

September 26, 2017
MapR-DB Gets Secondary Indexes to Drive Operational Analytics

The ever-shrinking window of opportunity to act upon fresh data arriving from the world is forcing application developers to get more creative in how they analyze that data. Right there with them is MapR, which today at the Strata Data Conference unveiled a new release of its MapR-DB database that gives developers more powerful capabilities for operational analytics, including native support for secondary indexes.
MapR-DB is the NoSQL-like database that’s built into MapR‘s converged platform. While a Hadoop distribution that uses a modified version of HDFS, which it now calls MapR-XD, brings analytics for huge amounts of unstructured data, and a Kafka-compatible product called MapR-Streams supports stream processing, MapR-DB serves as the suite’s operational data store for serving live data to users and applications.
With today’s launch of MapR-DB 6.0, the San Jose, California-based company has introduced a range of new features geared at making it easier for application developers to build real-time analytic capabilities directly into that operational data store.
The biggest new feature arguably is support for native secondary indexes in MapR-DB. The database had no formal mechanism for creating these indexes before, and as a result, developers had to resort to indexing data on external systems to find the piece of information they needed or – even worse – running full table scans.
Secondary indexes will be essential for adding analytics to a range of operational systems, including customer-360 types of application with acceptable performance, says MapR Senior Director of Product Management Neeraja Rentachintala.
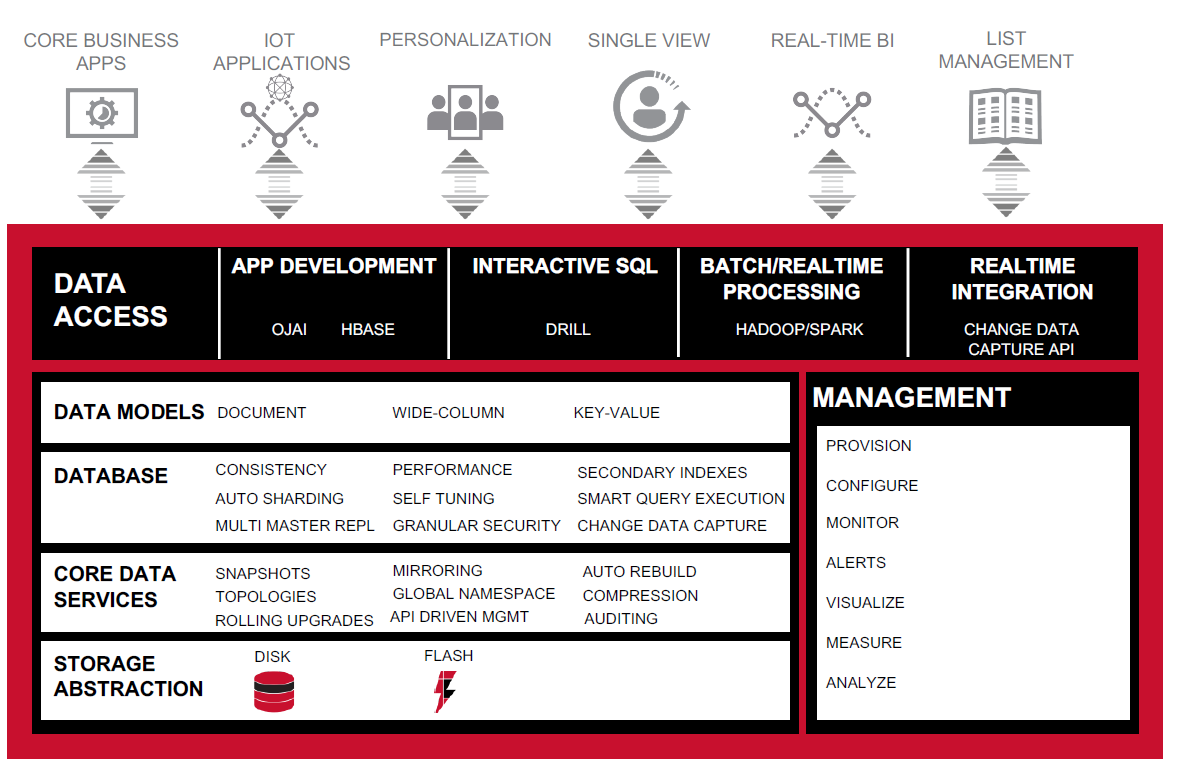
MapR-DB architecture
“That customer information needs to be queried across probably 200 or 300 dimensions of the customer,” she says. “It could be based on the phone number or it could be based on the state, or on the interest of the customer. There are so many dimensions the data needs to be queries by different applications, and you need the flexibility.”
