

February 29, 2016
Why Spark Is Proving So Valuable for Data Science in the Enterprise

What do Bloomberg, CapitalOne, and Comcast have in common? If you said they’re operationalizing data science using Apache Spark, then give yourself a gold star. These companies shared their stories of the upstart analytics toolbox during the recent Spark Summit East conference, and as the stories show, Spark is not only helping enterprises achieve analytic dreams, but they’re accelerating the development of Spark along the way.
If you’re a regular reader of this publication, then you already know about that Apache Spark is currently the hottest project in the big data analytics and data science community. The Hadoop distributors have long since jumped on the Spark bandwagon, and even IBM is now singing the praises of the free and open source distributed analytic framework that competes with so many of its proprietary offerings.
But as is the case with any new technology, the proof is whether customers adopt it. According to the presentations made at the Spark Summit East conference held in New York City two weeks ago, the adoption is large, and getting larger by the day.
Petabyte-Scale Analytics
Sridhar Alla, the director of EBI solutions architecture and a big data architect at cable giant Comcast, told the audience that the company has all sorts of big data analytics projects in play, including trying to learn more about customers by analyzing their clickstreams. But one of its more interesting ways it’s using Spark is to detect anomalies in its 30 million cable boxes, which generate more than 1 billion data points every day.

Spark helps Comcast detect anomalies in the functioning of set-top cable boxes
“At petabyte scale, the big difficulty is what to really focus on,” Alla told his audience at Spark Summit East. “You want me to look at power consumption of the amplifier? Fine. What about the radio frequency? Fine. What about color of the box? Maybe it has something to do with the chemicals in the paint that they’re using to paint the box? You never know. That’s the kind of problem you’re faced constantly.”
Comcast is performing anomaly detection for its set-top boxes by running Spark on a 400-node cluster that sports nearly a terabyte of RAM and 8 PB of raw storage. Putting that kind of horsepower behind Spark lets Alla’s large team of data scientists to explore the data and come up with solutions to real-world problems.
“It [Spark] is giving us more benefit than a lot of other models,” Alla said. “Not to say that other machine learning algorithms are not good. There are very specific vendors out there in particular areas that do a better job at specific algorithms…But in general we found it was very good here because we had a lot of data coming in real time versus batch. And…we do have data at petabyte scale.”
Analytics of a Higher Order
Spark also plays a role in the development of Bloomberg’s low-latency, cloud-based analytics platform, which is used to serve financial data to the company’s clients. By using a Spark concept called a DataFrame, the company is able to build higher order analytics, in which fresh calculations are based on older calculations, ad infinitum.
Spark is important because it eliminated a trade-off that previously bedeviled developers of analytic apps, Bloomberg architect Partha Nageswaran says. “Traditionally this problem has been solved by trading off latency for on-the-fly” calculations, Nageswaran says. “But with the advent of technology like Spark we can actually talk about these two concepts within the same sentence and make them happen.”
 However, the rapid adoption of Spark also let some old problems creep back in. According to Nageswaran, Spark clusters started proliferating at Bloomberg about 1.5 years ago. “Almost always the standard mode of operation was to take a standard infrastructure, put a Spark cluster on top of it, and craft Spark applications,” he said. “This was great to get off the block. But you can see immediately the synthetic boundaries that are [created] by the various silos essentially make it harder, if not impossible, to do higher order compositional analytics on top of the output of each of the Spark applications.”
