

October 24, 2018
New Cloudera Plots a Course Toward a Unified Future
The merger of Hortonworks and Cloudera will eliminate competition in the market for big data platforms and create a clear leader in the space. Once the transaction is complete, the new Cloudera will embark upon the challenging task of merging the two companies’ offerings into a unified data platform that maintains links to Hadoop’s legacy past while providing an upgrade path to its “edge to cloud” architecture of the future.
The surprise October 3 announcement that Cloudera and Hortonworks plan to merge and create a single unified company with $720 million in annual revenues and 2,500 customers created a stir in the big data ecosystem. Some saw the news as proof of the death of the Hadoop platform at the hands of cheaper and simpler cloud-based storage and compute offerings, while others saw it as the final popping of the Hadoop-hype bubble as the technology goes mainstream.
Whatever camp you sit in, the merger undoubtedly caught the attention of the 2,500 organizations that have adopted Cloudera’s Distribution of Hadoop (CDH) or the Hortonworks Data Platform (HDP) over the years — not to mention the thousands of other companies that have adopted open source Apache Hadoop platforms or Hadoop ecosystem components in the cloud. These Global 2000 companies have invested billions of dollars into building giant clusters to store and process many exabytes worth of data, and they’re not going to just turn them off overnight because the two biggest players suddenly decided to merge.
At the same time, these customers need to be reassured that Cloudera has a plan to maintain the investments they’ve already made in HDP and CDH platforms, both in a short-term or tactical sense, as well as in terms of Cloudera’s long-range strategy to evolve its platform to meet emerging future compute and storage needs.
‘At Least Three Years’
Cloudera executives have stated that customers running the latest releases of CDH, HDP, and Hortonworks DataFlow (HDF) will be fully supported for “at least three years.”
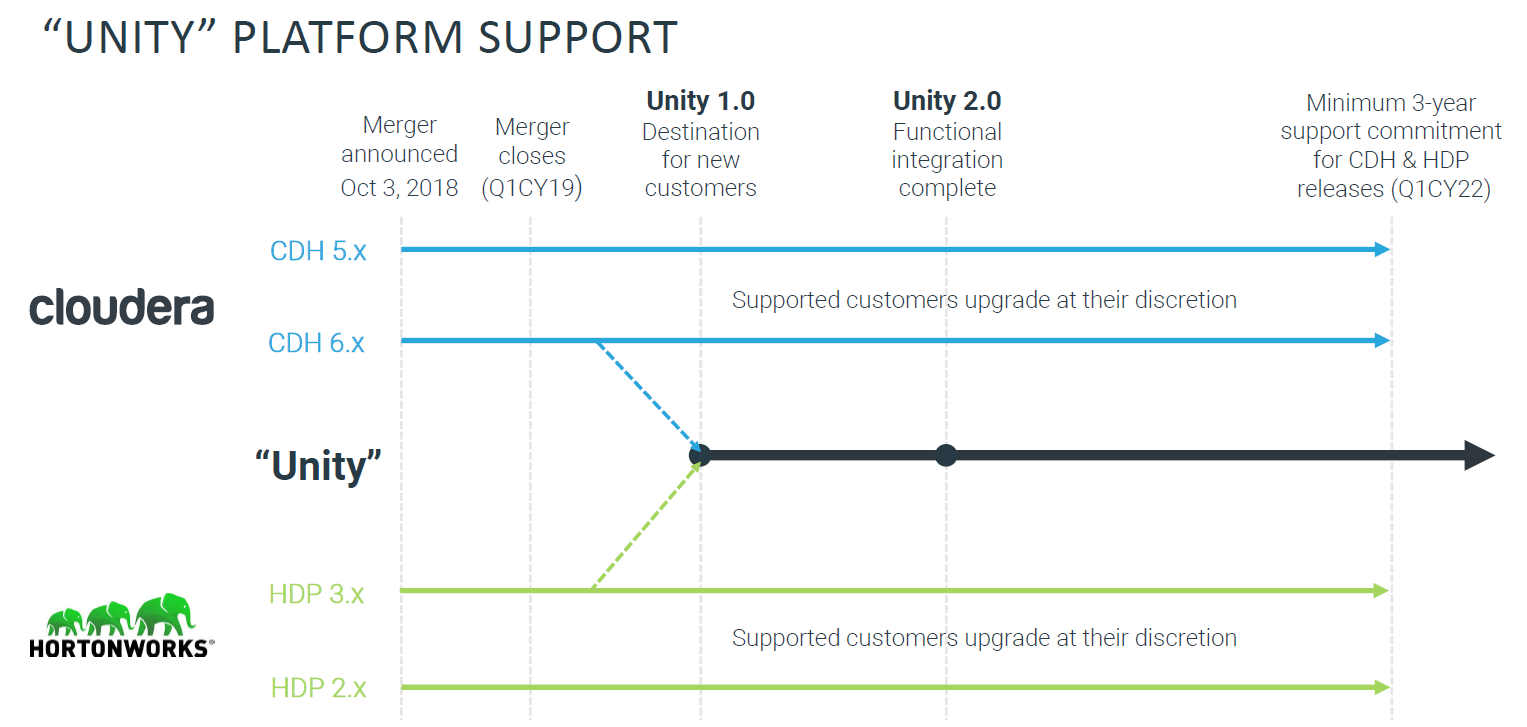
Cloudera plans a “Unity 1.0” release followed by a “Unity 2.0 functional superset” at a later time (Source: Cloudera)
“Customers who are running CDH, HDP, and HDF are getting a new promise,” wrote Mike Olson, Cloudera co-founder and chief strategy officer in an October 3 blog post. “Those product lines will each be supported and maintained for at least three years from the date our merger closes. Any customer who chooses either can be sure of a long-term future for the platform selected.”
