

June 8, 2016
Apache Spark Adoption by the Numbers

(Robolab/Shutterstock)
It’s been about three years since Apache Spark burst onto the big data scene and became one of the hottest technologies on the planet. Judging by the numbers surrounding Spark’s adoption—including things like salaries, attendance, and committers–the future of Spark looks quite bright.
Wondering how much money Spark developers make? (We know you are!) According to Tech Overflow’s latest developer survey, Spark tied with Scala for the top-paying job in technology, with Spark developers in the U.S. earning an average of $125,000 per year.
It’s interesting to note that Spark and Scala were tied, considering that Spark was largely written in Scala, and that Scala remains the most popular language for programming Spark applications. From a global perspective, Spark was the fourth highest paying job, behind F#, Dart, and Cassandra.
In terms of sheer popularity, Spark had the second-biggest year-over-year increase (163.5%) in the number of votes among all developers on Stack Overflow. It was behind React, an up-and-coming JavaScript framework for developing apps on Facebook and Instagram, but ahead of other big data-related technologies like Cassandra, Python, MongoDB, R, Redis, and Hadoop.

Spark salaries lead among developers in the U.S.: (Source: Stack Overflow survey)
You’ve probably heard that Spark is the top open-source big data project, topping Apache Hadoop and other big data projects. In September 2015, Databricks released results from a survey showing that Spark had more than 600 contributors within the past year, which was nearly doubled from the previous year.
Today, there are over 1,000 contributors to Spark, Databricks executives said at this week’s Spark Summit conference in San Francisco. Databricks says there are 2,500 attendees at the event, which wraps up today. That’s a 5x increase compared to the first Spark Summit held in December 2013.
It’s safe to say that, if you’re a big data developer, you’re probably interested in Spark, among a number of other technologies. According to a recent survey by Syncsort, nearly 70% of respondents stated they’re most interested in Apache Spark, which surpassed interest in all other compute frameworks, including MapReduce, which had a 55% share of developer interest. This was a clear indication that Spark was moving from data science project into production-grade technology, the company said.
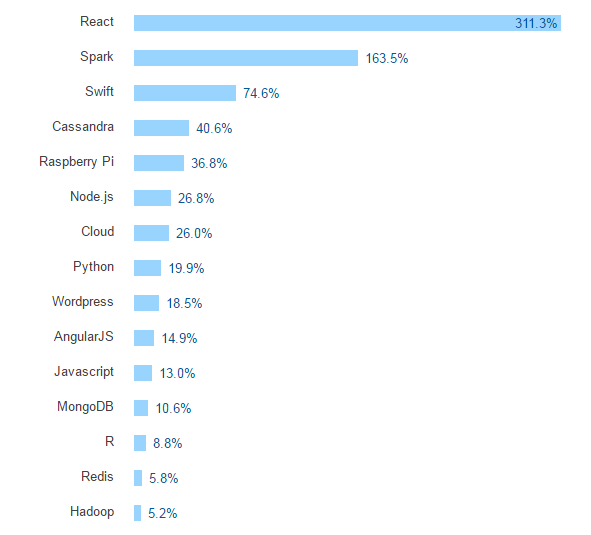
Spark is second only to React in terms of the increase in devloper votes at Stack Overflow
These findings were backed up by a recent report from Wikibon analyst George Gilbert, who concluded that Spark-based investments will capture 6% of total big data spending, growing to 37% by 2022. Considering the widespread adoption and support that Spark is getting from the big data industry, that prediction would seem to be solid.
