

January 8, 2021
Cloud Is the New Center of Gravity for Data Warehousing

(Funtap/Shutterstock)
The great migration of data into the cloud didn’t start in 2020, but it certainly accelerated throughout the year. And according to a new survey from IDG, the overwhelming majority of companies are planning to expand their investments in cloud data warehouses and data lakes in 2021. However, many of the same old challenges surrounding data management and ETL remain the same.
The IDG survey, which was released in September, found that 77% of IT decision-makers plan to migrate to a cloud data warehouse, or expand an existing cloud data warehouse, over the next six to 12 months. Another 21% have cloud data warehouse plans extending out the next 24 months. Only 1% said they had no plans to implement or expand a cloud data warehouse.
Those numbers stand out, especially considering that only 38% of IDG’s survey-takers (which were director-level and higher decision-makers in BI, analytics, or data science) have a cloud data warehouse today. Thirty percent are running an on-prem data warehouse, the survey found, while 23% use another type of offsite, non-cloud data warehouse.
Clearly, the cloud factors heavily into the 2021 data analytics plans for companies of all shapes and sizes. Cloud data warehouses, such as those offered by Snowflake, AWS, Microsoft Azure, Google Cloud, and Databricks, are gobbling up market share from their on-prem brethren. Outside of these top cloud DW vendors, most (if not all) vendors developing data warehouses for on-prem deployments also offer a cloud option at this point.
While cloud data warehouses clearly are growing fast, less than half of users plan to go all-in with cloud data warehouses, according to the IDG survey, which was commissioned by ETL vendor Matillion.
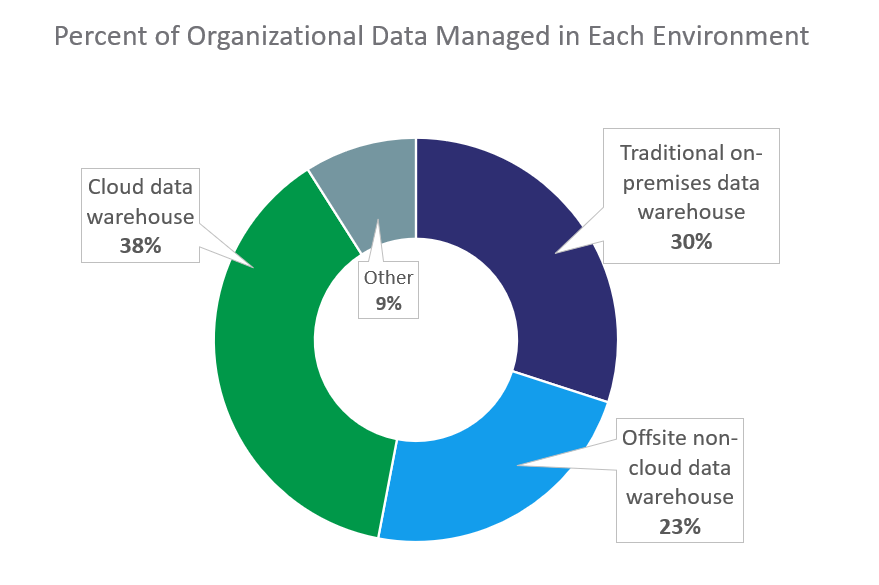
Cloud data warehouse deployments are growing, according to IDG
A hybrid option that mixes on-prem and cloud data warehouse is the data management strategy for 57% of companies, according to the survey, while 22% are targeting a multi-cloud data warehousing approach. Only 21% of companies pursuing a cloud data warehouse strategy are planning to stick with a single cloud provider.
The survey paints a similar story with regards to data lakes, the infinitely scalable and inexpensive data stores that have taken over the role that Hadoop was slated to fill during the last decade. The IDG survey found that, while only 16% of companies are using a data lake today, a whopping 56% of companies are planning to use a data lake in the future, while another 26% of companies are considering using a data lake. Only 2% of survey-takers said they’re not thinking about using a data lake.
While companies are moving trillions of bytes into various cloud repositories, the cloud should not be viewed as a panacea for all data management challenges. IDG reports that it takes a week for data analytic practitioners to get a given data set prepared for analysis. All told, preparing and aggregating data for analysis consumes nearly half of their time (45%), and another 30% is spent exploring and training large models. Only 25% of the time is spent working with models deployed into production.
Matillion Product Director David Langton isn’t surprised that the old analytic gotchas are rearing their ugly heads.
“There’s a number of reasons why that will probably never go away,” he says. “First and foremost, the most interesting analysis and reports you can generate are never from a single data source. You’ve got to integrate the two of them somewhere.”
Cloud data warehouses–and to a lesser extent, cloud data lakes–are where the interesting data are being combined to yield profitable insights for the users, Langton says. Some of the customers have experience doing this on-prem, and are simply taking advantage of the scale that the cloud data warehouses provide, while other customers are just now beginning to partake of it, he says.
“We used to do all of this kind of stuff on premises. We’re now re-imagining it, retooling, and moving the interesting data to the cloud,” Langton tells Datanami. “Customers are very savvy in terms of ‘We know what outcomes we need to drive, and we want to modernize and do it in a new way.’ But the other camp is saying, ‘We can now do this for the first time. It wasn’t feasible before for these use cases and our willingness to pay. But now it is.’ So a lot of net new customers have never done this before.”
As Langton sees it, there’s a lot riding on the specific ETL/ELT tool that customers select to move and transform their data in the cloud repositories. He notes a recent trend whereby vendors will focus primarily on the extract and the load, while leaving the transformation to the data warehouse vendor. Some ETL/ELT vendors support transformations too, but only provide generic transformations.
In Matillion’s case, the company is aiming to provide a full-featured ETL (or rather, ELT) tool that not only extracts and loads, but support the in-database transformations for a variety of different on-prem and cloud data warehouse systems. Maintaining that Switzerland standing–that is, maintaining the flexibility to be able to work with lots of different data types across multiple data destinations–is an important value of the Matillion offering, he says.![]()
“It’s a bit of a differentiator for us,” Langton says. “A lot of the ETL tools will say, we’ve got a standard adapter to read data, a standard adapter to write data, and it’s our own transformation logic in the middle, so you get the benefit that you only have to write transformation logic once. We write transformation logic for each target system that we support in order to optimize it. So we’ll do it in the preferred way on Snowflake or the preferred way on Redshift, rather than treat them all as black boxes and they should all work the same.”
There are many different approaches that can be taken, so flexibility is important. Some data warehouses use a schema-on-read approach (as Hadoop was designed to do), while others enforce a schema as the data is being written into the database. The fact that many cloud data warehouse are being outfitted with federated query processing capabilities that allow them to query data residing in cloud data lakes also adds to the confusion. So does the varying approaches to supporting JSON data types, which typically must be flattened before being queried with a SQL dialect.
All told, however, the tools and technology in cloud analytics have improved tremendously, which is fueling a boost in experimentation as customers figure out what works for them. Customers that are defining their data using a an ETL/ELT tool in the middle have an advantage in being able to easily swap out one data warehouse or lake for another, Langton says.
“Increasingly we see people moving and trying different data warehouses after they’ve become customers and want to try another one,” he says. “Obviously, there are ways we can help migrate. But it does show that people have gone all in and done very big investments on these decision, and then within a few years are ready to refresh and try a new solution.”
Related Items:
Who’s Winning the Cloud Database War
Selecting a Data Lake ETL Platform? Here Are 6 Questions to Ask
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States