

September 28, 2016
Commercial Kafka Distro Gets Global Smarts

Companies operating multiple Apache Kafka clusters in on-premise and cloud data centers will benefit from a handful of new enterprise-level features unveiled at the Strata + Hadoop World conference today by Confluent, the commercial open source company behind the popular big data message bus.
Confluent today announced that its enterprise-strength Kafka offering, called Confluent Enterprise, is getting three key new capabilities in the version 3.1 release that will ship next month, including multi datacenter replication, automated cross-cluster data balancing, and a cloud-migration facility.
The new multi data center (MDC) replication capability and data balancing features, in particular, are expected to significantly simply enterprise Kafka operations for multi-national organizations adopting Confluent Platform Enterprise as the core of their streaming data initiatives. More than 35% of the Fortune 500 companies have deployed Apache Kafka
“This is a really big deal for Kafka users because literally every single customer that Confluent has, has deployed Kafka across multiple data centers,” says Confluent co-founder and CTO Neha Narkhede. “The fact that data lives across different locations actually means you need to synchronize data.”
The MDC replication capability is superior to a previously available open source product called MirrorMaker. The proprietary MDC replication capability that Confluent will deliver in the subscription-based product is more advanced and production-ready than MirrorMaker, Narkhede says.
“We learned a ton from that experience [developing MirrorMaker] and baked it into the tool,” Narkhede tells Datanami. “This is asynchronous across data centers in our first version. What we will guarantee is that every single piece of data in on particular data center is in order to the other data center. And there will be full monitoring end-to-end to make sure that users have visibility into how that’s happening.”
Confluent Platform Enterprise customers will be able to set up the replication to suit their specific needs. “You can set it up to mirror one-to-one copies of all your data across data centers,” Narkhede says, “or you set up more of a geo-replication mode, which is feeding multiple data centers into one data center that might be feeding your analytical systems in parallel.”
The new automatic data balancing feature will help to ensure that production Kafka clusters stay online as new nodes are added to handle demand.
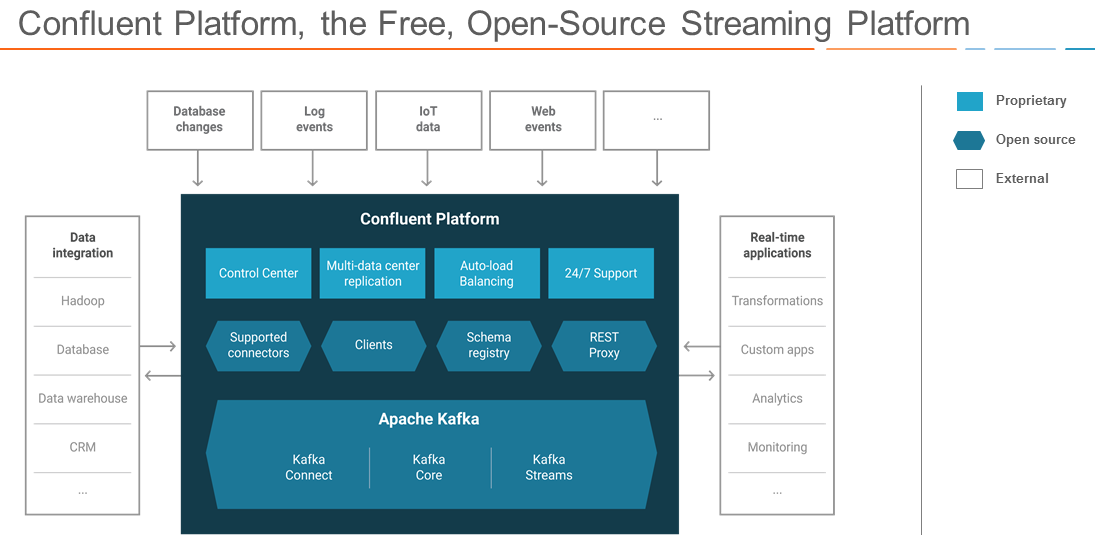
Confluent Enterprise includes a mix of open source and proprietary components
“This capability in Confluent Enterprise offers a fully automated solution and a very efficient algorithm to balance data efficiently across a cluster of machines while respecting user-defined quotas,” Narkhede says. “This is the second proprietary capability in Confluent Platform, and pretty much a feature that the Kafka community has been waiting for for a really long time.”
The last major new feature—the new facility to automatically move data from on-premise clusters to cloud-based Kafka clusters—is a logistical extension of the MDC and data-balancing features. Confluent developed it because many Kafka customers with multiple data centers invariably have data and applications reside ding in the cloud.
“For a lot of companies, what that actually means is they’re trying to move data from on-premise to the cloud,” Narkhede says. “When you do that, you need a common replication layer that allows you to copy data from your premise data center to the cloud.”
2016 has been a big year for Confluent, which has emerged as one of the hottest tech startups thanks to the rise of Apache Kafka as the defacto standard data transport method for moving big data from their source to their destination. While Kafka itself serves as the data movement layer, Confluent is also looking to take Kafka “up stack” by adding basic stream processing capabilities to the project.
Kafka Streams, which is part of the free and open source Apache Kafka offering, provides simple stream processing capabilities, including data transformation for streaming data. Kafka Connect, meanwhile, is the Apache Kafka component that provides an array of connectors for streaming data from an array of sources to their destination.
Confluent shared a few other facts about Kafka adoption. The company says that Kafka is being used by seven of the top 10 global banks, eight of the top 10 insurance companies, nine of the top 10 U.S. telecom companies and six of the top 10 travel companies.
Related Items:
Confluent Gives Kafka More Enterprise Chops
The Real-Time Rise of Apache Kafka
Kafka Gets a Stream-Processing Makeover
Editor’s note: This article has been corrected. The new MDC replication feature is not based on Mirror Maker, as the story previously stated. Also, Kafka Streams and Kafka Connect are part of Apache Kafka, not part of Confluent’s platform. Datanami regrets the errors.
Vendors:
Confluent
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States