

June 6, 2017
MapR Rebrands Around Converged Data Fabric

(agsandrew/Shutterstock)
MapR Technologies today announced a major rebranding and repositioning of the data storage layer of its converged data platform. MapR-XD, as the data store is now known, provides the mechanism for customers to build a unified data fabric that stretches from edge devices, into the data center, and out to public clouds.
The San Jose, California company says MapR-XD allows users to “create vast, global data fabrics which are inherently ready for analytical and operational applications.” The data fabrics created with the MapR-XD layer encompass multiple storage mechanism, including HDFS, NFS, REST, POSIX, and MapR Streams, and will support analytical and operational workloads running in batch, interactive, or streaming fashion, the company says.
“We have a new product, MapR-XD, which is going to extend the MapR Converged Data Platform to help companies create the cloud-scale data fabric by managing files and containers for them, in mulit-temperature and multi-tier environments, and across the edge, on premise, and multiple clouds,” says MapR’s Senior Director of Industry Solutions Bill Peterson.
The rebranding exercise was necessary to showcase the work that MapR has done in providing a single computer platform that can not only spans multiple physical and physical locations (like Docker), but can expose data through a variety of different APIs, including Hadoop-compatible file system (MapR-FS), a Kafka-compatible data pipeline (MapR-Streams), and a NoSQL database (MapR-DB).
“Whether you came into the platform from the file system or came in from the database or from Streams, you got multi-temperature [data management], you got the global name space, you got all the high availability,” Peterson tells Datanami. “But we’ve never called it anything. We’ve never branded around that. So as part of this exercise, we’re going to rebrand that as the MapR Converge-X Data Fabric.”
Peterson continued:
“Our file system is now XD. We’ve added a bunch to the file system and have quite a number of customers who are buying us just for storage and data management. And we’ve done quite a work on Flash and improving I/O on Flash within the platform, and also with moving data between tiers, from Flash to disk to cloud, within the global namespace. Because of all of those reasons and the customers that we’ve been securing, we’ve decided to brand around this and go to market with a data storage and data management, which we really hadn’t done before.”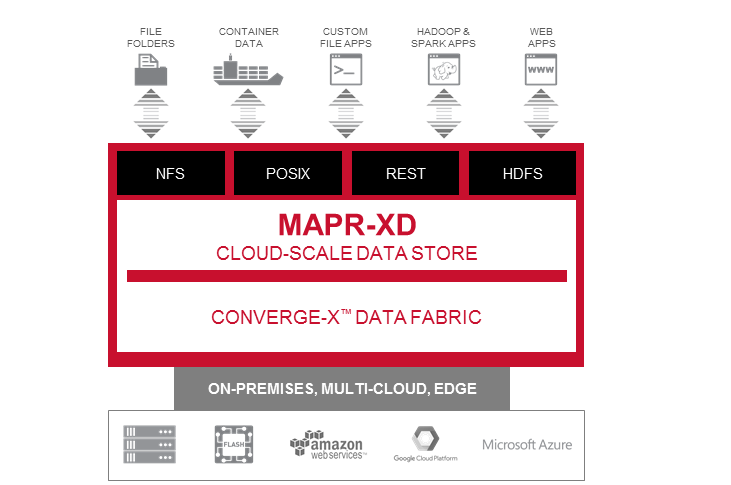
MapR also announced that it’s shipping a new version of its converged platform that’s optimized for to run on Flash and NVMe disks. The core platform has now been split into two SKUs (or stock-keeping units): one for regular disk, and one for Flash disk.
The company says two recent customer wins — with enterprise software maker SAP and consumer goods manufacturer Samsung — showcase its converged data fabric and Flash capabilities.
SAP chose MapR to provide the core underlying platform that it will host its new cloud-based software as a service (SaaS) offering upon. HANA is the first piece of the SAP software suite that will run on MapR-XD, with more to follow. “A lot of that work for optimizing I/O for Flash came out of this work” with SAP, Peterson says. “We said, hey this is a good time to package this up and make it available.'”
Samsung, meanwhile, is using MapR as the underlying data store for Bixby, the voice-based virtual assistant that Samsung is building into its next-generation Galaxy S8 and S8+ phones. “Over time, this is going to be huge. Trillions of files that we’re going to need to store,” Peterson says, adding that it’s a “retain forever model.”
MapR is also working with various automakers on their connected-car projects. In these engagements, cars roll along with MapR software managing the storage layer, and making that data available in the data center and the cloud as needed.
It’s all about eliminating silos with a global namespace, says Peterson, borrowing a term that’s often used in the object storage system world. “It’s the ability of our global namespace to move data from a data center to a cloud based on a tiring model or a temperature model,” he says. “It’s all one global namespace. It’s all one cluster. The application doesn’t care or need to know. That, we find is huge.”
Eventually, the MapR platform will support an object file system, namely Amazon’s S3, which is the dominant protocol for accessing object file systems today. “Today, we support files and containers. Object and S3 are roadmap,” Peterson says. “The one we’re not doing is block [storage] and the reason is, with block there’s no metadata associated with it, there’s no analytics.”
There’s meaning behind the name. The “x” stands for “anything,” while the “d” stands for “data.”
Related Items:
MapR Extends Its Platform to the Edge
MapR Delivers Bi-Directional Replication with Distro Refresh
MapR Appoints New CEO, Preps for ‘Hypergrowth’
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States