

October 18, 2016
Big Performance Gains Seen Across SQL-on-Hadoop Engines

You can’t really go wrong these days when it comes to picking a SQL-on-Hadoop engine. As long as you stick to the mainstream open source products like Hive, Impala, Spark SQL, and Presto, your SQL queries are likely running 2-4x faster than they did earlier this year, without changing your queries or buying more hardware.
That’s the conclusion of a new report issued today by OLAP-on-Hadoop software vendor AtScale. The company–which exposes its OLAP processing as SQL queries when running on Hadoop and thus requires an underlying SQL engine to function–found that those four open source SQL-on-Hadoop products all recorded big gains compared to a similar benchmark test it released in March of this year.
“The punchline for us was that the SQL-on-Hadoop wars are continuing, and everybody wins,” says AtScale Vice President of Product Josh Klahr. “The engines are making a lot of good progress. We’ve seen really big improvement, even in the six months between March and September.”
AtScale set up a series of tests on a 11-node Hadoop cluster to measure how well the four open source SQL engines performed given tasks (including performing joins, aggregations, etc) on data sets ranging from about 17,000 rows of data to nearly 6 billion. Since the company supports all of the engines, it can serve as a relatively independent source of objective performance data, especially in lieu of an official TPC-style benchmark for BI workloads on Hadoop.
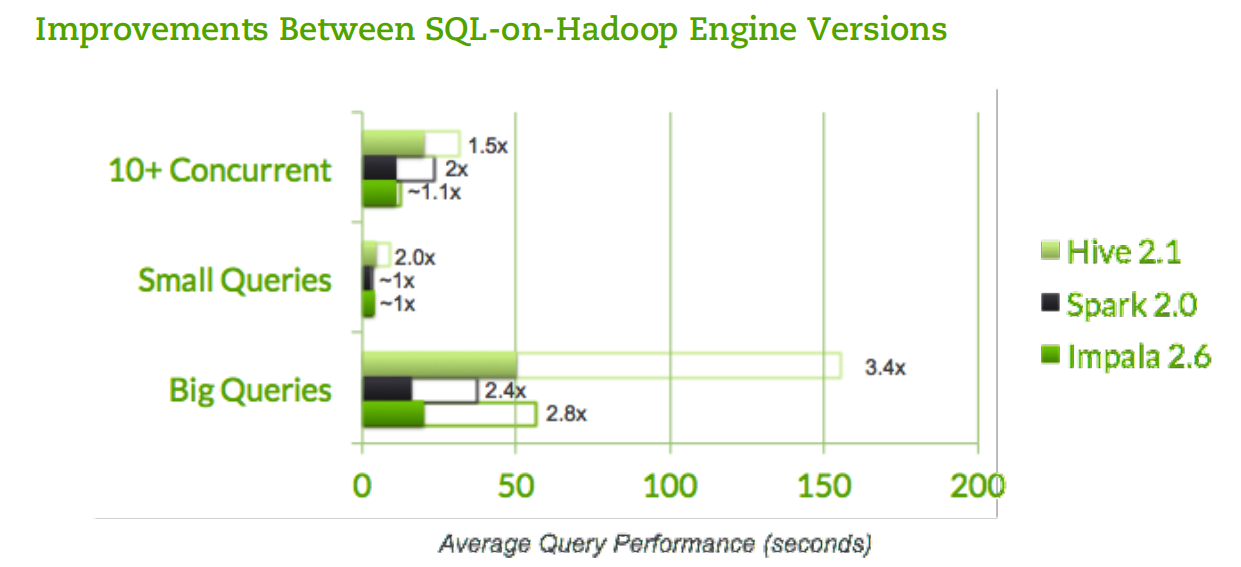
Hive, Impala, and Spark SQL improved by more than 100% in most categories, according to AtScale
The vendor borrowed the Star Schema Benchmark (SSB) data model from the TPC organization and used it to measure how quickly the engines could process 13 different SQL queries that mirrored the types of queries that AtScale’s product is asked to do. (In other words, the benchmark didn’t attempt to simulate the massive SQL queries or hellishly large joins involved in big data discovery or other data science types of workloads. The TPC-DS benchmark is a better predictor of performance for those types of workloads).
AtScale’s test showed
- Hive improved on average 3-4x in the move from Hive 1.2 to Hive 2.1;
- Impala improved on average between 2-3x in the move from Impala 2.3 to Impala 2.6;
- and Spark SQL improved between 2-3x in the move from Spark 1.6 to Spark 2.0 (Presto was not included in the earlier test, so there’s no comparison).
“These engines are moving really, really fast in terms of performance,” Klahr says. “We think this is great just that the engines continue to show this great improvement and all the Hadoop customers are benefiting.”
Not all SQL engines are built the same, however, and there were some notable differences in performance on the different query types. Impala and Spark tended to outperform Hive and Presto overall, particularly as the number of joins increased. “Impala and Spark are much better at handling big joins,” Klahr says.
