

March 6, 2018
Streamlio Claims Pulsar Performance Advantages Over Kafka
Streamlio, a startup created a real-time streaming analytics platform on top of Apache Pulsar and Apache Heron, today published results of stream processing benchmark that claims Pulsar has up to a 150% performance improvement over Apache Kafka. The company also unveiled a new processing framework called Pulsar Functions.
In the battle for stream processing supremacy, there’s one platform that has developed an early advantage over all the others: Apache Kafka. The distributed, open-source software, which emerged from LinkedIn and is backed by the commercial outfit Confluent, has had millions of downloads since it was released seven years ago, and is considered by some a defacto standard part of the fast data stack.
While Kafka was a big improvement over what came before it, not everybody is thrilled with Kafka. It’s nothing personal, but the folks at Streamlio think they have built a better mousetrap for the specific task of sending massive streams of data zipping around the globe in a reliable and scalable fashion, and then running interesting analytics on top of that data.
“We formed the company with a shared vision that real, time streaming analytics is actually very difficult to do with a number of solutions out there that require enterprise to stitch together many different technologies [that] have operational challenges,” says Streamlio CEO Lewis Kaneshiro. “What we do is unify messaging, compute, and stream storage with an open core model as we support technologies that have been proven in production at Twitter and Yahoo.”
Streamlio was co-founded by the creators of three important big data frameworks that together make up the Streamlio platform: Apache Pulsar, the distributed messaging and storage system that emerged from Yahoo; Apache Heron, the real-time analytics system that emerged from Twitter; and Apache BookKeeper, a scalable storage system.
“What we found is enterprise were trying to stitch together a number of technologies, and with each technology comes a learning curve and operational difficulty, and between technologies is where data loss, for example, can occur,” Kaneshiro tells Datanami.
By stitching the technology together itself in an “open core” manner and then delivering a proprietary user interface on top, the company aims to reduce the complexity level and operational risk that comes with integrating it themselves.
Pulsar has three main advantages over Kafka, according to Kaneshiro. First, it offers native support for multi-data-center geographic mirroring. “Within Yahoo, Pulsar is running multi full-mesh active-active in 10 data centers,” he says. “We were actually surprised to see the number of issues around [Kafka]’s MirrorMaker, even for two data centers, let alone three or four.”
Multi-tenancy allows multiple Pulsar users to have their own global namespace, rather than forcing them to share the namespace, which helps to alleviate authentication and security concerns in heavily regulated environments. Zero data loss is the third advantage he cites. When Kafka was developed, it was OK to lose some data, he says.
Pulsar has been in production for three years at Yahoo, where it handles 2 million plus topics and processes 100 billion messages per day. The Streamlio team says it runs into unhappy Kafka customers. Scaling the platform can be difficult, Kaneshiro says.
“In Apache Pulsar to scale the cluster, it’s as simple as adding nodes, rather than understanding and rebalancing and scaling up a Kafka cluster,” he says. “We believe we solved the hard problem of solving true disturbed storage and then built an efficient fast, zero-data loss scalable messaging component on top of that. That’s Apache Pulsar.”
Similarly, Apache Heron has advantages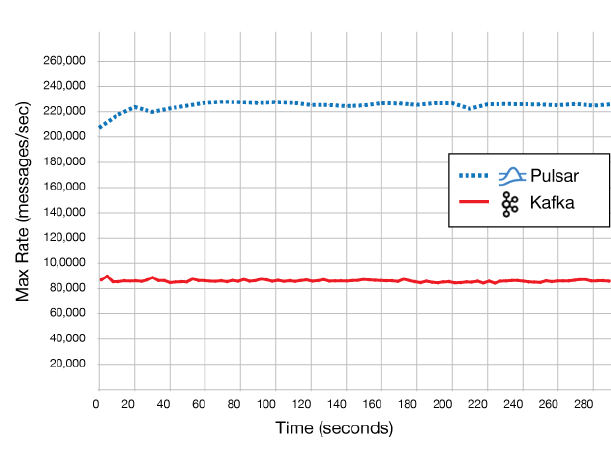 over Apache Storm, which was also developed at Twitter. At Twitter, Heron is used by over 50 teams and processes 2 trillion events per day, or about 20PB per day, says Kaneshiro.
over Apache Storm, which was also developed at Twitter. At Twitter, Heron is used by over 50 teams and processes 2 trillion events per day, or about 20PB per day, says Kaneshiro.
“Twitter and Yahoo cannot use Kafka,” says Karthik Ramasamy, the co-founder of Apache Heron and former head of unified computing at Twitter. There are lot of specific reasons why they don’t use them, he says, including the acceptability of data loss and the capability to add nodes on the fly without impacting production.
“So we’ve gone through a lot of interesting architecture lessons and came up with a new architecture that solves a lot of the pain points that Kafka and Storm had,” Ramasamy says. “That’s why we wanted [to use on the new products] that solve underlying issues that we face in production. We know very well, Twitter and Yahoo are three to five years ahead in terms of the infrastructure they use, so hence we deiced to use those new projects.”
Today the company unveiled results of a performance benchmark performed by Gigaom that pitted Pulsar against Kafka. The OpenMessaging benchmark, as it’s called, showed up to 150% improvement for Pulsar over Kafka in terms of throughput, while maintaining up to 60% lower latency.
The company also unveiled Pulsar Functions, a new lightweight computing capability designed to allow developers to quickly add data processing tasks that operate on Pulsar message topics. The functions could include just-in-time transformations, real-time analytics, or content-based filtering and routing.
With $7.5 million in Series A funding and a roster of some of the top distributed systems developers in Silicon Valley, Streamlio is poised to make a different in an emerging space. The fact that it first must disrupt an established technology makes it a company worth following.
“We believe that we’re very early in the unified streaming space,” Kaneshiro says. “The world is moving to real time, as we’re moving away from the slow data era and really entering a new era of fast data. Enterprises need an intelligent real-time platform for fast data, so we created Streamlio with that vision, to bring streaming to the masses.”
Related Items:
Five Ways to Apply Streaming Analytics Now
Merging Batch and Stream Processing in a Post Lambda World
Applications:
Complex Event Processing
Vendors:
Streamlio
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States