While Spark is primarily considered to be a tool for data scientists to use, it appears the technology is reaching past the unicorns to bring mere mortals into the fold.
According to a recent Databricks survey, 60% of the people using Databricks Community Edition (DCE)–the company’s Spark-in-the-cloud environment that just became generally available yesterday after a four-month beta–are neither data scientists nor data engineers. What’s more, one out of four DCE users have never used Spark before, which shows how the technology is spreading to new users.
How are people using Spark? We got some insight into this question from a survey Databricks conducted in late 2015.
According to the survey, Spark SQL is the most popular component of Spark, with 69% of Spark users reporting that they use this feature. The second most popular Spark component is Dataframe (62%), followed by the combination of MLlib and GraphX (58%) and Spark Streaming, which tied MLlib+GraphX at 58%.
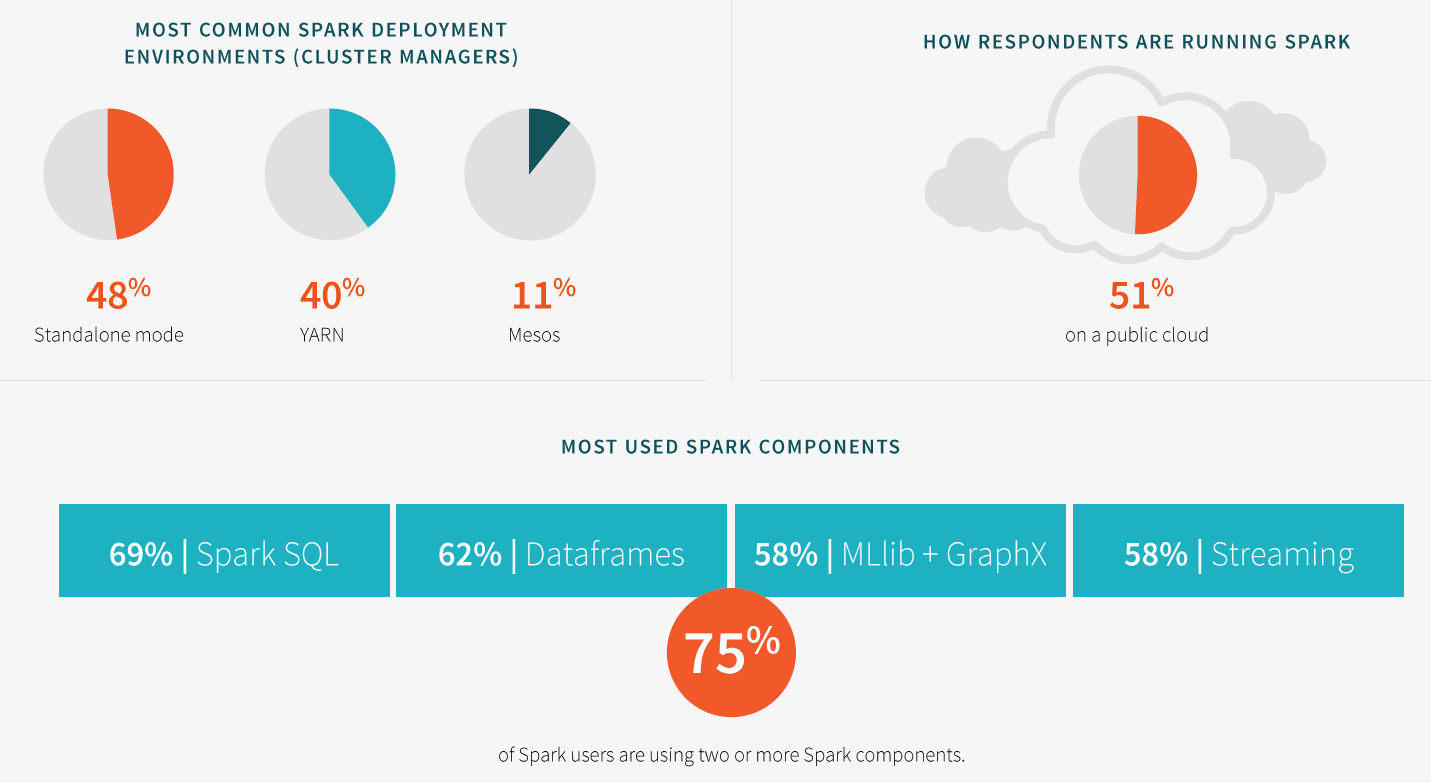
Spark adoption according to Databricks September 2015 survey
How do developers use Spark? The survey says Scala was the most popular Spark language, with 71% of programmers using that API. Python was the second most popular language, followed by SQL, Java, and R.
Where do you see Spark run? (Run, Spark, run!) According to the Databricks survey, 51% of Spark deployments are on the public cloud. Nearly half of survey respondents (48%) say they run Spark in standalone mode, while 40% say they run it on Hadoop’s resource scheduler, YARN.
Only 11% of users reported running Spark on Mesos, the distributed resource scheduler that forms the heart of BDAS, the Berkeley Data Analytics Stack that, like Spark, came out of Cal’s AMPLab. Matei Zaharia, the creator of Spark and co-founder and CTO of Databricks, also co-created Mesos.
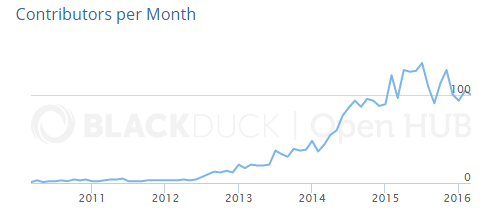
Spark consistently has more than 100 contributors per month (Source: BlackDuck)
Spark can no longer be considered the new kid on the big data block. We’ve seen other frameworks, like Apache Flink and Apache Beam, emerge to provide competition to Spark. Some of these other frameworks are quite compelling, and may do certain things better than Spark, according to big data experts and benchmark tests.
But despite the competition, Spark remains the hottest technology in big data. That says a lot about the value that developers, engineers, and data scientists are getting out of the open source software, and it says a lot about where big data tech will go next.
Related Items:
How Spark and Hadoop Are Advancing Cancer Research
How Uber Uses Spark and Hadoop to Optimize Customer Experience
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States