


August 19, 2016
5 Factors Driving the Graph Database Explosion

There’s no denying it: Graph databases are hot. According to DB-Engines.com, graph databases have outgrown every other type of database in popularity since 2013, and not by a small margin either. It’s clear that developers, data scientists, and IT pros are just beginning to explore the potential of graph databases to solve new classes of big data analytic and transaction challenges.
Here are five reasons why graph databases are surging in popularity now:
1. It’s All About Relationships
As organizations accumulate large stockpiles of data, it’s only natural to want to know what’s in it. There are many ways to query data, but one of the most interesting approaches involves seeing how various pieces of data are connected, and what relationships exist among the data. That’s one of the capabilities that graph databases excel at.

Graph databases have seen the greatest rise in popularity over the past three years according to the database tracking website DB-Engines.com
In a graph database, similar pieces of data are connected directly to one another through common attributes. Relationships are “first-class citizens” in graph databases, unlike in relational databases, which must use special properties like foreign keys to link similar pieces of data, according to a blog post by Neo Technologies, which develops the popular Neo4j database.
Graph databases are useful for storing data that refers to things that are naturally connected in the real world, such as groups of people on social networks, devices on a wide area network, vehicles on a road network, or even chemical structures in families of organic compounds. Storing individual pieces of data as “nodes” in a graph, which are connected to each other via “edges,” enables organizations to quickly gain new views on data in ways that would be very difficult to do using relational data structures.
This method data storage makes graph databases useful for applications where relationships play a major role or are a key element. Popular areas where graph databases are used today include product recommendations (“Person A is connected to Person B, and therefore is more likely to buy Product Z”), network troubleshooting (“Packet X is similar to Packet Y because both originated from Location C”), and cybersecurity and fraud detection (“Malware Q is connected to Malware P, because both originated from Hacker D”).
2. Speedy Performance
One of the main reasons developers are choosing graph database is performance. For certain types of big data problems–particularly those that involve analyzing the relationships among millions or billions of entities–a graph database will outperform nearly every other type of out-of-the-box database in existence.
 In some cases, a graph database can run queries that would be prohibitively expensive, or even impossible, to run on other databases. For example, a graph database that’s powering a recommendation engine can efficiently compare the properties of entities that it stores—perhaps recording the musical tastes of people who are represented as entities in a graph–and return the results within seconds, whereas it could take minutes or hours for the equivalent operation to be executed on a relational database using a table-join operation.
In some cases, a graph database can run queries that would be prohibitively expensive, or even impossible, to run on other databases. For example, a graph database that’s powering a recommendation engine can efficiently compare the properties of entities that it stores—perhaps recording the musical tastes of people who are represented as entities in a graph–and return the results within seconds, whereas it could take minutes or hours for the equivalent operation to be executed on a relational database using a table-join operation.
A graph database won’t be the ideal data store for every type of transaction that your organization needs to execute. There’s a good reason why relational databases still dominate the market: People are imminently familiar with them, and they work very well for transaction processing and serving SQL queries for BI and reporting–although it’s worth noting that some graph databases, such as Neo4j, support ACID properties, and are often used to power (or at least supplement) transactional systems.
But for certain types of data, like data from social networks, devices on the IoT, and other data that’s inherently of a highly connected nature—it’s tough to beat graph. That’s why many big companies—some in the business say all big companies–are investing in graph technologies.
“It’s become clear that by the end of this decade,” Neo CEO Emil Eifrem told Datanami in early 2015, “every single Global 2000 company will have at least one if not several graph projects within their company.”
Indeed, that view is backed by Forrester analyst Noel Yuhanna, who said in his 2015 report on graph databases that the technology is “embryonic but will grow significantly.” Yuhanna said he expects graph database to be adopted by more than 25% of enterprises by 2017.
3. Semantics Matter
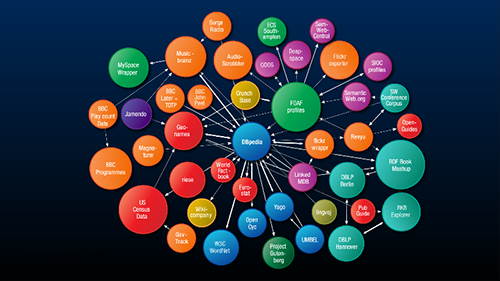
Semantic and RDF technologies make it easier to isolate connections among entities from different classes
You may have heard the phrase “Semantic Web” and wondered what it meant. As it turns out, it’s all about the organization of information across the Net, and making it more people-friendly, as opposed to the chaotic mishmash that has basically defined the Internet for much of its existence.
