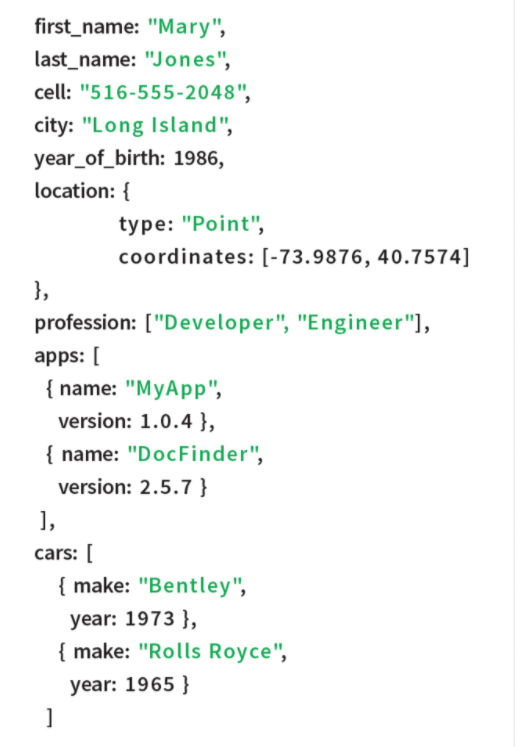
Document stores keep data in JSON-like data structures (Image courtesy MongoDB)
The document database is one of the fastest growing types of NoSQL databases today. It’s a derivation of the key-value store. But instead of storing data in rows and columns, the key value pairs are embedded into a document or a series of documents, which are most often encoded using the JSON data format, or a close derivation thereof (such as BSON).
As with wide-column stores, schema flexibility is a key architectural advantage of the document database, as it allows developers to add new data fields to their applications as needed, without going through the large development exercise required when changing an RDBMS schema. This attribute makes document stores popular for storing data that frequently changes, such as for managing user profiles. Document databases typically have their own query language, some of which closely resemble SQL.
MongoDB is the most widely used document store on the market today, thanks largely to its popularity among Web and mobile application developers. Other popular document stores include Couchbase Server from Couchbase (which IPO’d today), CouchbaseDB, and Microsoft’s CosmosDB.
Graph Databases
At the high end of the complexity spectrum for NoSQL database lies the graph database, which are highly specialized data stores used for storing linked data. Instead of storing data in rows/columns or documents, graph databases use the concept of nodes (for individual entities, such as a person or a thing) and edges that connect that node to other nodes.
There are two main types of graph databases: property graphs, such as Neo4j and TigerGraph; and entity graphs, such as Franz’s AllegroGraph and Apache Jena. Entity graphs are sometimes called triple stores, knowledge graphs, or RDF stores (for Resource Description Framework). Specialized query languages are required to interact with these systems, such as Cypher for Neo4j or SPARQL, which is popular among entity graphs.

Graph databases store data as nodes and edges (Source: Neo4j)
Property graphs have strict schemas, which makes them somewhat an anomaly in the free-floating world of the NoSQL data family. They sometimes run in a distributed manner, but not always. Because the connectiveness of the data is baked into the schema, property graph database are extremely good at complex queries that would require the execution of complex and expensive joins in an RDMBS. While graph databases are analytical in nature, they’re often used in transactional systems, such as for serving recommendations in an ecommerce setting or detecting fraud in payment systems.
Entity graphs offer more schema flexibility than their property graph cousins, and can work with less structured data. Entity graphs are often used to store interlinked descriptions of entities, including abstract concepts, and join them with free-form semantics. They’re often used alongside NLP systems, such as for analyzing semi-structured data collected in the healthcare arena.
Multi-Model Databases
While this is not a database type unto itself, multi-model many databases today are becoming multi-modal, which means they can expose different database attribute types, depending on the workload.
Many multi-modal databases are key-value stores at the most basic level, but can shape-shift to resemble a document database, or even a time-series database as needed. Redis is an example of a multi-model database. It is based on a key-value store, but it can also operate as a document or a graph database. Aerospike is another key-value store that can function as a document database.
However, not all multi-model databases are NoSQL databases. Many of the biggest RDBMSs, such as Oracle, Db2, and SQL Server, can expose themselves differently, such as by offering the ability to store JSON data, which make them multi-modal databases.
The world of databases moves quickly. In recent years, much of the development has been focused on NoSQL databases, which have delivered the capability and the capacity to handle a range of new use cases created by the big data revolution.
Related Items:
Who’s Winning the Cloud Database War
Database Shift to the Edge Accelerates
Database Migrations Shift Into High Gear
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States