

December 8, 2015
Confluent Gives Kafka More Enterprise Chops

Confluent today unveiled a major new release of its commercial product based on Kafka, the open source data messaging platform that’s quickly gaining momentum. With better security, new data connectors, and simplified integration, Confluent 2.0 promises to attract even more attention from large enterprises that are moving big data with Kafka.
The adoption rate for Kafka has soared by 7x in just the past 11 months, according to Confluent, which was founded by the folks who created Kafka while at LinkedIn. Uber, Netflix, Cisco, and Goldman Sachs are all using Kafka’s publish-subscribe messaging bus to quickly move data from one system to another, and to keep multiple big data applications running on Hadoop, Cassandra, ElasticSearch clusters in synch.
That heady adoption of Kafka comes with a list of requirements for enterprise-strength features. One of those is to automate the process of building connectors that allow certain databases or applications to easily plug into the Kafka architecture. That’s where the new Kafka Connects plays.
“We saw people doing a lot of hand-coding,” Confluent CEO Jay Kreps says. “We found [building connectors] by hand is OK if you have three or five things you want to hook up. But a lot of companies that are building these cool streaming platforms have hundreds of databases that hook up to dozens of systems with big clusters. So we’re taking that use seriously.”
Confluent has shipped the initial set of Kafka Connect plug-ins for ElasticSearch, HDFS, and JDBC. Getting data flowing into or out of these systems (via Kafka) is a simple matter when using the plug-ins.
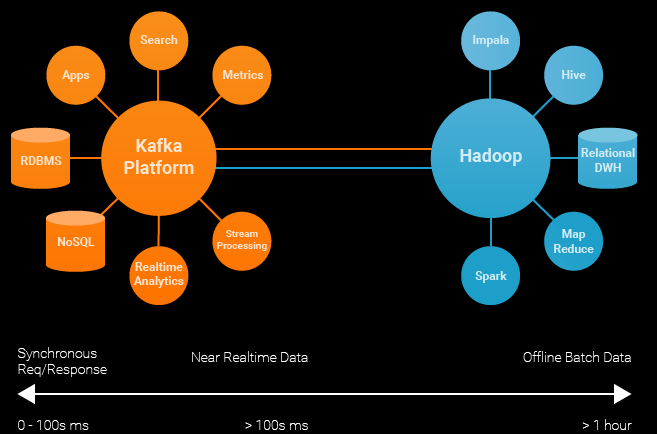
Confluent sees separate clusters for Kafka and Hadoop supporting different data missions
Confluent is also shipping a REST interface with Confluent 2.0, which is based on Kafka version 0.9 (Apache Kafka is free and open source, while Confluent charges for maintenance to get the extra capabilities in its enterprise-strength product). The REST API will make it even easier to hook other data sources into Kafka.
Confluent 2.0 also brings new features that should help deployment in the enterprise, such as fine-grained authentication, encryption, and throttling capabilities. Getting stronger security into Kafka was important, Kreps tells Datanami.
“This obviously helps to control access to data on a cluster that’s shared by multiple users,” Kreps says. “In the past you could control access on network layer but it was very course grained. You couldn’t really [fully control] access on a stream-by-stream basis. This brings that security level up into Kafka itself and makes it possible to have these shared clusters across a larger organization.”
Occasionally a big stream can suck up all the bandwidth available in Kafka, which can wreak havoc on other production systems relying on Kafka to keep streams of data available. That’s why Confluent introduced the new throttling capabilities.
“It’s making sure that read and writes from one applications can’t suck up too many resources,” Kreps says. “It makes usage possible in a big shared environment, where not everybody trusts each other to do the right thing.”
Confluent 2.0 also brings a new Java Consumer that presents a “unified consumer API” and eliminates dependencies on ZooKeeper. This opens the door to the creation of non-Java clients. The first one, for C++, is nearing completion, Kreps says.
There’s a dozen or so other languages, like Python or Scala, that Kreps has his eye on. “We’re going to be adding more clients to our platform over time,” he says. “When we add a client we want to make sure we bring it up to parity with what the other clients have.”
![]() The clients will make it easier to plug Kafka into existing applications in the growing big data ecosystem. In general, customers interact with Kafka systems in three ways. First they can use the API directly, and call Kafka routines from other apps. Secondly they can Java Connects plug-ins. Lastly, they can access it directly using real-time stream processing application, such as Apache Streaming or Apache Storm. The new clients will help integrate Kafka with these popular big data frameworks.
The clients will make it easier to plug Kafka into existing applications in the growing big data ecosystem. In general, customers interact with Kafka systems in three ways. First they can use the API directly, and call Kafka routines from other apps. Secondly they can Java Connects plug-ins. Lastly, they can access it directly using real-time stream processing application, such as Apache Streaming or Apache Storm. The new clients will help integrate Kafka with these popular big data frameworks.
The big data ecosystem is growing rapidly, and Kafka is literally in the middle of it, doing the hard work of moving data and keeping data in sync in a fault-tolerant manner. As the ecosystem grows, Kreps envisions Kafka playing an even bigger role to simplify the data integration problem.
“There’s so many of these custom integrations out there to hook up different services,” he says. “It all falls on the company who’s trying to adopt these things to instrument these, one stream at a time. In the long term we’ll see the move to an architecture where there’s central streams of data and everybody taps into that central stream rather than go milling around and putting custom agents on every machine in the data center….Over time I think that system will start to develop.”
Related Items:
Kafka Tops 1 Trillion Messages Per Day at LinkedIn
The Real-Time Future of Data According to Jay Kreps
LinkedIn Spinoff Confluent to Extend Kafka
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States