

March 31, 2016
Spark Leads Big Data Boom, Researcher Says

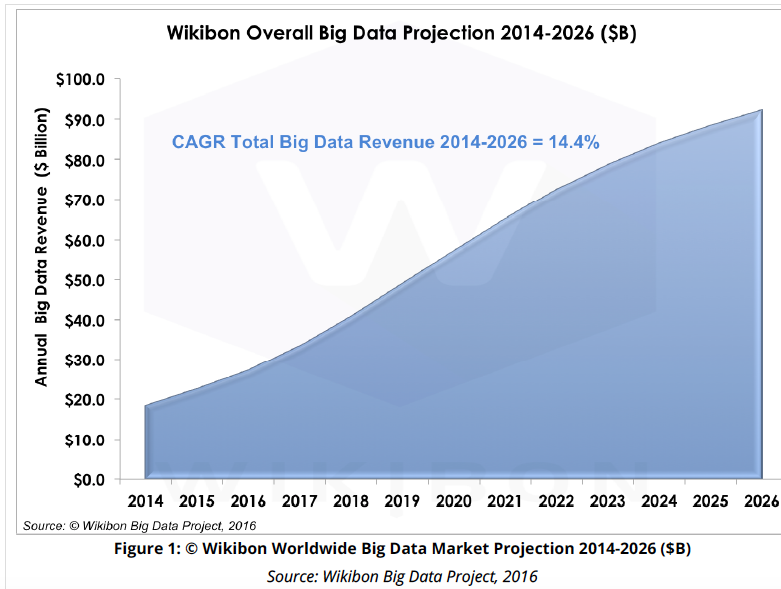
The global big data market is poised to explode over the next decade, according to a new forecast, topping an estimated $92 billion by 2026 as new streaming analytics technologies emerge.
Market researcher Wikibon said this week it expects the global demand for big data services to grow at a hefty 14.5 percent annual rate over the next decade. It currently pegs the worldwide big data market at about $18.2 billion.
In a forecast released at this week’s Strata+Hadoop World event in San Jose, Wikibon also released an assessment of the burgeoning Apache Spark market, asserting: “Spark aims to replace not Hadoop, but the bulk of Hadoop mix-and-match zoo of analytic engines.” Nevertheless, the researcher forecast that the global market for “unified” streaming analytics technology driven largely by Spark adoption will account for 16 percent of total big data spending by 2020, or about $11.5 billion.
Among the keys to big data growth are maturing practices and improved software. Hence, Wikibon forecasts that global enterprises will be five times more likely to shift platforms from testing to production in the coming year.
Big data investments will be driven over the next decade by predictive application technologies, “edge tooling” and the emerging Internet of Things (IoT). Improved software and pervasive public cloud platforms also are expected to accelerate the use of big data techniques beyond data scientists.
The market researcher identified three key drivers of big data demand. The first is “maturing data lakes,” a trend that is expected to peak around 2020. “There will continue to be significant value for this use case and the related analytics, but we think demand for this use case will drop below double digital growth by 2021 as enterprises turn attention from repository to machine learning technologies,” Wikibon predicted.
The second trend focuses on what the market researcher calls “evolving intelligent systems of engagement” as enterprises integrate more big data capabilities into their applications. “The use case possibilities are myriad, but anticipating, predicting and ultimately influencing customer-facing digital experiences are driving the adoption of the ‘intelligent systems of engagement’ big data pattern,” the analyst said. Moreover, these systems could account for as much as 23 percent of big data market by 2026.
The third demand driver is “emerging intelligent self-tuning systems” that leverage machine learning to improve predictive analytics. Wikibon expects demand for these systems to ramp up quickly, becoming as prominent (38 percent of the market) as data lakes over the next decade.
Meanwhile, the market researcher predicts Apache Spark will be a “crucial catalyst” for driving its three main big data application patterns. Spark-based investments are expected capture an estimated 6 percent of total big data spending this year, soaring to 37 percent by 2022.
While Spark initially addresses the limitations of Hadoop, the market researcher cited other factors to explain its expected growth. Among them are performance breakthroughs provided by the in-memory processing engine. ” Memory-resident operation allows Spark to operate not just at speed, but to optimize operations from beginning to end,” Wikibon stressed.
While Spark community leader Databricks is “democratizing access” to ecosystem with new tools and services, the market researcher noted that “different members of the big data ecosystem are trying to coopt Spark’s popularity and direct investment toward their platforms.” Among them is IBM, which announced a major commitment to Apache Spark last year.
Nevertheless, Spark is widely seen as a key technology for advancing big data technologies. If it falls short, “other platforms are already on the drawing board in case the Spark community can’t overcome Spark’s limitations,” Wikibon noted.
One early test will be determining how well Spark functions at the edge of the IoT. In order for it to work, “the community is going to offer a cut down, sped up version,” the analyst concluded.
Recent items:
Why Spark is Proving So Valuable for Data Science in the Enterprise
Spark 2.0 to Introduce New ‘Structure Streaming’ Engine
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States