However, the rapid adoption of Spark also let some old problems creep back in. According to Nageswaran, Spark clusters started proliferating at Bloomberg about 1.5 years ago. “Almost always the standard mode of operation was to take a standard infrastructure, put a Spark cluster on top of it, and craft Spark applications,” he said. “This was great to get off the block. But you can see immediately the synthetic boundaries that are [created] by the various silos essentially make it harder, if not impossible, to do higher order compositional analytics on top of the output of each of the Spark applications.”
This led to the concept of “serverizing” Spark, which was the topic of the presentation by Nageswaran and fellow Bloomberg worker Sudarshan Kadambi. According to Nageswaran, by centralizing the Spark cluster and keeping the insights within a single system, it can eliminate the impedance to sharing caused by separate Spark clusters. The company developed a concept called Managed DataFrames to help it.
Spark Gone Viral
Bloomberg and Comcast are at the beginning of the wave of Spark adoption, but don’t be surprised if it continues. “This thing has gone so viral,” said Ovum analyst Tony Baer.
Baer is old enough to remember when IBM put $1 billion behind an open source operating system at a time when no self-respecting company would be caught dead running critical business systems on free software you could download from the Web. Eventually Linux came to become the dominant operating system, and Baer now sees a similar dynamic at play with Spark.
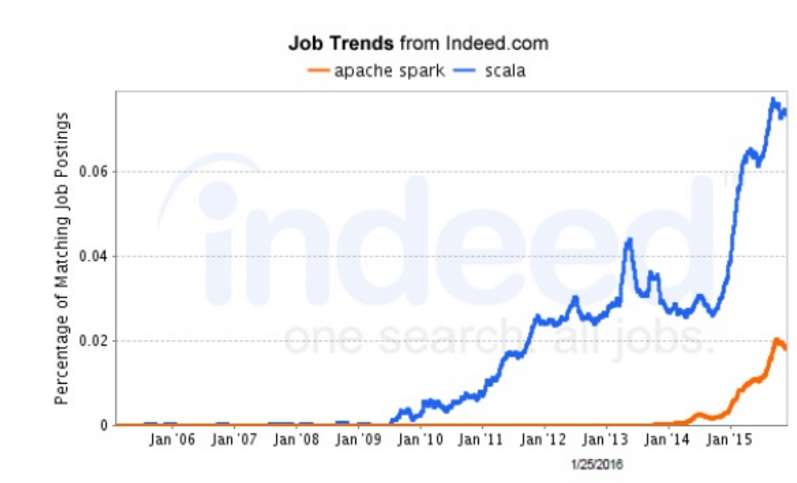
Jobs for people with Scala skills spiked due to the rise of Spark, which was written in Java, Baer says
“The significance of the Spark open source project will have the same degree of impact on the enterprise as Linux did about 15 years ago.” There are good reasons for that, Baer says, citing the ease of programming and performance compared to MapReduce.
API consistency is another big reason why Spark is becoming widely adopted, not only by data scientists but software vendors, Baer says. That is creating new opportunities to build big data apps, particularly around machine learning.
“It wasn’t that you couldn’t do machine learning before Spark,” Baer says. “But if you had to do it through MapReduce, it might have taken hours,” compared to minutes or seconds with Spark. “So it makes a huge difference not just in your solution time but the quantity of results you can get.”
A Single Toolbox for Data Science
Forrester analyst Mike Gualtieri agrees that Spark is the real deal. “I’ve been looking at this big data phenomenon for a few years now and Spark is quite remarkable in what we’ve seen in the last year,” he said during his presentation at Spark Summit East.
The biggest driver of Spark adoption by the enterprise is the shift to advanced analytics. According to Forrester figures, the percentage of enterprises reporting that they’re doing some form of advanced analytics has jumped from 31 percent in 2014 to 48 percent in 2015. “There’s a lot of at least reported momentum for enterprise in using these various forms of advanced analytics,” he says. “Spark is one of the solutions that enterprise are going to choose to perform some of these analytics.”
Spark’s flexibility make it suitable for multiple types of analytics, Gualtieri says
In her keynote, Anjul Bhambhri, the VP of product development for IBM’s big data and analytics platform, says Spark is fast becoming the operating system for analytics, just as Linux became the dominant operating system for Web applications.
“Never before has such a rich set of analytical foundational capabilities come together in one platform in one stack,” she says. “Spark is really the single toolbox for analytics. If you have structured data, you use Spark SQL. For semi-structured data, Spark core. If you have data from a firehose, Spark Streaming. For building models, you have MLlib. For learning from graphs of data, there’s GraphX.
“The beauty of this is all of these components work together in a seamless manner,” she continues. “In the past if you needed these kinds of capabilities you needed half a dozen products…Today you need just one foundational platform, which is Apache Spark.”
Related Items:
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
Spark Streaming: What Is It and Who’s Using It?
Skip the Ph.D and Learn Spark, Data Science Salary Survey Says
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States