

April 8, 2020
Neo4j Brings Graph Database and Data Science Together

(Source: Neo4j)
Enterprises that want to use powerful graph algorithms to discover relationships hidden in their data now have an easier path to get there thanks to the new data science library unveiled today by graph database maker Neo4j.
Neo4j is the biggest, oldest, and most successful graph database company in the world. Its eponymous database is relied upon by thousands of organizations to store and expose data in a graph manner, and its Cypher graph query language is used to answer questions in a graph-centric way.
While Neo4j has a smattering of data science use cases, the majority of its customers use the database for transaction processing. The company has offered the capability to run some graph algorithms. But production machine learning use cases typically require data scientists to spend much of time working with open source software that’s external to Neo4j, as well as extensive data engineering efforts to construct a data pipeline to that external system.
Basically, doing data science with Neo4j data has been painful, expensive, and not scalable, according to Neo4j’s lead product manager Alicia Frame. But that all should change with today’s launch of Neo4j for Graph Data Science, which Frame says will make doing data science on Neo4j much easier, less painful, and more scalable than before.
“With the Graph Data Science library, we’re really rolling out a tool that lets people do this very quickly without having to have advanced degrees in math and computer science,” Frame tells Datantami. “We’re democratizing it and putting it in the hands of users.”
Data scientists have been involved with Neo4j, but mostly on the periphery, Frame says. “They see the value of Neo4j,” she says. “But so far what they were mostly able to do … is store their data in the shape of a graph and run graph-based queries. But more intensive data science workloads were things that were happening outside of Neo4j.”
Graph Algos
Frame has first-hand experience with this phenomenon. Prior to joining Neo4j, Frame worked as a data scientist for the federal government, where she worked extensively with the Neo4j database. On one project, data stored as a knowledge graph inside Neo4j had to be extracted and passed to an open source machine learning system. It took 18 engineers to maintain that ETL pipeline.
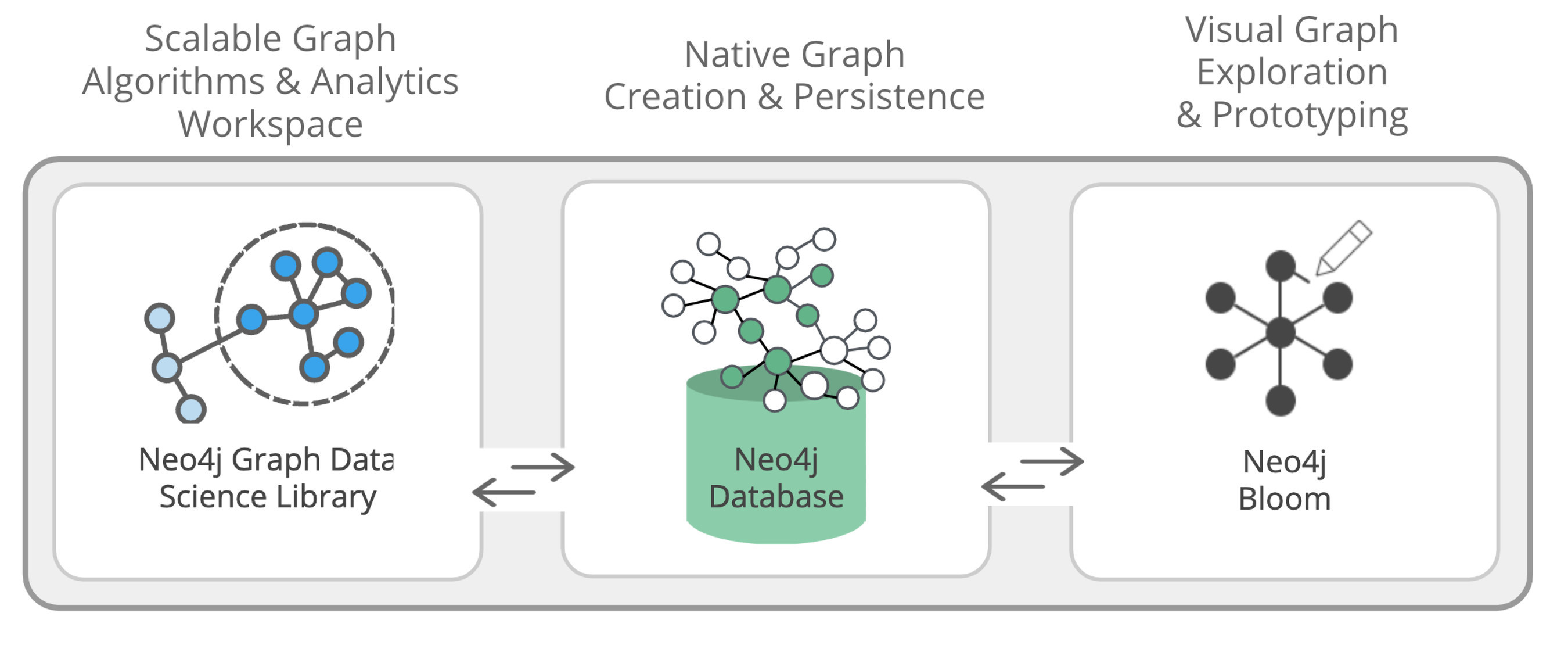
The Neo4j Graph Data Science library is composed of three main parts (Image source: Neo4j)
With the new Graph Data Science library, the data can remain in Neo4j, eliminating the need for extensive data pipelines. “Instead of ‘You need to find this open source library and build this ETL pipeline,’ it’s ‘You’ve got your data in Neo already. You can call this command. It’s at your fingertips. Then you get these numbers.’ It has been really rewarding to see.”
There are several components to Graph Data Science Library, including a graph analytics workspace, a graph database with dozens of graph algorithms, and a graph visualization component called Bloom. The features are written in Java and accessed as stored procedures, which eliminates the need to go outside the library.
The library contains a total of 48 algorithms across five main categories, which are useful for different use cases, Frame says. These include:
- Community detection algorithms, which can be used to detect distinct subgraphs or communities within the larger graph. This class of algorithms are useful for things like customer segmentation and identifying commonalities across users;
- Centrality and importance algorithms, which tell the user how important a given node is based on some assumption of importance. PageRank is an example of this algorithm type;
- Pathfinding and search algorithms, which can calculate the shortest, fastest, or most optimal path to get between A and B in the graph;
- Similarity algorithms, which can detect how close two points in the graph are based on the neighborhoods around them; and
- Link prediction algorithms, which predict how likely there is to be an edge between a given pair of nodes
“We have the five main categories,” Frame says. “Then we built infrastructure around taking your transactional database and reshaping it into these in-memory graphs that we execute the algorithms against. Basically, you can think of them as materialized, in-memory graphs.”
The library allows users to run multiple algorithms against their in-memory graphs to accomplish whatever they need to do. “I can chain multiple algorithms together, and then I can write the results back to the database,” Frame says. “Or, if I don’t need to preserve the results, I can stream the results out to Python and consume them there.”
Features for ML
The new library makes it easy for data scientists to use graph-based machine learning techniques to extract patterns and insights from their data. But that doesn’t mean that Neo4j expects data scientists to do all of their work there.

