

July 12, 2021
Cost Overruns and Misgovernance: Two Threats to Your Cloud Data Journey

(TierneyMJ/ Shutterstock)
So you’re moving data into the cloud. That’s great! After all, cloud compute and storage can supercharge your organizations’ digital strategy. But you should also be aware of new challenges that you will face, including unexpected cloud fees and the difficulty of governing data as it traverses on prem, cloud, and edge locations.
These are some of the conclusions of a recent IDC survey commissioned by Seagate titled “Future-Proofing Storage,” which surveyed 1,050 American tech executives at companies with over 1,000 employees.
Among the more eye-catching statistics to come out of the survey was this: 99% of respondents said they incur planned or unplanned egress fees at least on an annual basis. Companies are moving lots of data to lots of different places, and it’s accelerating.
“This is the new model,” says Rags Srinivasan, the senior director of growth verticals at Seagate. “In this data age, what you see is data is not just going to stay in one place. It moves from edge to cloud, even from cloud to a private cloud or to another cloud where it needs to be. The data is in motion.”
On average, the egress fees accounted for 6% of the monthly bill from cloud providers, according to the survey. While the report didn’t specify what percentage of the fees were unexpected, egress fees in general are “a huge concern,” Srinivasan says.
“When you look at the number one concern for most of them, they don’t know yet what the egress charge is going to be,” he tells Datanami. “They may not have come to a point [or] unlocked the use cases that requires them to get the data. So it’s going to come as an unplanned or surprising charge.”
None of the major public cloud providers charge anything for moving data into their clouds, but they all charge to move data out. Microsoft Azure charges the least: $0.087 per GB for up to 10 TB per month. Amazon Web Services charges $0.09 for the same amount, and Google Cloud charges $0.12.
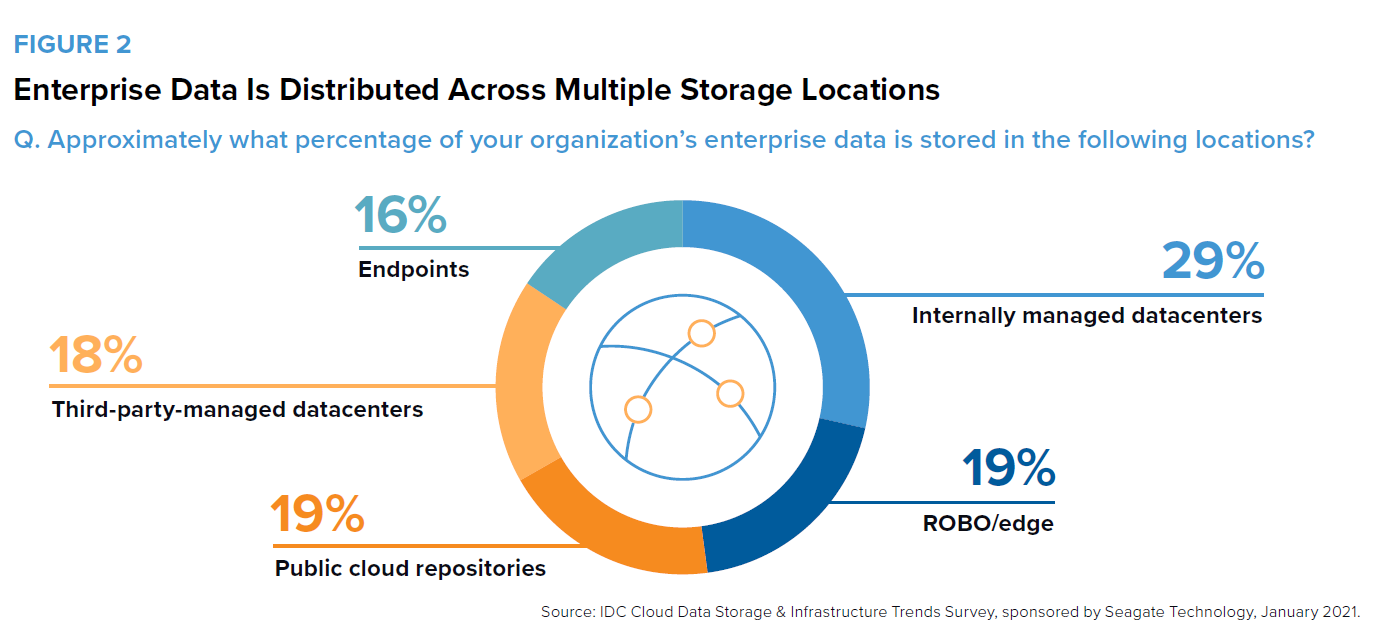
Data is stored across locations (Source: Future-Proofing Storage; IDC, April 2021)
Cloud storage and data egress fees make up just part of the monthly bill that organizations receive from their cloud providers. The companies charge differently for the various compute instances they provide. And if you use a premium service, such as Google Cloud Big Query or Azure Synapse Analytics, there will be additional fees on top of that.
Organizations need to better understand not only how they’re storing the data, but how they’re accessing their data. Cloud providers will charge differently depending on where the data is stored and what APIs are used to access it. It is not always directly obvious, so organizations should plan some time to plot it out to avoid any surprises, Srinivasan says.
“When you go look at the cloud, there are multiple tiers,” he says. “Which one do I pick? Do I pick one based on the price? But then it comes with restrictions, like if you want to access the data, you need to wait for four hours. Or if you want to analyze the data, it needs to be moved to a different tier, which costs a different price.”
Your CIO may desire to have all of your applications running in containerized microservices in the cloud, and pull the data out through REST APIs. That is a worthy goal, if not a perfect fit for every application type.
Moving to the cloud is a great time to reassess the architecture of your data empire and, if possible, do some strategic pruning and re-development work, especially for on-prem applications that were developed over the course of years, if not decades.
Quoting his former CIO, Srinivasan says: “Moving to the cloud is not just picking up and going,” he says. “You need to do a refactoring of your architecture. You first need to look at where is all my data stacked. How many complex workflows” do I have?

