

September 19, 2017
TigerGraph Emerges with Native Parallel Graph Database
A startup named TigerGraph emerged from stealth today with a new native parallel graph database that its founder thinks can shake up the analytics market. With $31 million in venture funding and several high-profile customers, he might just be right.
TigerGraph founder and CEO Yu Xu is no stranger to the challenges of building distributed computational engines. After getting his PhD in distributed databases from University of California at San Diego, he went up the street to Teradata, where he led the MPP (massively parallel processing) database team and also worked on big data projects. Then Xu headed off to Twitter, where he helped built the social media company’s distributed data infrastructure.
For the last five years or so, Xu has been working to design a graph database that could surpass the capabilities of existing graph databases. Specifically, he planned to do this by building TigerGraph, which he considers to be the world’s first native distributed graph database.
There are other native graph databases, which means the data is stored in a graph-like manner and not added on after the fact, as with some graph solutions that reside atop Hadoop and NoSQL. Neo4j is an example of a native graph database that was built from the ground up to store pieces of data as nodes and express their connectedness through edges. Xu considers this “Graph 1.0.”
The market also has parallel graph databases available. Giraph is an example of a parallel graph database that runs on Hadoop. There are other parallel graph databases that sit atop NoSQL, which Xu calls “Graph 2.0.”
But as Xu explains, these approaches introduce compromises in scalability, performance, and ease of use. They “come with limited capabilities for complex graph analytics and also comes with limitations to deal with the big amount of data,” Xu tells Datanami.
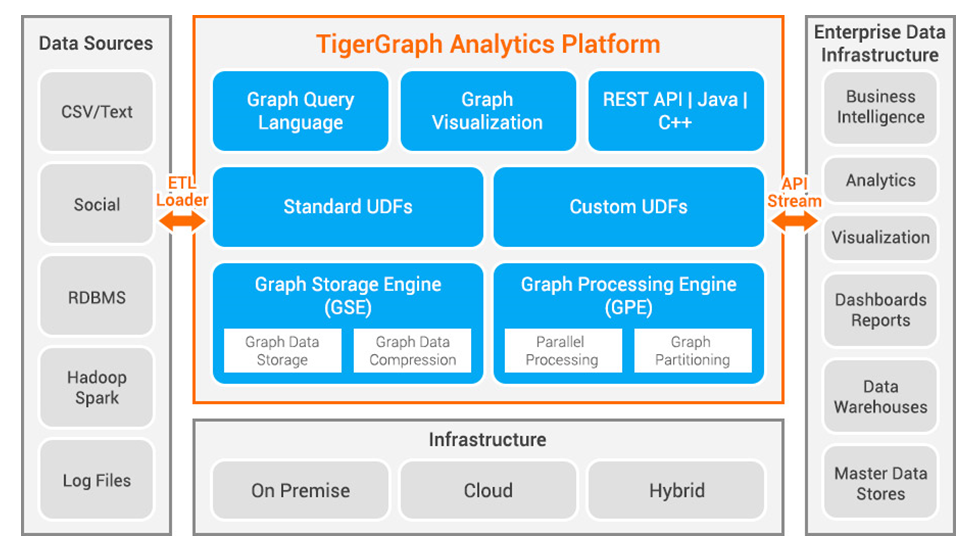
The TigerGraph architecture
Specifically, Xu says non-parallel graph databases running on symmetric multi-processor (SMP) systems cannot handle the complex workloads that today’s companies want to run against graph databases. Most of them are storage focused (not computationally focused), and top out with “two hops” in the graph, or solving “friend of a friend” type problems before the queries bog down and become intractable.
(Neo4j has addressed the scalability challenge in other ways, including by running on IBM‘s Power Systems SMP servers, which scale vertically much better than commodity Linux servers can. In 2015, Neo4j and IBM worked together to enable Neo4j to run on IBM’s field programmable gate array [FPGA] co-processors, which enable the database to scale up to support trillions of edges).
The core problem impacting parallel but non-native systems like Giraph is that they cannot be updated easily. Giraph, Xu says, “can handle much bigger datasets than Neo4j but you cannot update the graph [in real time],” he says. When you want to add new data, you have to “redo the whole ETL process from scratch.”
Xu set out to deliver the best of both worlds (native and parallel) with TigerGraph, which he dubs “Graph 3.0.” TigerGraph, Xu claims, solves the scalability problem by being able to run on more than 1,000 nodes of commodity Intel processors, which he says gives it the capability to run queries with up to 20 hops with sub-second response time. Plus, because it’s native, it allows the user to add data to the database continually, without needing to re-run ETL processes.
There are 15 patents pending for TigerGraph (formerly called SQLGraph), according to Xu, who owns 26 patents for distributed systems and databases. Xu says the architectural advantage of TigerGraph stems from the “automatic computational parallelism” built into the system, which allows it to process up to 100 million vertex (or edge) traversals per second.
In the TigerGraph scheme of things, each vertex/edge “is not only a unit of storage, but is also a computational unit,” the company says. What’s more, the graph database engine offers 10x data compression, and “will automatically scale the computation across all threads and CPU cores available,” the company says.
The company is touting the results of a benchmark test that involved querying a 1.4 billion graph composed of Twitter data on an AWS server consisting of 32 CPUs and 60GB of RAM. The company says TigerGraph was able to update data at a pace of about 800,000 rows per second, whereas Neo4j version 3.1 clocked in at 14,000 rows per second.
Xu is clearly gunning for Neo4j, which has been around nearly two decades and is the undisputed leader in the graph database market. “They did a good job in terms of marketing and education,” Xu says of his competitor. “This type of thing takes time. What we’re trying to do is we want to solve many important big scale problems that Neo4j could not even do before. We [want to] focus more on high end, real time, large sale complex problems.”
As part of today’s launch, TigerGraph announced that it received $31 million in Series A funding, which Xu claims makes the company the second most well-funded graph startup after Neo4j (formerly Neo Technologies). The company also announced the availability of TigerGraph 1.0, as well as the launch of TigerGraph Cloud, a hosted version of the database that resides on Amazon Web Services. It also formally changed its name from SQLGraph.

Yu Xu led Teradata’s distributed database team before founding TigerGraph
TigerGraph, which is headquartered in the Silicon Valley and has a branch office in Shanghai, China, has been around for five years, and already has a handful of customers using its product, including Alipay, an e-payment company founded by Chinese online merchant Alibaba that has what TigerGraph claims is the largest transaction graph in the world — a graph with 100 billion vertices and more than 2 billion daily updates. Another customer is State Grid, the state-owned electric utility in China that’s the second largest company in the world by revenue. China Mobile also uses TigerGraph for an anti-fraud system.
The company took five years to emerge from stealth so that it had more of a finished product ready for the market, Xu says. The company took the extra time to build a software development kit (SDK), visualization tools, as well as a Java API to go along with the original API written in C.
Xu is bullish on the potential for graph analytics to grow as a market. “It’s a more intuitive and more natural way to solve a lot of problems,” he says. “I think the timing is right. I think the graph market is going to grow really quickly in the ensuing years.”
Related Items:
The Motivation for Native Graph Databases
5 Factors Driving the Graph Database Explosion
Graph Databases Everywhere by 2020, Says Neo4j Chief
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States