Neo4j Graph Data Science can be used to build features to train machine learning models (Source: Neo4j)
“Our focus is on using Neo and using the graph to do things that are graph-optimized,” Frame says. “So we’re not running the regression model in Neo4j. We’re running the graph algorithm, which is our category of unsupervised ML methods that can represent certain aspects of your graph topology.”
For example, a data scientist hoping to predict patient outcomes form medical data might use graph techniques to cluster clusters of patients according to certain characteristics, such as age, ZIP Code, race, and gender. She might also use a social graph to determine other people that the patients interact with, including those who might be infected with a disease. The results of these graph algorithms are features that the data scientist could then load into a separate machine learning model. In that sense, Neo4j works with the broader data science community.
“You can extract those metrics and incorporate them into your machine learning pipeline in Python, so you can marry up those graph-based features that are specifically engineered to describe your graph topology with the process you already have,” Frame says. “We want to play to our strengths for a graph database and working out graph calculations. We want to make it easy to do what you’re already doing, and add in the power of graph for the things that graph is best for.”
Enterprise Scale
The Graph Data Science library is based on an open source package of algorithms that Neo4j released as a community project back in 2017. That project gave Neo4j the feedback necessary to create a better, more scalable, and more durable enterprise package that it’s selling now.

Alicia Frame is the lead product manager for Neo4j Graph Data Science
While Neo4j is working on a fully distributed version of its graph database that can run on geographically separated servers, the initial release of Graph Data Science is designed to work on a single-instance machine. Frame and her team are exploring how customers may use the library in a distributed environment, and later this year will come out with a release of the library that’s compatible with the initial release of that distributed database, Neo4j 4.0, which the company shipped in February.
Because the materialized sub-graphs must be held in memory, the data science package runs best on machines with quite a bit of RAM. The algorithms also tax the processors, so a beefy CPU setup is typically desired if timely answers are important to you, Frame says.
All in all, Frame and her team of around 10 engineers are keen to put powerful graph algorithms into the hands of existing Neo4j users and new users to boot.
“It’s serving our existing customer better but it’s also building tools to bring more users in,” Frame says. “I’ve heard a lot of stories of people who said ‘Hey I think graph data science is interesting. I think graph algorithms are powerful. But I tried this open source library or I tried this tool and I couldn’t get it to scale or I couldn’t get what I needed to do to finish.’
“We have now created a tool that enables them to answer the questions they were trying to answer, run the workloads they were trying to run, reliably and really make it possible for them to do what they were trying to do before,” she says. “You should be able to get up and running in about 30 minutes, not after you’ve written your PhD thesis.”
Related Items:
Neo4j Going Distributed with Graph Database
Graph Databases Everywhere by 2020, Says Neo4j Chief
Vendors:
Neo4j
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States