Data is on the move (Source: Future-Proofing Storage; IDC, April 2021)
Things are easier if you’re deploying a brand-new application in the cloud. It’s a no-brainer today to make it a containerized microservice that seeks data stored in modern object store, database, or file system. The hard part is re-thinking the application design when moving legacy apps to the cloud.
“Yes, I can unlock a use case quickly if it is completely a born-in-the-cloud workload,” Srinivasan says. “But in shifting workloads from your private cloud or your data closets, you need that architectural discipline.”
Once you have gone through that re-architecting exercise and re-organized your application and data estate, then you will have a much easier time of managing that data going forward, whether it’s on prem, in the cloud, or somewhere in between.
The other major takeaway from the IDC survey is the looming challenge of managing and governing all this data as it flows from the edge to the core, from on-prem to the public cloud, from end-points to third-party data centers, and everywhere in between.
The average enterprise expects their stored data to grow 30% annually, IDC says. “Using this growth rate as a general guide, we can assume that an organization managing 50PB of data today will store upwards of 65PB of data the following year,” it says. “The challenge with this data growth trajectory is that spending on IT infrastructure is only expected to grow in the single digits (and may even remain flat for many enterprises).”
Keeping on top of that growing data empire will be challenging–and expensive. One out of five tech execs say they’re already spending $1 million annually on storage. With data growing 30%, just managing that data to keep the lights on–let alone doing innovative and transformative things with it–will require a balancing act.
IDC found that, on average, data transfers amounted to 140TB per transaction. But there is so much data being generated that 78% of organizations say they can’t rely on the Internet or private networks anymore, and so they transport data on physical media. The average size of data transfers for these transactions is a whopping 473TB of data, the survey found.
The data volumes are growing, particularly around image data, Srinivasan says. The IDC DataAge survey estimates that 175 zettabytes of data will be created by 2025. We’re only keeping about one-third of the data we create now, Srinivasan says. As cloud storage becomes more ubiquitous and use cases keep appearing, more of that data will be kept, which underscores the need for better data management, including data governance.
“What they need is a data sovereignty policy, a better management policy,” Srinivasan says. “If they have the policy, there is value in the data.”
Related Items:
What’s Holding Us Back Now? ‘It’s the Data, Stupid’
A Peek At the Future of Data Management, Courtesy of Gartner
Data Management Self Service is Key for Data Engineers–And Their Business
Technologies:
Cloud
Sectors:
Financial Services
Tags:
cloud, data egresss, edge, governance, misgovernance, multi-cloud, on-prem, silos, storage, unexpected costs
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States