Impala and Spark are better at processing large joins because they have a feature called runtime filtering, Klahr says. “Run-time filtering reduces the amount of data volume that needs to be scanned,” he tells Datanami. “As you get to really big queries, Impala and Spark are more efficient and smarter about what data they scan and include in the query processing pipeline.”
Presto and Impala did a little better than the other engines in terms of concurrency, or how many SQL queries can it run simultaneously. “Hive and Spark tend to slow down. They’re a little more resource constrained,” Klahr says. “But Impala and Presto are really nice from a concurrency perspective.”
Hive, which is backed by Hortonworks (NASDAQ: HDP) showed the biggest improvement across a number of query types. That’s largely due to the recent work Hortonworks did to bolster the tool with a new data persistent layer that it refers to as LLAP (Live Long And Prosper).
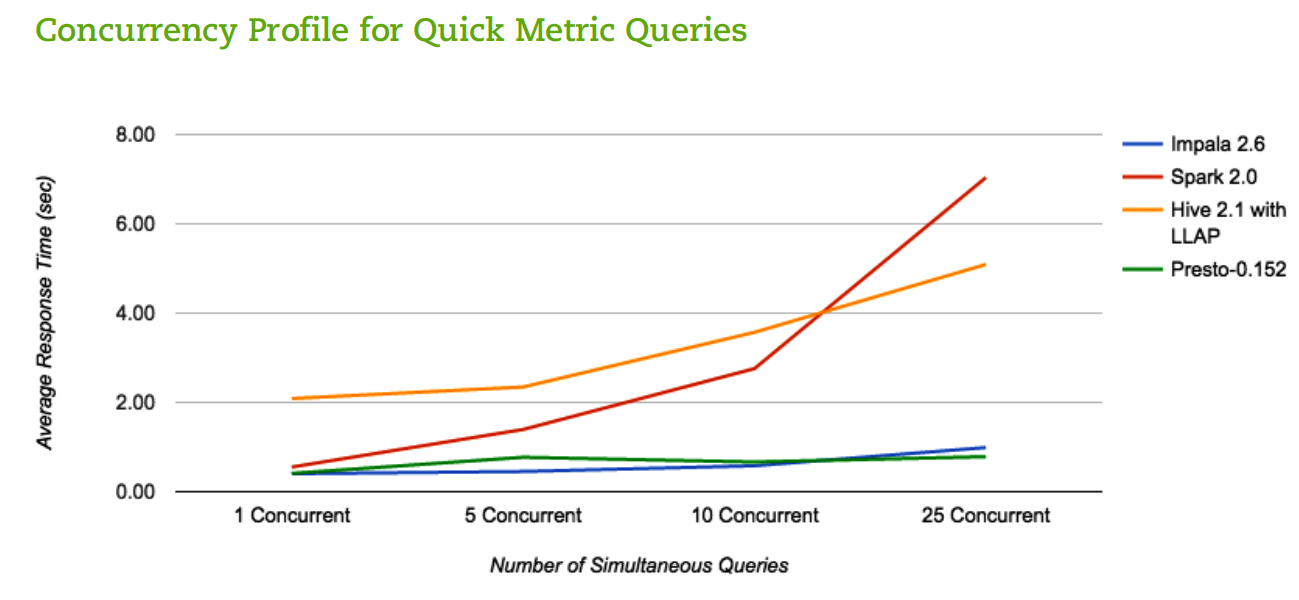
Impala and Presto maintained fast response times even as concurrency was ramped up
“Hive’s Achilles Heel to date has been non-persistent processing,” says Klahr, who previously worked at Pivotal and EMC Greenplum. “Short-running queries used to be a problem for Hive because it had to spin up a process every time. With LLAP, they essentially have a persistent process that’s running on the cluster. What that means is Hive is a lot better at these small queries against aggregate data. That was one of the takeaways from the benchmark is Hive has gotten a lot better when querying small data sets, not just big data sets.”
Hive still has some catching up to do if it’s going to match Presto, which is backed by Teradata (NYSE: TDC) and Impala, which is backed by Cloudera. But thanks to the work Hortonworks did with LLAP, analysts who are working within Tableau (NYSE: DATA) or a Microsoft (NASDAQ: MSFT) Excel pivot table will no longer be waiting two-and-a-half minutes for a query to finish. With a single exception, all BI queries came back in less than 7.5 seconds under Hive, according to AtScale.
That’s good news for the 40% to 45% of AtScale customers who are running HDP. “The joke we have going around the office is we can sit around here and do nothing, and for customer who are running Hive, we’re already 3.4x faster,” Klahr says.
The open source SQL-on-Hadoop engines are progressing faster than proprietary SQL engines, such as HPE’s Vertica (now owned by MicroFocus), BigQuery from IBM (NYSE: IBM), Actian‘s Vortex, or Kognitio’s engine (which was recently ported to Hadoop), as well as SQL engines that were recently open sourced, such as Pivotal’s HAWQ, according to Klahr.
