

January 22, 2021
Kyligence Doubles Down on Cubes in the Cloud

(arlekse/Shutterstock)
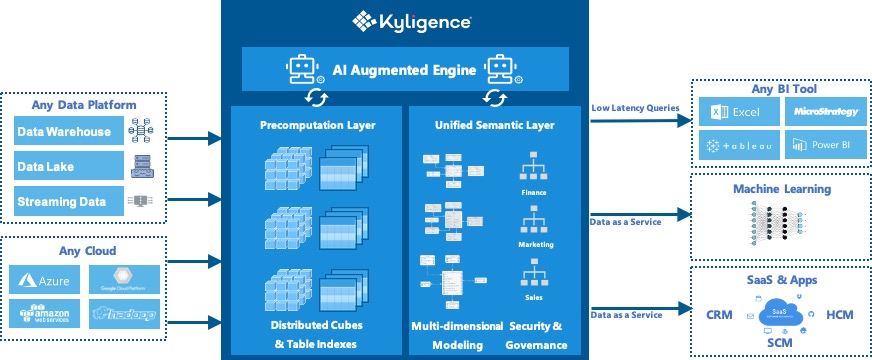
Multidimensional analysis, or the use of pre-computed OLAP cubes, used to be a primary method for quickly obtaining useful information from reams of data, but has largely fallen out of favor in the age of big data and big compute. Now Kyligence is hoping to shake off OLAP’s baggage and resurrect the benefits of pre-computing aggregates with a new offering based on modern cloud components.
Kyligence is the commercial vendor behind Apache Kylin, the open source OLAP software project that emerged in 2013 from eBay’s development lab in Shanghai, China. Kylin originally was developed to run atop the Hadoop ecosystem, and made extensive use of components like HBase and Hive.
With yesterday’s launch of Kyligence Cloud 4, those Hadoop components have been eradicated from the stack, and the result is a distributed OLAP engine based on Apache Spark that pre-aggregates commonly used fields for data residing in popular cloud data warehouses and data lakes, thereby accelerating the processing of queries from popular BI clients.
Li Kang, head of North America for Kyligence, recently explained to Datanami how Kyligence Cloud 4 (KC4) works:
“You will have what we call a query cluster in the cloud. That’s basically a cluster of Spark nodes that will handle the customer query. And the customer query is coming in the format of ANSI SQL or you can use MDX. We also accept Rest API calls,” he said.
“There’s another part that’s called the field cluster, which is basically where we precompute the aggregate index, or the equivalent of the cube. And that is very flexible,” Kang continued. “When you’re not building the cube, you don’t need this cluster. When we start a new cubing job, we’ll spin up that cluster. If you have more data, you can scale up or down that cluster.”
The KC4 clusters deploy on VMs residing in the customer’s AWS or Microsoft Azure environments, or VPC environments. As user demand increases, customers can scale up the two clusters via their cloud VMs. Kyligence is currently working to containerize the server components, which is expected later this year.
Speed is the name of the game with multi-dimensional analysis. Despite the progress made with cloud data warehouses like Snowflake and the federated data lake approaches espoused by in-memory systems like Presto and Dremio, these approaches simply cannot deliver the results of complex ad hoc queries in a speedy manner, Kang says.
“Say I need to analyze my sales number across regions, across different time windows, and then I need to add attributes like the color or size of the product,” he said. “You can easily analyze across 10, 20, 30 different attributes. When you run that kind of query, it’s not the lookup of the record from the data warehouse that’s the bottleneck. The bottleneck is aggregating the results, analyzing based on these different attributes, and coming up with the final answer.”
For example, if a retail company wanted to quantify sales of white 24-inch monitors in the Seattle area across the segment of customers who are males in their 30s with household income over $70,000 per year, that SQL query would churn for some time in a traditional column-oriented database, as it fetches the data and aggregates the results.
“If you need to calculate that information, even if it’s in-memory, it takes way more than a couple of seconds,” Kang said. “There’s no good solution. If you look at all those data warehouse product demos, they run very simple queries, and they’ll tell you, look I’m getting the result back from a petabyte of data, or billions of records, within a second. But if you look at those queries, they are very straightforward.”
Kyligence aims to return complex queries from the underlying data warehouse or data lake within two to three seconds, which includes back-end processing as well as screen-refresh time, Kang said. That makes the product usable to business analysts who are searching for useful patterns or anomalies hidden within terabytes or petabytes of data.

