

February 25, 2016
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine

via Shutterstock
The folks at Databricks last week gave a glimpse of what’s to come in Spark 2.0, and among the changes that are sure to capture the attention of Spark users is the new Structured Streaming engine that leans on the Spark SQL API to simplify the development of real-time, continuous big data apps.
In his keynote at Spark Summit East last week, Spark creator Matei Zaharia said the new Structured Streaming API that will debut later this year in Spark 2.0 will enable the creation of applications that combine real-time, interactive, and batch components.
“This is the thing that current streaming engines don’t really handle,” the Databricks co-founder and CTO said. “They’re just built for streaming. They’re just like ‘Give me a stream in and I’ll give you a stream out.’ That’s it.”
But Structured Streaming—which is largely built on Spark SQL, but includes some of the ideas from Spark Streaming and is based on the Datasets API—is different for several reasons.
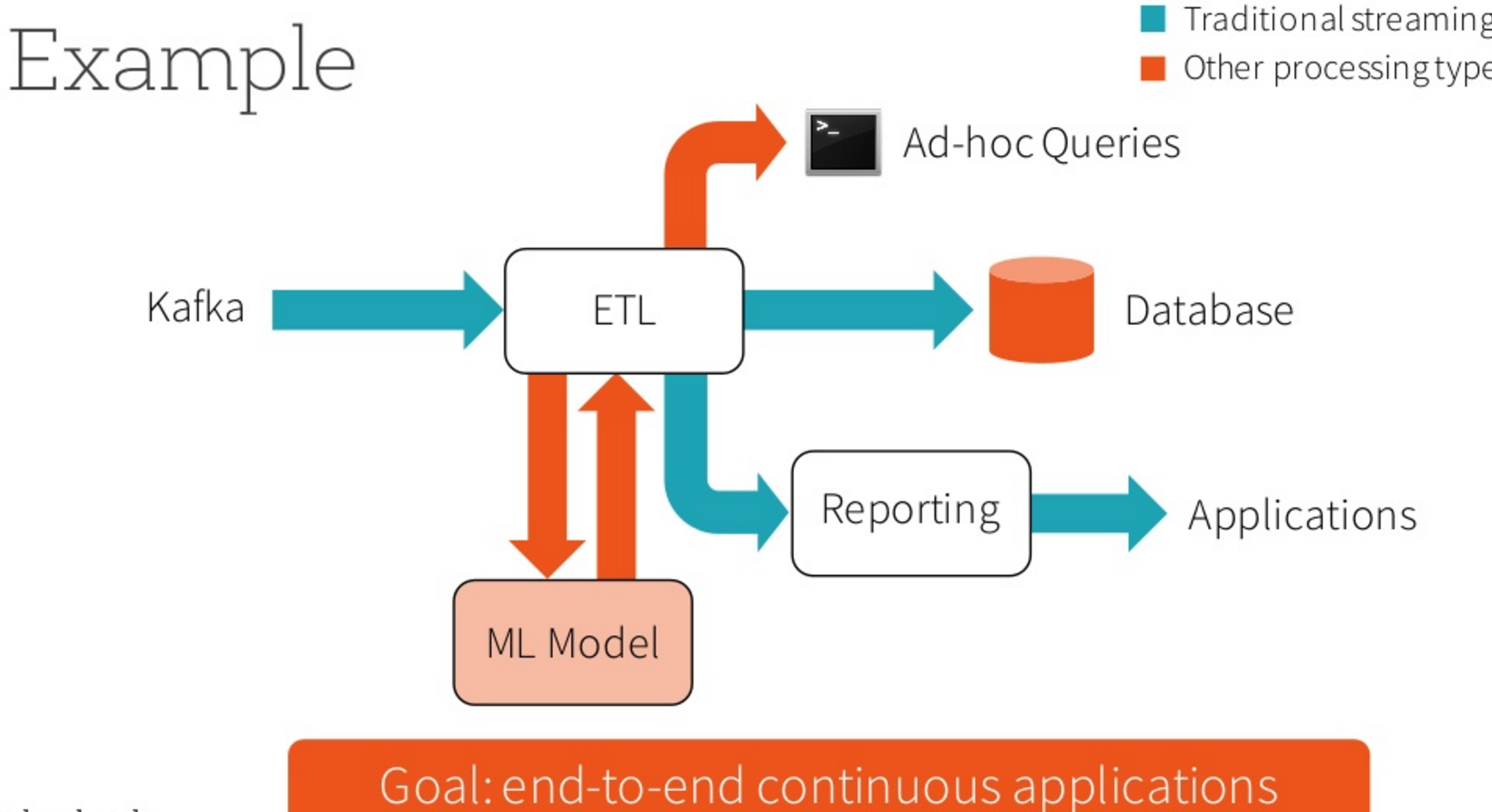
Structured Streaming will simplify and unify the development and execution of continuous applications, according to Zaharia
“On top of the streaming, it also supports interactive and batch queries in a way that no other streaming engine does,” Zaharia continues. “For example you can do things like aggregate the data in a stream and then serve it using the Spark SQL JDBC server and just have ad hoc SQL queries that act on the latest thing…And you can also build and apply machine learning models. We’re making most of the libraries in Spark interact with this.”
At a technical level, Structured Streaming is a declarative API that extends DataFrames and Datasets, the higher-level APIs that were added to Spark in 2015 to provide a simpler programming model—and one that supports static typing–compared to the low-level Resilient Distributed Datasets (RDDs) API that Spark originally shipped with. With Spark 2.0, DataFrames and Datasets are being combined into a single API to make life simpler for developers.
By enabling various analytic workloads, like ad hoc queries and machine learning modeling, to run directly against a stream using a high-level, SQL-like API, Structured Streaming will substantially simplify the development and maintenance of real-time, continuous applications, Zaharia says.
“In classical streaming, you take in data from something like Kafka, and maybe do ETL, do a math function…then stick it into some other system like a database. Or sometimes streaming is about, OK you do ETL, then you build a report, and then you serve to some application,” he said. “With Structured Streaming you can…do ad hoc queries on the same stream. No need to put it in some other weird storage system and then worry about consistency….Likewise you can run machine learning, and maintain it. That might involve running a batch job once in a while, and then serve it and apply it back to a stream. It’s very hard to do that with a purely streaming engine.”
Spark Streaming, which uses what’s been called a “micro-batch” architecture for streaming applications, is among the most popular Spark engines. The new Structured Streaming engine will represents Spark’s second attempt at solving some of the tough problems that developers face when building real-time applications, said Databricks’ co-founder and Chief Architect Reynold Xin.

