


February 4, 2020
Neo4j Going Distributed with Graph Database

Neo4j is the leader in the burgeoning graph database market, with 17 years in development and thousands of open source users. But the database has a hard limit in terms of scalability, since it essentially was restricted to running on a single server. With today’s launch of Neo4j 4.0, the company has taken the first step in creating a distributed graph database that spans multiple physical systems.
Neo4j is not yet a fully distributed graph database, even with 4.0. But with the new multiple database feature – which essentially allows users to shard a single graph database into multiple sub-graphs that can be managed and queried in a distributed manner through the new Fabric server – Neo4j has begun the process of moving the database towards a fully clustered model.
According to Neo4j Chief Scientist Jim Webber, Neo4j is following the Apache Cassandra model with the goal of eliminating scale as an impediment to running a graph database.
“We never really split up the graph before,” Webber tells Datanami. “This is the first time that we’re able to query essentially multiple sub-graphs concurrently. So it kind of takes Neo4j in a direction towards best in class, scale-out system. In my mind, something like Apache Cassandra is the prototype for that.”
This does introduce different consistently models, of course, since graph demands stronger consistently than eventual consistency, he says. “But our ambition for Neo4j s for it to scale like Cassandra and be rock-solid like Oracle,” Webber says
With Neo4j 4.0, the customer decides how to split up, or shard, their data into multiple databases, or sub-graphs, that can run on separate systems but be queried as a single entity through the new Fabric server. Webber says Neo4j is following the MongoDB model here, where customers will split their data up according to business function (such as accounting or marketing) or according to geographical region, which organizations are doing anyway to adhere to data regulations like GDPR.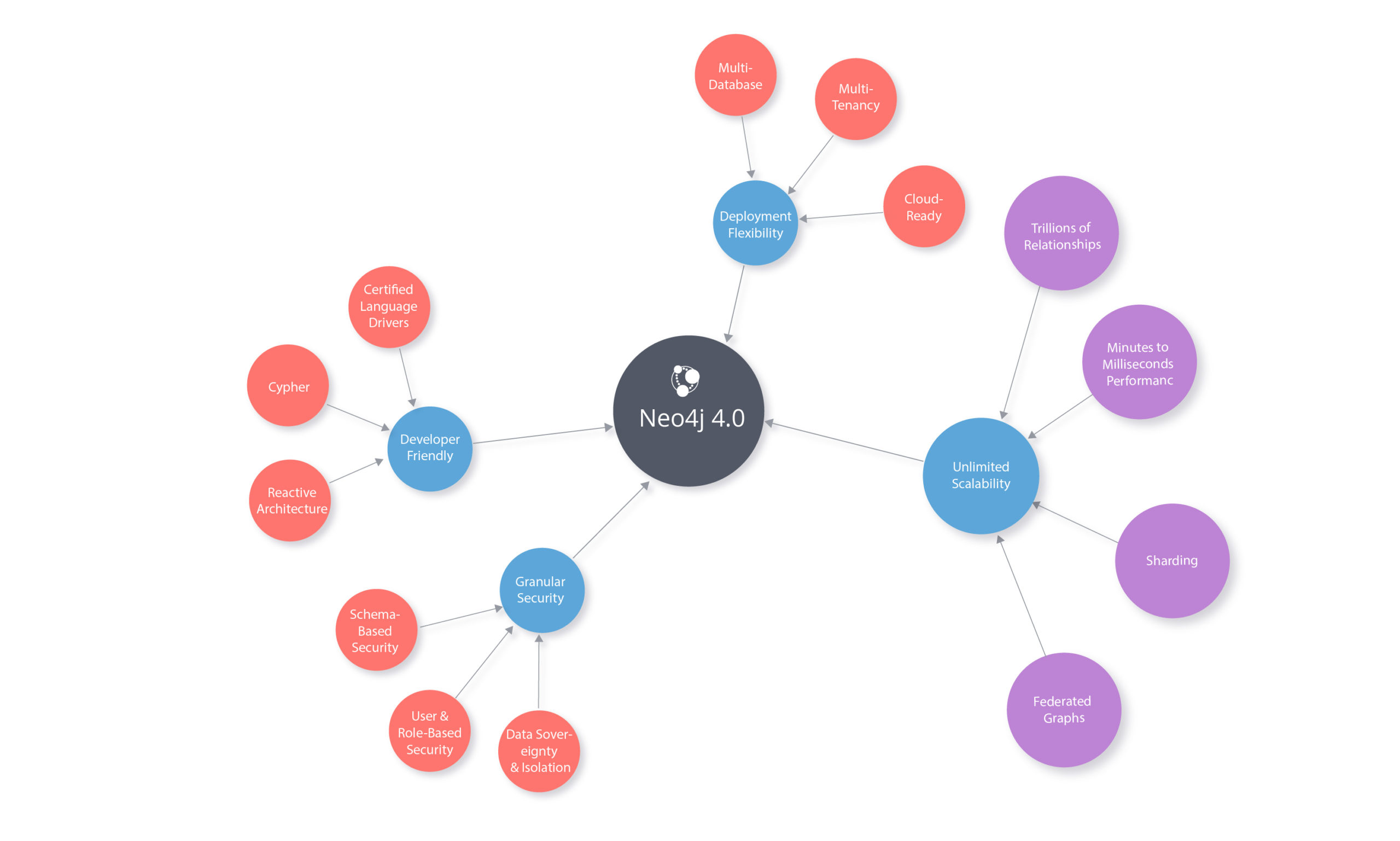
“So you can, on the one hand, treat those database as if they were multiple schemas in a relational database,” Webber says. “On the other hand, you can treat them as sub-graphs in a larger graph and be able run queries and compute aggregations across all of them in parallel. I think that’s pretty exciting because it moves Neo4j out of the mold of being a very fast but ultimately single-image system into being a multiple [server] or partitioned system, which I think is somewhere, in the marketing sphere, where we used to get beaten up.”
The clustered database project has been three years in the making, and required extensive engineering resources to overcome tough design challenges. Neo4j is increasingly being used as the basis for production analytic and machine learning use cases in problems like fraud detection and real-time recommendations. Some of Neo4j’s customers have begun to hit the limits of what a single-system graph database can deliver. It’s also given space for competitors like TigerGraph, which an upstart developer of a fully distributed property graph database, to make some hay at Neo4j’s expense.
That meant that Webber needed to increase the scalabilty of Neo4j, but without sacrificing the speed and accuracy that Neo4j customers have grown accustomed to. To that end, it fell to Webber and his team to figure out a way to distribute the graph while avoiding the possibility (what some say the likelihood) that the data in the graph becomes corrupted when it’s split up.
The big challenge is that the eventual consistency model used in Apache Cassandra and other NoSQL databases is a non-starter in Neo4j’s graph database world. “The reason we can’t just swap in Cassandra under the covers,” Webber says “is because eventual consistency will corrupt your data, because of those relationships that spawn between partitions.”