Long before that three years is up, however, Cloudera plans to ship a pair of “Unity” releases that will standardize Cloudera’s software stack, according to Cloudera CEO Tom Reilly.
“Once the merger closes, we plan to create a near-term ‘unity release’ that combines the best of both worlds of CDH 6 and HDP 3,” Reilly wrote in a mass email sent to partners on October 5.
A second unity release, dubbed “Unity 2.0” in the company’s filing with the SEC, will follow sometime in the months and years to follow. “Over time, we plan to make this unified platform a functional superset of all past CDH and HDP releases and our future capabilities,” the company writes. “Where possible, we plan to cross-port valuable components and features across our two platforms to make transition to our next generation ‘unity’ platform easy.”
CDH version 6 and HDP version 3 are both based on the Apache Hadoop version 3 codebase, and both were released by their respective vendors during the summer. “That turns out to be a fortunate coincidence,” Olson wrote. “We’ve both rebased our latest products on the current open source project releases, meaning our development lines are closer than they’ve been in some time.”
What Stays and What Goes?
While the CDH and HDP codebases are closer than they have been, there are still some significant differences between the two product lines, which leads some observers to wonder which components will remain in the Unity releases that gets the best that each has to offer, and which ones will get the boot.

HDP 3 contains dozens of components
One of the biggest decisions that Cloudera will have to make is around the management interfaces going forward. Cloudera customers have long relied on the proprietary Cloudera Manager software to manage their CDH clusters, while Hortonworks has championed the open source Apache Ambari project.
Decisions must also be made on the security front. Over the past few years, battles between Apache Ranger and Apache Sentry have served as a sort of proxy war for the larger Cloudera-Hortonworks conflict, with Cloudera backing Sentry and Hortonworks backing Ranger.
Managing data access permissions for multiple applications, processing engines, and users — particularly across multiple cloud- and on-premise silos — is not an easy task, and it’s even tougher to do while respecting security, privacy, and governance policies like GDPR and the new California data law. Cloudera’s answer to this challenge is a common metadata framework called the Shared Data Experience (SDX), which it offers on-premise and in the cloud. Hortonworks, meanwhile, has been solving some of the same products with its DataPlane Services, which it has been selling as the third-leg of its product stool since late 2017.
It’s anybody’s guess which products Cloudera chooses across these categories, not to mention other prominent Hadoop components where the companies have skirmished, such as Apache Hive, which is backed by Hortonworks, and Apache Impala, which Cloudera developed.
A company spokesperson told Datanami that the company would provide no further guidance on the unified product at this time beyond what it has publicly provided.
Ecosystem Impact
Kunal Agarwal, the CEO of Unravel Data, thinks the fact that Hortonworks chief architect Arun Murthy was named head of product for the new Cloudera is a sign that the new unified product may look a little more like HDP than CDH.
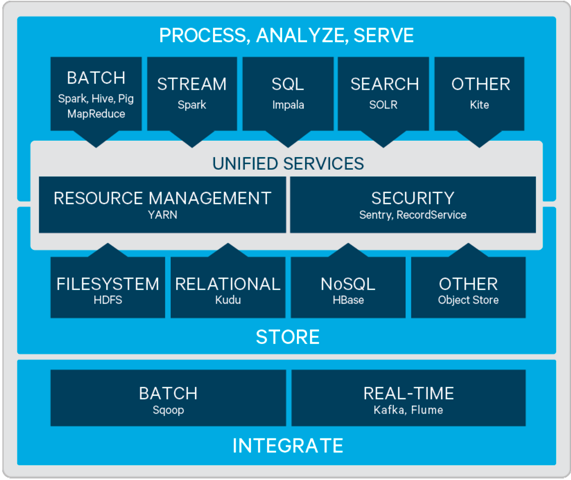
CDH 6 supports many of the same components as HDP 3
“If had to speculate, it would probably be HDP to unify on instead of the CDH platform,” Agarwal says. “But they will take Cloudera Manager instead of Ambari. So there’s going to be swapping out of those pieces. They still have a very open core of HDP instead of CDH so they can continue to innovate along with the community.”
