

June 22, 2020
Nvidia Destroys TPCx-BB Benchmark with GPUs

Editor’s note: TPC announced on January 27, 2021, that the benchmark tests claimed by Nvidia, as described in this story, are a violation of its fair use policy.
Traditionally, vendors have used CPU-based systems for the TPCx-BB benchmark, which simulates a Hadoop-style workload that mixes SQL and machine learning jobs on structured and unstructured data. So when Nvidia ran the benchmark on its new Ampere class of GPUs system, the results were predictably grim – for CPU systems, that is.
Nvidia today reported unofficial results for two TPCx-BB tests, including the SF1K and the SF10K. For the SF1K test, which simulated a series of queries against a 1TB dataset, the company rolled out a dual DGX A100 systems, comprising a total of 16 A100 GPUs and a Mellanox interconnect. For the SF10K test, which used a 10TB data set, it used a Mellanox interconnect to hook together 16 DGX A100 systems running a total of 128 A100 GPUs.
The results were astounding. On the SF1K test, the Nvidia setup bested the previous record time by 37.1X. On the larger SF10K test, the Nvidia system ran “only” 19.5 times faster.
You can understand why Nvidia would crow loudly about these results. If this was a real-world scenario – and the TPCx-BB is intended to simulate a mixed, real-world workload – then the Nvidia system would have reduced the ML and SQL runtime from 4.7 hours to just under 15 minutes. That’s a significant savings in time, and it would give customers considerably more opportunity to monetize the insights that the system generates.
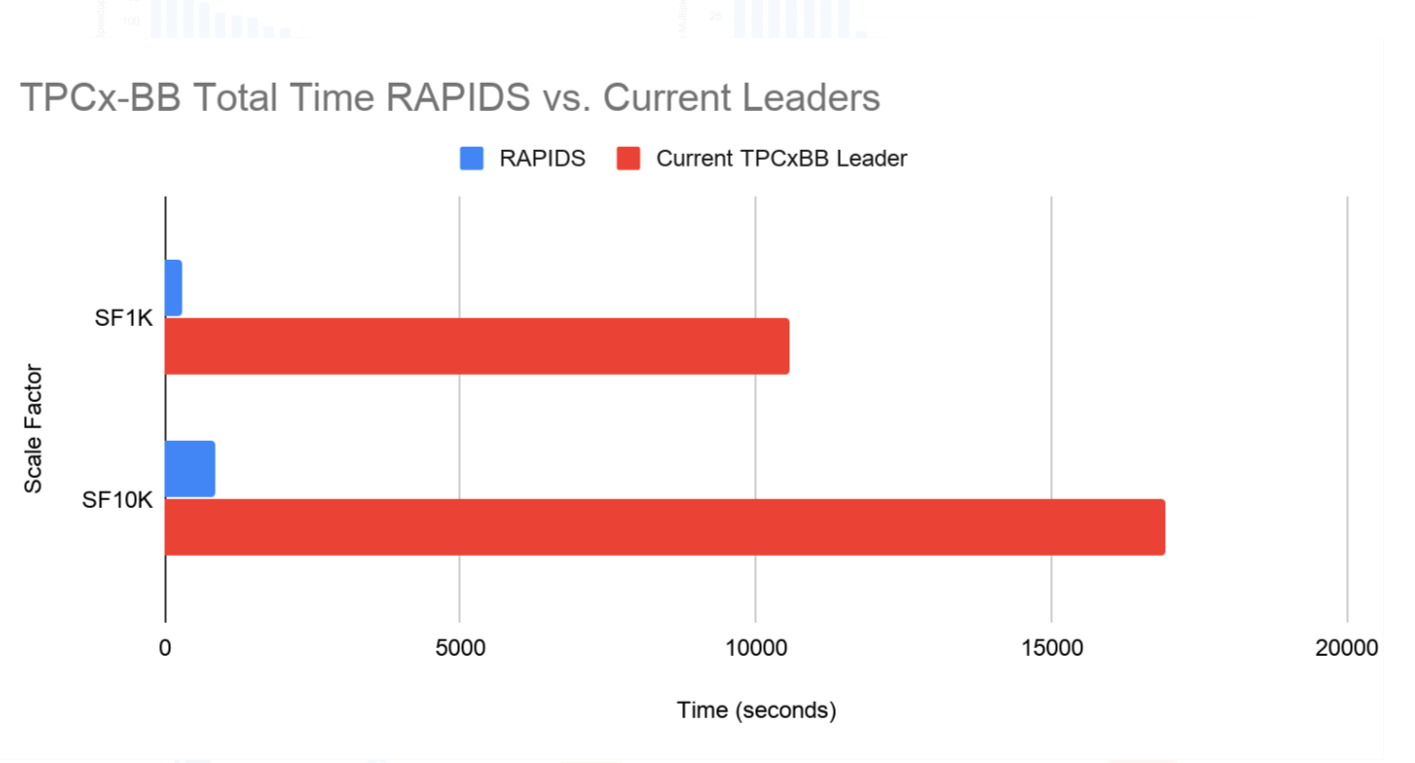
Nvidia systems ran 37.1x and 19.5x faster than the previous record holder for SF1K and SF10K TPCx-BB benchmarks, respectively (Image courtesy Nvidia)
But the Nvidia system isn’t just about achieving wicked-fast results on brand new hardware. According to Paresh Kharya, director of product management for accelerated computing at Nvidia, customers taking the CPU route would have to spend a significant amount more to meet the performance of the DGX A100 system on the SF10K test.