You can view Zaharia’s entire Spark Summit East keynote here
“Since Spark Streaming was introduced about three year ago, we worked with hundreds of deployments and we have learned a lot in this journey,” Xin said during his keynote. “What we learned is streaming computation typically doesn’t exist in isolation. It’s usually combined with a lot of other computations…I think this is the best [attempt] so far to unify streaming, interactive, and batch queries so you can substantially simplify continuous applications.”
Simplification is the overriding engineering principle behind Structured Streaming. “The simplest way to perform streaming analytics is to not have to reason about streaming analytics,” Xin said, insisting to the audience that he had, indeed, drunk his morning coffee and had not ingested anything else to cloud his thinking.
Essentially, Structured Streaming enables Spark developers to run the same type of DataFrame queries against data streams as they had previously been running against static queries. Thanks to the Catalyst optimizer, the framework figures out the best way to make this all work in an efficient fashion, freeing the developer from worrying about the underlying plumbing.
“A lot of things should just work out of the box without you needing to worry about all the nitty gritty details,” Xin said. “We don’t want only the PhDs in computer science that can actually understand this [to be the only ones who can] build robust streaming applications. We want to really take it to scale to the masses. I think finally we have an answer.”
While Structured Streaming aims to simplify development, it doesn’t come at the cost of features that enterprises demand from a real-time streaming engine, such as fault tolerance, elastic scaling, the ability to recover from out of order data, windowing and session management, and pre-built support for a diverse range of data sources and sinks, like Kafka and MySQL.

Structured Streaming lets developers build continuous applications using the same tools and techniques they used to write queries no static data
Xin also spent a bit of time explaining the importance of support for “exactly once” semantics, which ensures that an event or file is processed once, and only once. This is a bigger deal than may first be apparent, according to Xin. “It turns out a lot of the streaming engines work with exactly one semantics within in the engine itself,” he said. “But as soon as you actually want to include some output operations, it’s actually very difficult to guarantee you have exactly one semantics.”
The first release of Structured Streaming will be geared toward ETL workloads, and will give the user options for specifying the input, the type of query, a trigger, and an output mode. The options surrounding Structured Streaming will be bolstered with Spark 2.1 and subsequent releases, with will include additional operators and libraries.
Structured Streaming is a part of Apache Spark’s project Tungsten initiative, which aims to bypass and blunt some of Java’s bloat when running on Intel (NYSE: INTC) processors. And as such, Structured Streaming will be able to take advantage of all the benefits that the ongoing Tungsten project is bringing to Spark SQL, MLlib, and other Spark engines.
Spark 2.0 also marks the beginning of phase 2 of the Tungsten project, which should deliver speedups of 5 to 10x, Zaharia said during his keynote. This will be accomplished by bringing Spark closer to bare metal, and specifically by enhancing how Spark manages memory and through its runtime code generation. With Spark 2.0, Tungsten is also being applied to the DataFrame and Dataset APIs, which (as we already mentioned) are being joined together into one API, and which will also be used with Structured Streaming.
Zaharia said the new “whole-stage” code generation in Spark 2.0 will remove expensive calls and fuse operators, thereby delivering about a 10x speedup in Spark performance. The version 2 release will also optimize the Spark’s I/O by using Parquet (plus a built-in cache). This will automatically apply to SQL, DataFrame and Datasets APIs, he said.
Related Items:
3 Major Things You Should Know About Apache Spark 1.6
Spark Streaming: What Is It and Who’s Using It?
Skip the Ph.D and Learn Spark, Data Science Salary Survey Says
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States