Semantics are near and dear to what graph databases do, particularly those that adhere to the World Wide Web Consortium’s (W3C’s) Resource Description Framework (RDF) specification, such as Franz‘s AllegroGraph, GraphDB, Cray‘s Graph Engine, MarkLogic’s multi-modal database, and Cambridge Semantics Anzo Graph Query Engine. (Property graph databases, such as those from Neo4j, OrientDB, TitanDB–which Datastax is building into its enterprise Cassandra offering, which Amazon Web Services [NASDAQ: AMZM] offers hooked into its DynamoDB NoSQL-as-a-service offering, and which IBM [NYSE: IBM] recently offered as a standalone service on the Bluemix cloud–are the other main type of graph databases seen in the market.
RDF stores are especially good at maintaining the connectedness of multiple entities, in much the same way that humans think about the world. In his new book “The Nature of Graph Data,” IT analyst Robin Bloor notes that the very nature of graphical structures enables them to naturally record both verbs and nouns.
“The two nouns, buyer and book, are related together by the act of purchasing (a verb),” Bloor writes in the ebook, which was sponsored by Cray. “Note that both ‘nouns’ and ‘verbs’ can have attributes. Again, when data volumes get large, it is preferable to hold data of this kind in a graphical structure because it is semantically meaningful to do so.”
4. Graphs Make a Difference
The science and math behind graphs have been around for hundreds of years, but graph databases have only been around for about 10 years, with the biggest impact coming during the last two or three. While graph databases occupy just a slim percentage of the overall database market, the early returns on the technology are promising.
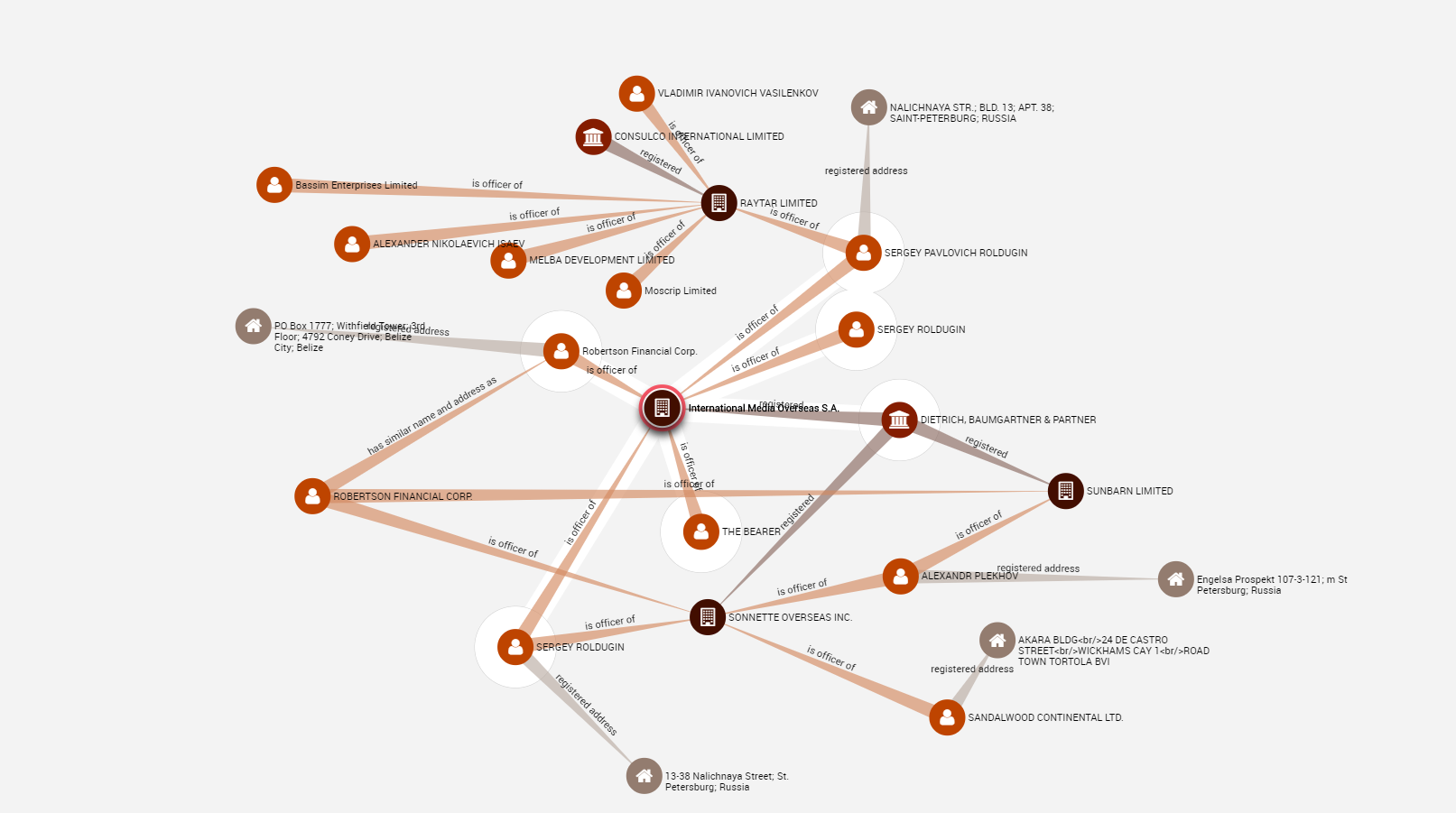
In the Panama Papers investigation, graph database technology allowed the ICIJ to identify connections among a large number of individuals, legal entities, and transactions
For example, in the field of precision medicine, Franz is working with Hadoop distributor Cloudera and chip giant Intel (NASDAQ: INTC) to build a big data analytic platform at Montefiore Health System in New York City. The idea is to enable Montefiore to build a semantic data lake (SDL) that lets medical professionals analyze and find patterns among large amounts of data from a variety of systems, such as patient histories, genetic test results, drug interaction databases, and even external demographic data stores.
“Think of it like a huge knowledgebase about diseases and proteins and genes and everything having to do about human physiology,” Franz CEO Jans Aasman told Datanami a year ago. “We can take all these things in, and without even modifying them, load it into our system.”
