

October 21, 2015
Neo4j Touts 10x Performance Boost of Graphs on IBM Power FPGAs

Neo Technology today announced that it’s working with IBM to support its graph database on IBM Power8-based servers equipped with field programmable gate arrays (FPGAs). This will enable customers to run graph databases with hundreds of billions to trillions of edges, thereby tackling a new class of intractable big data problems in bioinformatics, fraud detection, and IoT analytics. In other news, Neo also open sourced a key piece of software.
Like most NoSQL database vendors, Neo Technology supports its software on distributed, scale-out clusters of commodity X64 computers. But some of the biggest graph problems are best solved by keeping the entire graph within a single memory space, which is why some Neo4j customers run on big symmetric multi-processor (SMP) machines, such as IBM‘s venerable Power line.
IBM–which has been adding NoSQL capabilities to its DB2 database and generally emulating smaller and nimbler innovators in the open source, big data arena–recently approached Neo Technology with the idea of supporting the Neo4j graph database on Power servers. But the proposal went beyond just supporting Neo4j on Little Endian Linux running on Power, which would have provided an iterative boost in performance, but nothing really different or special.
Instead, the companies did the hard engineering work to support Neo’s industry-leading graph database with the performance-boosting FPGA cards IBM has been adding to its Power Systems and OpenPower boxes to augment the performance of Power8 CPUs. According to the details of today’s announcement, the Neo4j database is bypassing the Linux operating system and the file system entirely by running atop the Coherent Accelerator Processor Interface (CAPI) ports that allow the database to access many terabytes of flash memory (up to 40TB of it) just as if it were main memory.
It’s akin to “cutting out the middle man” and having Neo4j run straight atop the Power8 processor, explains Philip Rathle, Neo Technology’s vice president of products.
“The result is up to 10x the I/O bandwidth for the graph compared to running on Intel X64 servers or Power without CAPI flash,” he says. “You’re offloading all the I/O from the CPU…and so if you relieve that work from the CPU, then you can use it for computation and do bigger and more powerful things.”
Running Neo4j on massive FPGA-equipped Power Systems and OpenPower boxes from IBM will change the economics of what’s possible with graph databases, Rathle says. “This raises the bar of the state art of what’s possible with graph databases by about 10x,” he says.
The new technology will allow customers to push the limits on the size of graph database and solve problems that were previously unsolvable, he says.
“While it’s not entirely clear how people are going to use it, we have pretty good guesses. Internet of Things, bioinformatics, fraud detection. The more data you can bring into your fraud detection system and the more connected your queries are, the better your chance of stopping the fraud.”
Support for Power8 processor is being delivered in Neo4j version 2.3, which the company unveiled today at its GraphConnect conference in San Francisco. Interested parties can ask to participate in the beta program for CAPI support; the feature is expected to be available in 2016.
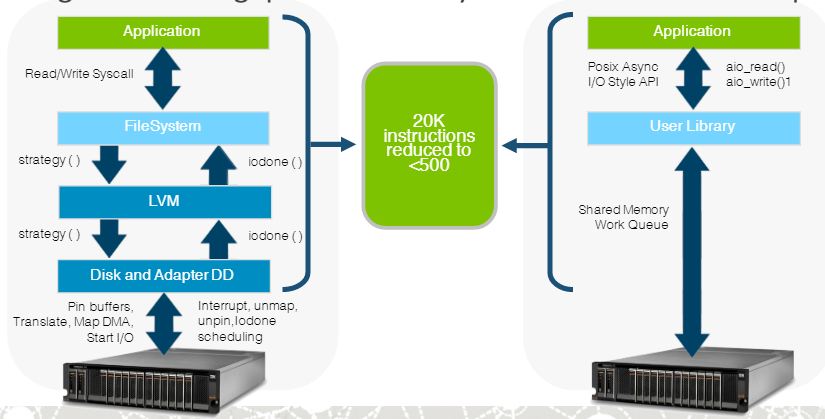
Neo4j is cutting out the middleman and running close to the Power processor. Source: Neo
Neo Technology has always had a strong scale-out story, but running atop Power8 and the FPGA opens a new chapter for Neo4j’s scale-up story and adds a new wrinkle to graph analytics, says CEO Emil Eifrem.
“At the end of the day, if you have a really, really huge graph and you split it up across a number of machines and you do that in a way that’s not mindful of the shape of the graph, then you can end up in a situation where you need to hop a lot across the network in order to return a proper response to the user,” Eifrem says. But if you can scale up, “then all of a sudden, instead of hoping across the network….you can do that inside of one single memory space…It’s going to open up a number of new use cases for graph analytics.”
The Power8 CAPI support will enable customers to run giant graphs–those with hundreds of billions to trillions of edges, Rathle says. But it’s not just the number of edges in the database that matter, but the connectedness of the data too, he says.
“The more interesting queries tend to be the ones where you’re starting push the limits, where it’s not just one hop or two hops,” he says. “As people work more and more with graph data, what we’re seeing is they want to bring more data in. They want to go deeper and really find influences a few more levels out.”
For example, one company in the food supply chain sought out Neo4j because it was having difficulty scaling a relational database for a supply chain application that tracks the ingredients in food. They were able to go three levels down with the relational database, but they needed to go 20 levels down.
Detecting fraud hidden in huge data sets should be easier with Neo4j running on Power8.
“So if a pieced of contaminated food comes out somewhere, they could just follow that batch and item and all the different ingredients all the way up the supply chain, however many levels, to the problematic place, and then spider all the way back out and do a recall, and do that as quickly as possible to minimize the liability,” Rathle says.
As if running on Power8 servers wasn’t news enough, Neo also announced that it’s contributing its graph query language, Cypher, into the open source realm.
“Up until now it’s been something that’s been proprietary,” Rathle says. “Over time had a lot of people come to us and say, it’s time for a standard. Can you contribute Cypher? And we’ve always felt that just as SQL propelled the growth of the relational database, you would eventually need a common language that’s vendor independent and high quality, like SQL for graph.”
The move gained the approval of Oracle and Databricks (the company behind Apache Spark). “This is the biggest thing to happen to the graph database space,” Rathle says. “It really signals an inflection point. The analogies to SQL are very clear. I think that’s how the mainstream adopters are going to look at it–the defacto standard query language for graph.”
Related Items:
Neo Tech Cranks Up Speed on Upgraded Neo4j
Graph Databases Everywhere by 2020, Says Neo4j Chief
Neo Rides the Graph Database Surge
Tags:
CAPI, fpga, Graph Analytics, graph databases, IBM, neo technology, neo4j, Open Power, power systems, Power8
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States