“This implies an equivalent performance of 350 CPU servers, something that could cost over $20 million, having 22 racks, consuming 300 kilowatts of power,” Kharya said. “It can now be replaced by just four racks, costing $3 million and consuming just a hundred kilowatts.”
The Nvidia setup was 7X more cost effective on the SF10K test, Nvidia said. “And that’s why you hear Jensen [Huang, Nvidia’s CEO] say, ‘The more you buy, the more you save,’” Kharya quipped.
The new Ampere GPUs are exciting and get people’s blood flowing. What self-respecting geek doesn’t enjoy seeing so much power come from systems that are so small?
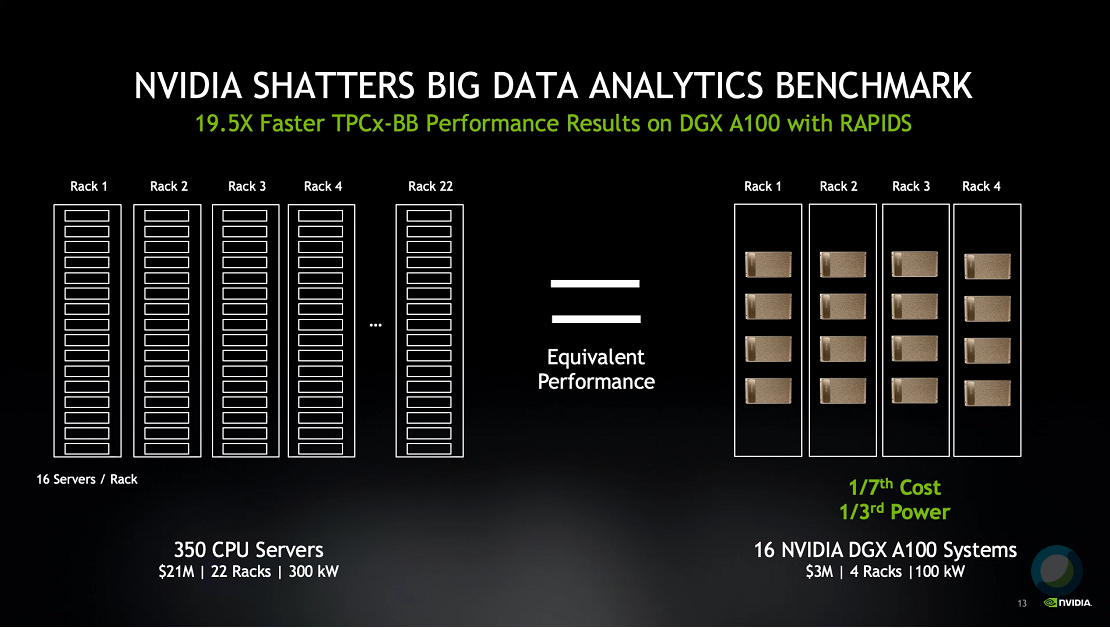
A comparison of CPU- and GPU-based systems (Image courtesy Nvidia)
But the truth is, hardware is just part of the TPCx-BB story. The software side of the equation is also worth spending some time on, particularly because it wasn’t just Nvidia showcasing its RAPIDS data science library, but also because of all the other software from the open source community that Nvidia brought to bear for this specific task.
To explain exactly what Nvidia did, we turn to Nick Becker, who works in data science products at Nvidia, and Paul Mahler, a technical product manager at Nvidia, and authored a blog post on the test.
“We implemented the TPCx-BB queries as a series of Python scripts utilizing the RAPIDS dataframe library, cuDF, the RAPIDS machine learning library, cuML, CuPy, and Dask as the primary libraries,” Becker and Mahler write. “We relied on Numba to implement custom-logic in user-defined functions, and we relied on spaCy for named entity recognition. These results would not be possible without the RAPIDS community and the broader PyData ecosystem.”