Relying on indexes running on external systems can lead to all sorts of trouble, particularly if the indexes don’t’ fit on a single node of the cluster and have to be sharded. And trying to use table scans to power customer queries in a customer 360 application may not work at all. “You don’t want to use full table scans for those queries,” she says. “This becomes more critical if the database is 2 or 5PB in size. That’s practically impossible to do with table scans. You have to get to the data you’re looking for quickly and efficiently.”
MapR has also integrated Apache Drill into its secondary indexes to help drive self-service business intelligence use cases. “So now Drill will use the powerful cross-built query optimization to retrieve the right amount of data,” Rentachintala says. “And if the data is millions and millions of rows, it can use distributed execution.”
The company has also upgraded its core API used for accessing JSON data stored in MapR-DB, called OJAI. With the OJAI 2.0 API, the company added support for the secondary indexes, as well as added more sorting and filtering capabilities to enable queries to return the right piece of data.
The OJAI enhancements will simplify life for the developer seeking to use real-time analytics to drive more interactivity into an application, Rentachintala says. “Say I’m trying to pick a customer within this particular region and these different characteristics who’s interacted with my systems in last three days,” she says. “Once I have the filters set up, we have the ability to leverage indexes” to find those users programmatically.
MapR has also improved integration between Spark and Hive into the MapR-DB database, enabling more powerful SQL and machine learning analytics to be run against the data. “We have high-performance database access, reading and writing from Spark and Hive with respect to being able to process batch and real -time analytics,” Rentachintala says. “There is lots of optimization to ensure that processing is fast and efficient.”
It’s all about squeezing insights out of data faster and faster, says Jack Norris, MapR’s senior vice president of data and applications.
“There’s a really broad set of use cases. Maybe I want to do a better job of customizing and personalizing the user experience as Web page is loading…It can be used for security or anomaly detection or can be used for sifting through log files and determining the right responses. Or it can be an IoT use case,” he says. “
 “Most of the thought process on those is, ‘Oh that must be something that’s done after the fact. There’s a business analyst that’s driving this. They’re getting some sort of insight, then there’s a human-driven action that takes place at some later date.’ Increasingly we’re seeing this is more of an automated, application centric type of operation to drive this digital transformation if you will.”
“Most of the thought process on those is, ‘Oh that must be something that’s done after the fact. There’s a business analyst that’s driving this. They’re getting some sort of insight, then there’s a human-driven action that takes place at some later date.’ Increasingly we’re seeing this is more of an automated, application centric type of operation to drive this digital transformation if you will.”
Norris says the enhancements puts MapR-DB into a class of its own with respect to enabling fast reads as well as fast writes within the same database.
“There are NoSQL databases that have focused on how to handle write-intensive that are more on transactional side, and there are those NoSQL databases that are optimized for read-intensive and are more on the application side, but there’s nothing out there that can effectively do both,” he says. “What we’re saying is the breakthrough here is handling these mixed workloads that are employed when you’re doing these operations and analytics
“It’s really going to help organizations be much more efficient and agile and really take a lot of the debate out of the process for the developer in terms of which one should I use? How much is this going to scale?” he continues. “Because if it’s not going to scale, maybe I’ll use MongoDB. But if it needs to scale, then I needs to use something else. Am I eventually going to put analytics in this after I do my first version and make this more intelligent? There’s a whole bunch of forks in the road, decision trees, that are bolt into this development process that we can cut through and simplify and eliminate.”
The new MapR-DB 6.0 is slated to ship during the fourth quarter.
Related Items:
MapR Rebrands Around Converged Data Fabric
MapR Extends Its Platform to the Edge
MapR Delivers Bi-Directional Replication with Distro Refresh
Applications:
Enterprise Analytics
Vendors:
MapR
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States