

January 20, 2017
How These Banking, Energy, and Pharma Firms Use Spark

(Pakthongchai/Shutterstock)
Few frameworks have gained so much popularity as quickly as Apache Spark. The open source technology may not be ubiquitous yet in the analytics world, but it’s fast approaching that point.
Spark has certainly caught on among Web giants in the Silicon Valley, where it’s often paired with Hadoop, Kafka, Cassandra and other open source tools to process big and fast-moving data. But the real mark for Spark may be how quickly it’s been adopted by real-world companies.
Among the firms using the in-memory technology are credit card company Capital One, the drug giant Roche, and DNV GL, an energy consulting firm. These companies attended a recent Spark Summit hosted by Databricks, the commercial outfit behind the Apache Spark project. Here are their stories.
Spark at Capital One
Like all credit card firms, Capital One actively fights fraud by identifying unauthorized transactions as quickly as possible. Fraudsters steal about $20 billion annually from over 10 million Americans, which credit card firms have no choice but to write off as losses.
In a Spark Summit session last June, Capital One Vice President of Technology Chris D’Agostino explained how the credit card firm uses a Spark cluster paired with a graph database to track down fraudsters. This particular system is used to screen credit card applications as they’re submitted to the company, and utilizes Spark, the Databricks data science notebook, and Visallo, an investigation and case management tool built atop Hadoop, Accumulo, and Elasticsearch.![]()
“We’re able to score these applications in real time using machine learning libraries in Spark,” D’Agostino says. “So once an application arrives at Capital One, we can determine what attributes and what features make up that application and determine if it’s connected to other applications that have come in, or historical applications.”
A key part of the solution is determining the “connectedness” of application, which is accomplished by analyzing fields such as Social Security numbers, email addresses, and cell phone numbers. “You might not be surprised to know that fraudsters will use the same email address over and over again so they don’t have to create multiple email addresses and check multiple accounts,” he says. (Thank goodness for lazy fraudsters.)
If the logistic regression model flags an application as potentially fraudulent—which is done in a matter of milliseconds, D’Agostino says—the system allows the Capital One analyst to quickly shift into case management mode for further exploration using histograms, dashboards, and even maps that plot the physical addresses of all connected applications on the screen.
The use of RESTful APIs helps smooth integration and minimize the “impedance mismatch” that analysts face when switching among data warehousing, operational environment, loss mitigation environments, D’Agostino says.

Capital One’s Spark-based fraud-fighting system lets analysts quickly shift gears into different personas
“We’re excited about Spark and we’re excited about Databricks in particular with the notebook solution to provide that unified platform for data scientists, data engineers, and business analysts–all with varying degrees of technical skills in terms of programming capability,” says. “We’re able to have analysts work within different notebooks, share those notebooks, schedule those notebooks to run on a periodic basis, and be able to let people use the programing language of their choice and the query language of choice, whether SQL or graph query.”
Spark at Roche
Wei-Yi Cheng, a data scientist at the pharmaceutical company Roche, is using Spark with his research into potential immunotherapy treatments for cancer. The research involves analyzing images of tumors to try to determine whether certain types of cancer are treatable using this new immunotherapy method.![]()
The key to the research is identifying the distribution of different cell types in the cancer, including the bad cancer cells, the good T-cells that are produced by the body’s immune system, and blood vessels. In any given image of a tumor taken by a microscope, there may be millions of different cells that Cheng wants to analyze, but calculating the distances between all of them is too computationally expensive.
That’s where Spark comes in. Cheng and his Roche colleagues are using a Java-based library package called Spatial Spark to give them a jumpstart on these calculations. The pipeline starts with the output of computer vision algorithms that have already gone over the raw images of tumors to extract feature information, which is bundled up into an object that contain coordinates of interest.
“Then we load everything into Hadoop in a Parquet format, so we can easily load and more efficiently query them,” Cheng says. “We use Spark to load the Parquet file, and use Spatial Spark to calculate the distances. We’ll create a huge distance peer list, which compares the two different unique object IDs, and the exact distance within a certain window that you set.” The results are loaded back into Hadoop, and analyzed using a combination of Impala and Python.