Nvidia engineers spent months integrating RAPIDS, BlazingSQL, Dask, CuPy, Numba, and UCX to run these benchmarks, Becker and Mahler write. The software ecosystem was already in place to achieve GPU-powered gains on small land medium-size data sets, they said, but larger data sets in the 10TB range proved challenging, so that’s where the team spent much of its time.
The team focused on several areas in particular. On I/O, the team added support in RAPIDS cuIO, the I/O component of cuDF, for reading and writing Apache Parquet, among other changes. Work on serialization protocols led to better handling of data structues like dataframes and series to be sent over the wire using NVLink.
“We also significantly expanded the set of objects that can be spilled from GPU to main memory through Dask, allowing the largest ETL workflows to use CPU memory as temporary storage when the GPU would otherwise go out-of-memory,” the authors write.
To address network bottlenecks, Nvidia developed UCX-Py, a new Python interface for the high-performance networking library UCX, which allows Dask workflows to take advantage of accelerated networking hardware like NVlink and Mellanox InfiniBand.
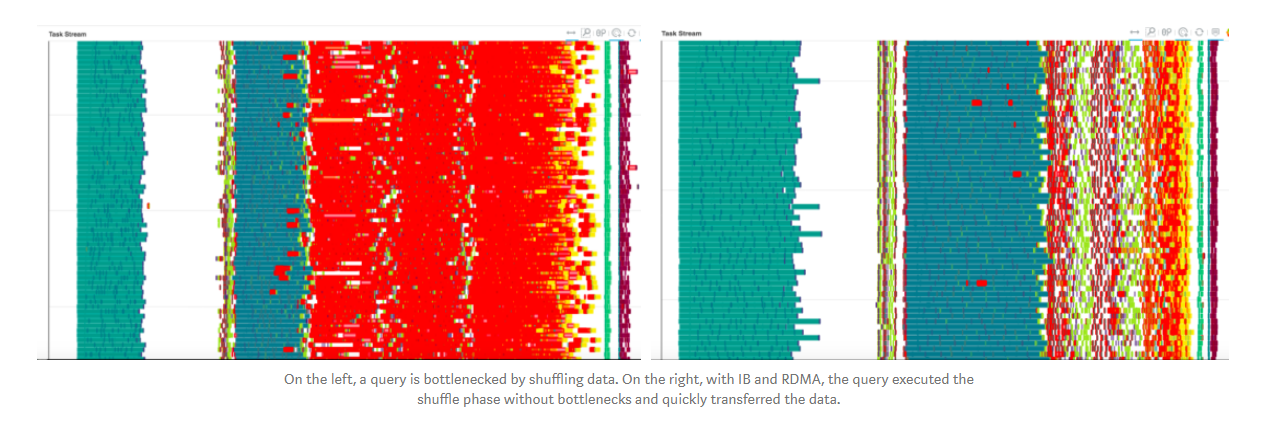
Nvidia’s task stream shows a TCXx-BB query that’s bottlenecked by shuffling data (on the left) versus a query that’s been optimized for InfiniBand and RDMA (on the right)
There was also work done on algorithms themselves, as Nvidia bolstered a range of single-GPU and distributed algorithms to support TPCx-BB queries. Specifically, the company implemented “new and faster multi-column sort and concatenation, hash-based repartitioning of dataframes, a new join type (left-semi join), a hash-based token-occurrence counter, and a Naive Bayes classifier,” Becker and Mahler write.
The work paid off in smashing the TPCx-BB benchmark, which was developed to simulate Hadoop-based big data systems. According to the TPC organization, the TPCx-BB benchmark “measures the performance of both hardware and software components by executing 30 frequently performed analytical queries in the context of retailers with physical and online store presence. The queries are expressed in SQL for structured data and in machine learning algorithms for semi-structured and unstructured data. The SQL queries can use Hive or Spark, while the machine learning algorithms use machine learning libraries, user defined functions, and procedural programs.”
While Hadoop isn’t what it used to be, Spark continues to gain steam, and with last week’s release of Apache Spark 3.0, the Spark community is ready to move into the world of GPUs, with Nvidia’s assistance.
Kharya notes that Rapids is the foundation for GPU acceleration in Spark 3.0, which is the culmination of work between Nvidia and Databricks, the company behind Apache Spark.
“This makes all the revolutionary GPU acceleration for data analytics available to half a million data scientists that use Apache Spark,” Kharya said. “Now data scientists can have a single high performance pipeline from data preparation to model tree. And instead of maintaining two separate clusters, customers can now consolidate the infrastructure and save costs while dramatically accelerating their performance.”
Related Items:
RAPIDS Momentum Builds with Analytics, Cloud Backing
Spark 3.0 to Get Native GPU Acceleration
How Walmart Uses Nvidia GPUs for Better Demand Forecasting
Technologies:
Processors
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States