

June 22, 2015
Why Big Data Prep Is Booming

The big data analytics space is growing as organizations attempt to turn massive sets of data into a competitive advantage. But this trend is also driving a secondary boom in the market for data preparation tools that clean big data prior to analysis.
The hype surrounding big data masks a dirty little secret: Most data sets are relatively dirty and must be thoroughly cleaned, lest the resulting analytic results be tainted and unusable. Necessity is the mother of all invention, which is why some smart folks at startups like Trifacta, Tamr, and Paxata–not to mention existing companies like Informatica, IBM, and Progress Software–are turning this need into a winning business model.
“In the 20 years I’ve been in this space, the thing that always remains the same is the data is always dirtier than you think,” Trifacta CEO Adam Wilson told Datanami at the Hadoop Summit earlier this month. “There needs to be some inherent structure for a lot of the reporting and analytic tools to grab onto. And it doesn’t matter what your intended use of the data is–if you get that wrong, then everything downstream of that is going to be problematic.”
Trifacta recorded more bookings in the first quarter of 2015 than in all of 2014 combined, Wilson said. Most of this momentum comes from larger organizations that are looking to take their Hadoop clusters from experimental phase into production and can no longer afford to mess around with messy data.
“They get big data intrinsically, but now they’re really looking to demonstrate ROI for very specific use cases,” he says. “It’s not enough to deploy [a cluster]. You have to be thinking about the use cases and how you get the data ready for analysis, to show the value. That fact is actually driving a lot of momentum for us.”![TRIFACTA_ID_STACKED[1]](https://www.datanami.com/wp-content/uploads/2015/06/TRIFACTA_ID_STACKED1.png)
As the amount of data that companies want to analyze continues to grow, it very quickly becomes a process that the IT department—traditionally the stewards who analysts turn to for their daily dole of data–can no longer handle. “We’re very proudly data janitors,” Wilson says. “We love the fact that we take care of this nasty, messy problem.”
Tamr is also looking to exploit the dirty data problem in pursuit of software license and maintenance revenue. The company, which was founded by Vertica founders Andy Palmer and Mike Stonebraker, uses a combination of machine learning algorithms and crowdsourced human oversight to automate much of the work that goes into combining and integrating siloed, semi-structured data so that it can be more effectively utilized in analytic systems.
Last week, the Cambridge, Massachusetts company announced that it has received $25.2 million in Series B funding from Hewlett Packard Ventures, Thomson Reuters, and MassMutual Ventures, among others. Palmer, the CEO of Tamr, says the money will be used to further development of the data unification product.
“Our latest financing gives us the resources to meet the incredible demand that we’ve experienced in the year since we launched Tamr,” Palmer writes in a blog post. “It also reflects the interest that some large and leading enterprises have in tackling data variety as they move towards being truly data- and analytic-driven. I believe companies on the cutting edge of this data-driven transformation recognize very quickly that data variety is the primary bottleneck — and only a small amount of new tech like Tamr is required to enable their entire organization to use data efficiently.”
Stonebraker, who received the Turing Award last Friday, predicts big things for data unification. “Tamr’s technology and approach to scalable data unification will be the next big thing in data and analytics – similar to how column-store databases were the next big thing in 2004,” he says.
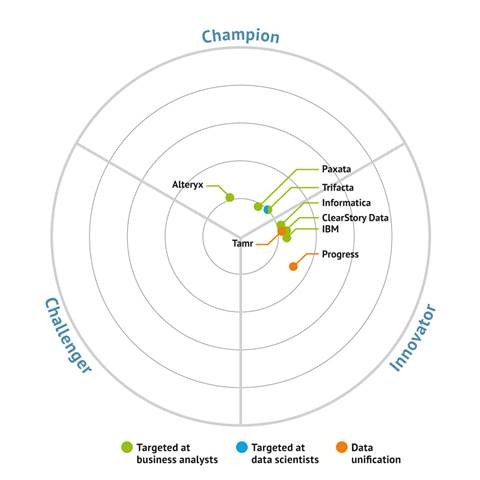
Bloor Research rated the various self-service data preparation software providers
Meanwhile, Paxata is finding momentum building for its data prep tools, which uses a combination of machine learning algorithms and data visualization techniques to help analysts identify and fix anomalies in their data. At last week’s Spark Summit, the company, which has 45 paying customers, announced that it’s now running on the latest release of Apache Spark.
Basing Paxata on Spark was a good decision, says Prakash Nanduri, co-founder and CEO of the San Francisco company. “A year and a half ago, we recognized how data preparation enabled by Spark could deliver transformational business value with unprecedented economics,” he says. “The entire enterprise landscape is dramatically shifting with disruptive technologies which are fundamentally changing the cost-to-computational performance ratio.”
Paxata was among the software vendors who showed well in recent report on self-service data preparation tools by Bloor Research’s research director Philip Howard. The data prep pure-plays Paxata and Trifacta were listed in the “Champion” sector of the report, along with Alteryx, which does self-service data prep alongside advanced analytic capabilities. Meanwhile, Tamr was included in the “Inovator” sector of Bloor’s report, alongside traditional ETL megavendors Informatica and IBM; Progress Software‘s Easyl tool; and ClearStory Data, which provides data blending and harmonization capabilities as part of a larger, Spark-based big data analytics package.
“The key ingredient of data preparation platforms,” writes Bloor’s Howard, “is their ability to provide self-service capabilities that allow knowledgeable users, who are not IT experts, to combine, transform and cleanse relevant data prior to analysis.”
Paxata is providing copies of the report to the public here.
Related Items:
Tamr Whips Semi-Structured Data Into Shape
How Dannon Upgraded Its Reporting Culture with Big Data Tooling
Automating the Pain Out of Big Data Transformation
Applications:
Predictive Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States