We’re also seeing graph technology advances other causes, including the detailed dissection of conspiracies in the news media. Earlier this year, the International Consortium of Investigative Journalists (ICIJ) revealed the results of a study into the supposed illegal offshore transactions that the Panamaian law firm Mossack Fonseca allegedly executed on behalf of its clients, a who’s who of foreign leaders and wealthy businessmen.
The Panama Papers, as the event has been dubbed, certainly would not have occurred if an inside source had not leaked to journalists a massive collection of 11.5 million documents from the law firm dating back to 1977. And the ICIJ may not have been able to dissect the complicated transactions involving numerous shell companies and beneficiaries without the benefit of graph technology, specifically the Neo4j database and a front-end graph interface form Linkurius.
5. Ask Tough Questions
The way graph databases work melds very nicely with the type of questions that people want to ask these days, particularly when the source data sets are of a large and highly connected nature. Of course, giving answers to tough questions is ultimately the goal of many tools in the big data analytics spectrum. But graph databases are particularly well positioned to give us an advantage.
“Everybody thought that big data would make everybody’s job easier, when it fact we know it’s made everybody’s job a lot harder,” John Rueter, the vice president of marketing for Cambridge Semantics, told Datanami earlier this year soon after acquiring Barry Zane’s startup SPARQL City. “[W]th the graph technology, you’re able to traverse all of the data and on a dime spin and ask new questions…It mimics the way we think and the way we want to ask questions of our data.”
Graph databases are already helping organizations in retail, financial services, healthcare, and security fields, and with the growth of new data from the IoT, the use cases for graph are expected to soar.
Zane, who created the ParAccel column-oriented database that today is at the heart of Amazon’s RedShift offering, says graph technology is the logical place for the next stage of the evolution of big data analytics.
“We strongly believe that this is an extremely effective approach, a future-proof approach,” Zane told Datanami earlier this year. “Just as Hadoop basically came of maturity because relational just wasn’t able to work with a certain class of question and wasn’t able to work at a certain scale, we pursue those classes of questions and scale using the graph standards, at an incredible cost and performance advantage, as compared to hiring programmers for every question and analytic you want to perform.”
Related Items:
Inside the Panama Papers: How Cloud Analytics Made It All Possible
The Bright Future of Semantic Graphs and Big Connected Data
Graph Databases Everywhere by 2020, Says Neo4j Chief
Vendors:
Amazon, Cambridge Semantics, Cray, DataStax, Franz, GraphDB, IBM, MarkLogic, Neo Technologies, OrientDB
Leading Solution Providers
