Monte Zweben, the CEO of Splice Machine, an operational database that sits atop Hadoop and uses HBase and Spark engines, isn’t sure if the merger will be beneficial to his business and his customers in the short term.
“If people don’t transform to unified system and are still on the old system, I’ll probably still have customers that are asking us to support those old systems,” he says. “I’m not sure if it makes life easier for us in the next two years. But in the next five years it definitely does…Ultimately having one unified system is going to be much better for me, but not in the near term.”
It’s possible Cloudera could continue to provide multiple options for customers. After all, Cloudera’s Olson wrote that “where possible, we plan to cross-port valuable components and features across our two platforms to make transition to our next generation ‘unity’ platform easy.”
However, it doesn’t seem likely that Cloudera would maintain duplicate product lines as a long-term strategy.
Long-Term Shift
Product managers for the post-merger Cloudera will need to rationalize the overlapping offerings and set a clear direction forward. That shouldn’t be too hard, with some caveats. But in the long-term, Cloudera will have to take bolder, more strategic bets in order to keep up with evolving expectations, and those expectations are largely being defined by the cloud players.
As Hortonworks and Cloudera battled each other and MapR Technologies for share of the on-premise big data platform market, the competitive dynamics suddenly shifted to the cloud, where Amazon Web Services, Microsoft Azure, and Google Cloud can offer object storage systems that’s five times cheaper than HDFS.
In addition to the cheaper storage, the public cloud providers offer customers a veritable smorgasbord of pre-built applications for doing interesting things with all that data, including Google BigQuery for data warehousing, Azure ML for machine learning, and AWS Kinesis Streams for stream processing. Smaller firms like Snowflake Computing, Databricks, and Confluent have emerged to offer differentiated experiences in data warehousing, data engineering, and stream processing as well.
Giving a Hadoop platform (or whatever Cloudera eventually calls it going forward) some of the characteristics of these clouds – including ease of provisioning, dynamic scalability, and pre-built integration – is clearly the goal for the new Cloudera. Hortonworks and Cloudera had already been working toward integrating Kubernetes before merger.
But even with the combined engineering resources of both companies, it won’t be easy. Olson told Datanami before the acquisition was announced that it will likely take the open source community 12 to 24 months to come up with a first pass at integrating Kubernetes into the stack. YARN, the current scheduler, touches almost everything, but the market momentum behind Kubernetes is so great that the containerized technology has essentially already been declared the de-facto resource manager of the future.
Fully integrating Kubernetes into Cloudera’s Unity 2.0 stack will be a good move, but it won’t be enough. CDH and HDP are mostly dependent on HDFS to manage storage, but the cost and scalability advantages of object stores has become too great to ignore anymore, so eventually on-premise big data clusters will utilize an object store with an S3 API.
In the short term, there doesn’t appear to be much risk to Cloudera and Hortonworks customers and their big data clusters. The three-year support commitment should put CIOs and CDOs at ease that the product decisions they already made will not immediately come back to haunt them.
But the long-term strategy is less nailed down at this point. Cloudera has some big decisions to make and even bigger engineering challenges to solve if it’s going to actually deliver “the first enterprise data cloud, from the edge to AI,” as Olson claims.
Making a big, bold bet is reassuring in the sense that small bets are for small fry. However, in the rough and tumble sport of enterprise IT, bad bets are not remembered fondly. Everybody wants to know what the big data architectures of the future will look like, but it’s Cloudera’s job to actually put the chips down on the table and build one, which is no easy task.
Related Items:
Reaction to Hortonworks-Cloudera Mega Merger
Cloudera and Hortonworks to Merge in $5.2 Billion Deal
Applications:
Enterprise Analytics
Technologies:
Frameworks
Vendors:
Amazon, Cloudera, Databricks, google, Hortonworks, MapR, Microsoft, Snowflake Computing, Splice Machine, Unravel Data
Tags:
AI, apache hadoop, cloud, cloudera, Hadoop, Hortonworks, iot, Kubernetes, Object Storage, product roadmap, s3
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States