Multi-dimensional databases can pre-compute aggregates, delivering faster response times to ad hoc queries (Image courtesy Kyligence)
Many of Kyligence customers have cubes that contain hundreds of terabytes of data, which represents hundreds of billions of rows of data. Its largest customer is running millions of queries on a cube that is larger than 1PB.
One of Kyligence’s biggest customers is UBS, which uses Kyligence to analyze worldwide transactions to keep on top of its risk profile. The Swiss bank gets close to a billion new records every day, and its model is updated every couple of hours to ensure the transactions are not adding too much risk, Kang said.
UBS is a Microsoft Azure shop, and used to run Microsoft’s SQL Server Analysis Services (SSAS), which was a multidimensional OLAP (MOLAP) product. But Microsoft has not gone down the MOLAP route with its current Azure Synapse offering, and that offering cannot handle the scale that UBS demands, Kang says.
“It used to be on SSAS, and they realize, they just can’t do that with Synapse,” he says.
In addition to eliminating dependencies on Hadoop, Kyligence has added new intelligent indexing routines with KC 4.
Pre-aggregating cubes and storing the results on spinning disk (or SSDs) obviously comes at a cost, including the storage and compute required to maintain the cube and power the queries, so companies must be smart about which fields they choose to include in the cube. With KC4, Kyligence has adopted AI to offer recommendations on which pieces of data to include in the cubes, which are stored as Parquet files on S3 or ADLS.
“This AI engine addresses one of the biggest pain points of previous generation of cubing technology: the learning the curve to get started,” Kang said. “You don’t need to be a multi-dimensional expert” to use KC4.
In the old days of multi-dimensional databases, it could often take weeks or months to come up with a good data model. It would often involve a multi-dimensional expert interviewing the analysts to figure out what data they use, and analyzing thousands of query histories to see what they’re currently doing.
Kyligence aims to deliver 90% of user queries within three seconds (Image courtesy Kyligence)
KC4’s new AI system does much of that work for the customer. “We can literally do that in a couple of hours,” Kang said. “That’s exactly what we’re doing, whether it’s a POC [proof of concept] or an implementation project. We start with the AI engine, and that saves us several weeks model-building time, or design time. Then from there we can continually optimize the model, depending on the user load and the query workload and user behavior.”
Kyligence has some other things in the works, including a new real-time data loading feature that will leverage Apache Kafka to keep the cube continuously updated with fresh data. That offering, which will only update the “hot” section of the cube (and rely on periodic routines to reconcile the hot and warm segments), will have a latency of just a few seconds, and is expected to be in beta by the end of the first quarter.
The company, which has dual headquarters in Shanghai and San Jose, is gaining traction in financial services, which typically has the biggest and toughest data problems to solve. It also has customers in retail, high tech, healthcare, and manufacturing. The company’s customer base skews toward Chinese firms, as a result of its heritage, but it’s also making inroads in the United States, where Apple, Microsoft, and Amazon are all enterprise customers of Kyligence, Kang said.
“The financial service customers are very excited. They obviously invest a lot into this kind of technology, so it’s very exciting,” Kang said. “We also provide a cost advantage. Instead of using a cloud data warehouse, where every time your customer is looking at dashboard or clicking on the dashboard, that’s a new query and it will cost you extra dollars. For us, you build it as a pre-computation once and they can query it however many times they want to and there’s no extra cost.”
In addition to the AI modeling, the enterprise version of Apache Kylin that Kyligence sells brings user interface and security advantages. The company plans to push some of the new features it has developed into the open source project, which is used by more than 1,000 companies, but for now they are only available in the enterprise version, Kang said.
Related Items:
Kyligence Grows OLAP Business in the Cloud
Cloud Is the New Center of Gravity for Data Warehousing
Presto Poised for a Breakout Year as Data Explosion Continues
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States