Presto was added to the test after a number of AtScale customers inquired about it, he says. The next one on the list in terms of popularity appears to be Drill, the SQL engine backed by MapR, which makes up about 10% of AtScale’s customer base. “While we’ve had some interest in Drill, we have yet to see a production environment that’s using it,” Klahr says. “It would probably be the next one on the list. We think architecturally Drill has some nice components.”
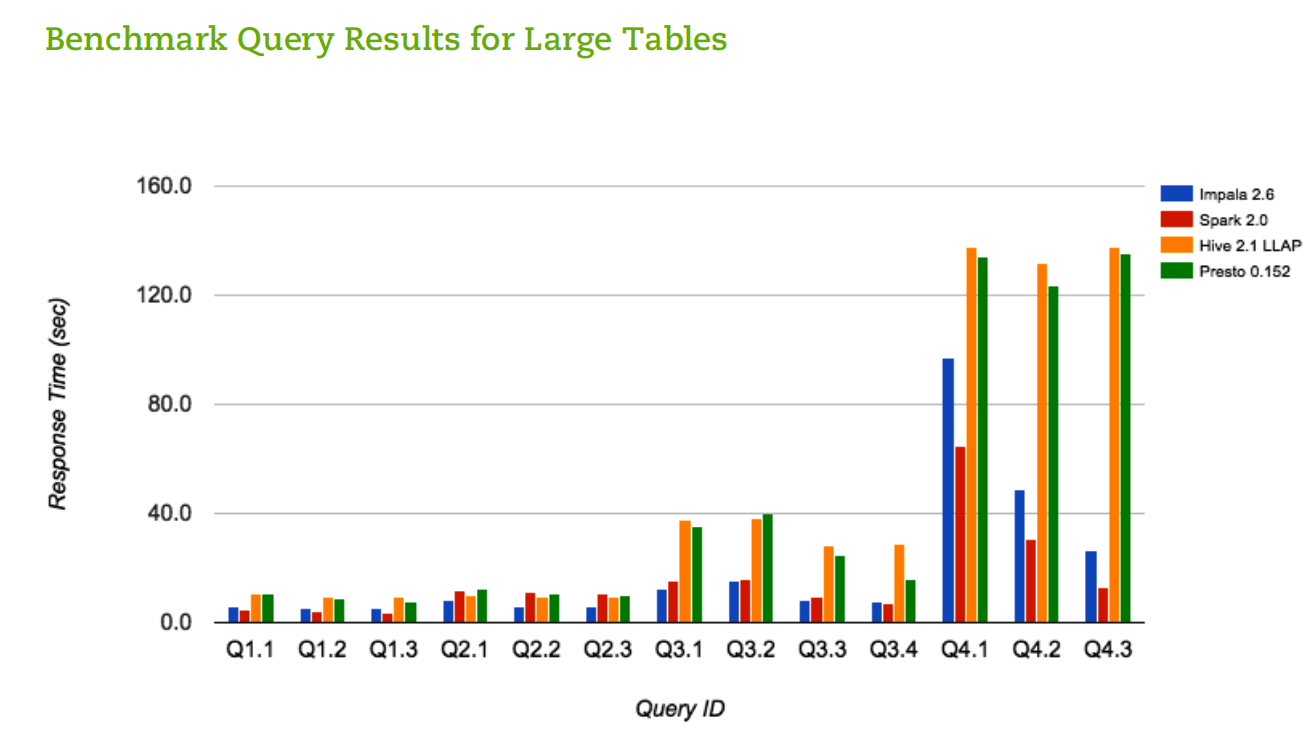
You can see how the 4 SQL engines performed on different queries on large tables
Klahr says proprietary SQL-on-Hadoop engines like BigQuery, Vertica, and Vortex (and the recently open-sourced HAWQ engine) still possess some advantages, including better coverage of the analytic components of the SQL 92 standard, and more mature query optimizers and query planners. Those architectural advantages give these proprietary engines the edge in massive-scale query workloads, including the types that TPC is seeking to measure with its new TPC-DS benchmark.
But those advantages won’t last long, he says.
“The velocity that the open source engine are achieving in terms of catching up is promising,” he says. “The gap between the proprietary traditional MPP architectures that have been ported and have the really mature query optimizer, and the new open source engines like Impala or Presto–the gap is going to continue to narrow, and at some point the benefit of using something that was built from the ground up for Hadoop will start to outweigh the remaining performance gains you get from a proprietary engine.”
At the end of the day, there will be room for multiple SQL-on-Hadoop engines. “It’s all about picking the best tool for the job,” he says. “That’s the nice thing about Hadoop.”
Related Items:
Picking the Right SQL-on-Hadoop Tool for the Job
SQL-on-Hadoop Test: Each Engine Has ‘Sweet Spots’
New TPC Benchmark Puts an End to Tall SQL-on-Hadoop Tales
Vendors:
actian, AtScale, Cloudera, EMC, Hortonworks, HPE, IBM, Kognitio, MapR, Microfocus, pivotal, Teradata
Tags:
benchmark, Hadoop, Hive, impala, performance, presto, query performance, Spark, Spark SQL, SQL engines, SQL on Hadoop, wait time
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States