The location and density of different immune cell populations are associated with patient prognosis and prediction outcome (Source: Roche)
This approach gives Roche researchers insight into how T-cells are distributed in a tumor and how far they are from blood vessels. This is important information for determining whether certain types of cancers may be good candidates for immunotherapy drugs that the company is developing, and also for determining the biological responses to drugs that have been developed.
The Spatial Spark work was still in the proof of concept phase when Cheng discussed his work at the Spark Summit. It’s a work in progress, Cheng said, adding that the data science work has raised new questions, and that there are new features to quantify. Correlating genomics data, for example, could yield more insights.
But with the “perfectly parallelized” Spatial Spark, Roche has a head start on finding new ways to fight cancer. “It’s quite nice because, basically, before this, we had no way of really of calculating every distance that we’re interested in in the tumor,” Cheng says. “But with this, it becomes possible.”
Spark at DNV GL
Another company finding real benefits to Apache Spark is DNV GL, a large, 150-year-old energy consulting company based in Europe. The company creates statistical models that tell grid operators how much energy they need to be generating for a given day. This is an important job because without a steady supply of electricity, entire grids can go down.
Forecasting energy use is not as simple as it might seem, especially as regions adopt renewal energy sources such as wind and solar and move away from nuclear- and fossil fuel-powered plants. As DNV GL data scientist Jonathan Farland explained at last year’s Spark Summit, juggling the supply and demand of electricity on a given grid is no simple task.
“You see a very complex systems of interactions and forces going on,” Farland says, while showing monthly snapshots of energy usage. “When it’s hot or cold out we use electricity. It changes on weekends and holiday…My job is to decompose what’s going on into something that makes sense.”
Farland developed semi-parametric models that forecast energy demand based on the inputs of several variables, including meteorological data like temperature, humidity, solar irradiance, and wind speed; demographic and financial information from energy consumers; historical energy usage data; and data from the grid itself, such as what’s malfunctioning.
The company previously ran its model on its legacy data warehousing environment. However, that analytics environment is getting congested, as it’s used by 30 to 50 data scientists, analysts, and engineers at any given time. “We can’t scale with our current analytics platform,” Farland says.
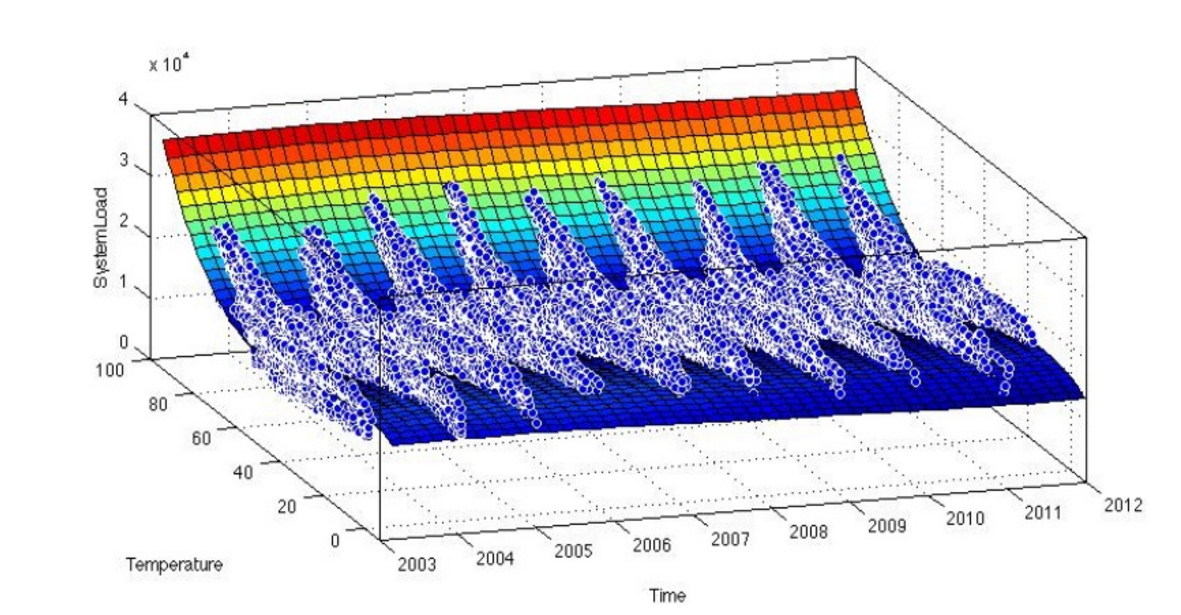
DNV GL’s Spark-based energy prediction model incorporates a variety of factors.
So Farland contacted Databricks with the hope of seeing how the same model would run on a cloud-based Spark environment. After rebuilding the model in Spark R and loading it with about 500GB of data, he had his answer.
The same calculation that took 23 hours on the old server ran in just seven seconds on the cloud-based Spark server.
“We’re not going to just get rid of [the old data warehouse],” Farland says. “But we have mega projects where Spark is a clear winner for this sort of thing. We’re looking at a future where the data generating process is much bigger than it ever has been and we need to be prepared for that.”
Related Items:
Apache Spark: 3 Real-World Use Cases
Spark Streaming: What Is It and Who’s Using It?
How Spark and Hadoop Are Advancing Cancer Research
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States