Neo4j lets customers query multiple sub-graphs with a single query (image source Neo4j)
In an eventually consistent database, there’s no rhyme or reason to the order that messages arrive and are processed. That’s fine for some use cases and databases. But it’s potentially catastrophic in a graph database because of the way that new data changes the nature of relationships and how those relationships would potentially change in a distributed system.
If care is not taken to ensure the new messages are put into proper order before they’re written to the distributed database, things can get out of hand quickly. “The worst case scenario is that I think I have a relationship with you, but you don’t think you have a relationship with me, which makes it really awkward at Christmas, because I send you a Christmas card and you don’t respond,” Webber says, only somewhat jokingly.
“We didn’t want to go that way in Neo4j,” he continues. “Neo4j has always been about trustworthy data. We‘re Swedish, so we’re kind of the Volvo of databases–headlights everywhere. We don’t want to introduce those kids of risks.”
The result is that Neo4j is “having to do this rather more carefully and expensively” than other databases, Webber says. Not all the work is done yet. But the company has already applied for a patent for a new transaction protocol that ensures data consistency in a distributed graph database.
That new protocol, which will be fully introduced in a future release, is based the concept of “collision avoiding” that says only a small fraction of transactions need to have the more expensive coordination efforts to prevent data corruption. This will allow the database to maintain high performance without sacrificing strong consistency, Webber says.

Jim Webber is the chief scientist at Neo4j
“So for the future version of 4.x, we will be introducing a protocol to take more of the burden off the users and allow us to automatically transact across those multiple databases without the user worrying,” Webber says.
In the meantime, customers can begin using Neo4j 4.0, which gives a taste of the new clustered features that are coming down the pike. There’s no practical limit to the number of databases that customers can now run in Neo4j 4.0, and they can scale their operations up to take advantage of that.
In previous releases of Neo4j, each database had a single write channel that used the RAFT consensus algorithm. Now, hundreds of Neo4j databases can be spawned and each gets its own RAFT, which delivers a big scalability lift through parallelism, according to Webber
“With Neo4j, you can spin up 10, 100, 500 databases across your cluster, and each of those will have its own RAFT group, so you’re able to exercise that in parallel,” Webber says. “The only contention you’ll find is mechanical contention, right down at the storage layer. Everything else runs independently, and if you have fast storage, you’ll be able to pump data through multiple database to your heart’s content.”
Users can query those databases through new Fabric distributed runtime engine in a manner they’re already familiar with, Webber says. “All you do is you type in your Cypher query, and you run it on a Fabric server rather than directly against the backend database,” he says. “Fabric does all the work, including getting the queries sent over to the representative underlying graphs in the multi-database. It does all the work of retrieving information and does all the work of all the aggregates and that kind of stuff before shipping the results back to the client.”

The graph traversal feature maintains correctness in queries while enforcing role-based security (image source Neo4j)
Customers who invest in the multi-database capability in Neo4j 4.0 will have an easy path to true distributed graph computing with future 4.x releases, Webber says.
Two other notable features are included in Neo4j 4.0, including role-based security and a reactive API.
The new role-based security enables users to permit and restrict access to specific parts of the graph database at a fine-grained level. Neo4j lets admins control who has the ability to read and write to any node, as well as to access relationships and properties. The company also added the capability to grant a user permission to traverse a graph structure, but not to read the data, relationships, or properties contained in those resources.
“This is really important because without that, you can compromise correctness,” Webber says. “The traverse operator is correctness preserving.”
The new reactive API enables developers to consume data from the Neo4j database at their own rate, instead of being overwhelmed with a flood of query results. “It might seem nerdy and low level,” Weber says, “but it means people using Neo4j have a much smoother path when they’re using the database.”
Neo4j 4.0 is available in two versions, including an enterprise and a community license. The multi-graph and distributed Fabric functions are only available in the enterprise version (which Neo4j makes source code available for), while the security features and reactive API are available in the community edition, which is fully open source.
Related Items:
Neo4j Expands Startup Access to Graph Database
Graph Databases Everywhere by 2020, Says Neo4j Chief
Applications:
Predictive Analytics
Technologies:
Middleware
Leading Solution Providers

















