

August 29, 2014
Hadoop Labor Update: Cloudera Talks Impala 2.0 as Hortonworks Previews Kafka
Say what you will about Hadoop (and we do), the big data platform is evolving at an incredible rate. This week, two of the biggest Hadoop distributors, Hortonworks and Cloudera, shared how they’re working to improve two key aspects of the platform: real-time data pipelining via Apache Kafka and SQL-based data warehousing via Impala.
Let’s start with Cloudera. This week, the Hadoop distributor announced that the upcoming release of Impala 2.0 will add much more complete SQL functionality to CDH, the Cloudera Distribution for Hadoop commercial offering. In a blog post, Cloudera’s Director of Product Management at Cloudera, Justin Erickson, and Impala’s architect and the Impala tech lead at Cloudera, Marcel Kornacker, said the fall 2014 release of Impala 2.0 will be “the most significant milestone since GA.”
To recap: Cloudera shipped the first GA release of Impala in May 2013, thereby providing its customers with a SQL-like interface for writing ![]() interactive queries in a manner similar to massively parallel processing (MPP) data warehousing platforms, like Teradata, EMC Greenplum, HP Vertica, and IBM Netezza.
interactive queries in a manner similar to massively parallel processing (MPP) data warehousing platforms, like Teradata, EMC Greenplum, HP Vertica, and IBM Netezza.
Since then, Impala has been downloaded 10,000 times, Cloudera says. Along the way, it’s added new features through regular updates, including versions 1.2 (October 2013), version 1.3 (May 2014), and version 1.4 (July 2014). Scalability has always been core to the Impala value proposition, and Clouder has responded with impressive benchmark figures against other SQL-on-Hadoop options such as Hive (the target of Hortonworks’ Stinger initiative), Shark, and Presto. The software has also been adopted by Hadoop distributors looking for interactive SQL capabilities, including MapR Technologies and Amazon Web Services, and it’s used in Oracle‘s Big Data Appliance. (Cloudera and Oracle are close partners.)
With the upcoming Impala 2.0 launch this fall, Cloudera is focusing heavily building out its support for SQL analytic functions. It will bring support for window functions (such as aggregation Over Partition, Rank, Lead, Lag, Ntile); support for external joins and aggregations using disk; and support for subqueries inside Where clauses (you can see the full list of upcoming features here).
 “Essentially, the Impala 2.0 milestone marks the point at which Hadoop users will get the ‘whole package’: the expected SQL support and performance of commercial MPP-query engines, running natively on Hadoop,” Erickson and Kornacker write.
“Essentially, the Impala 2.0 milestone marks the point at which Hadoop users will get the ‘whole package’: the expected SQL support and performance of commercial MPP-query engines, running natively on Hadoop,” Erickson and Kornacker write.
The company also provided a teaser for what’s coming in 2015 with Impala version 2.1, including support for queries on nested structures, support for MERGE statements, new analytic SQL functions like Rollups, Cubes, and Grouping Sets. It will also bring closer integration with HBase, Parquet, and Amazon S3.
“From the outset, we described the Impala journey as one that would take its users beyond the limits of what they thought Hadoop could do by offering the performance and SQL capabilities of traditional analytic DBMSs natively on Hadoop data,” Erickson and Kornacker write. “The functionality delivered thus far has certainly done that in terms of performance, and with the features planned for Impala 2.0, we’re confident it will do the same with respect to SQL functionality.”
Data warehousing and SQL analytics is one area where Hadoop is starting to gain some traction (although some have their doubts whether Hadoop will ever completely replace dedicated analytics systems). Meanwhile, the other big Hadoop company that calls Palo Alto, California home is gearing up to improve another big emerging Hadoop use case: Real-time stream processing.
Hortonworks this week announced that Apache Kafka is now available as a technical preview with Hortonworks Data Platform (HDP) 2.1. That means Kafka will most likely be fully supported in the next release of the commercial product.
Kafka is a scalable and fault-tolerant messaging system that was originally developed by LinkedIn to supports the activity stream data and operational metrics on its website. Today Kafka is used by a number of organizations, such as Spotify, Twitter, and Netflix, where it handles various real-time log monitoring, data pipelining, and event-processing tasks.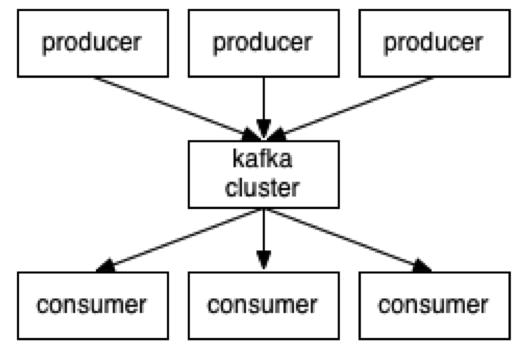
Hortonworks sees Kafka playing quite well with Apache Storm, the distributed real-time computational system that was developed by Twitter. “Combining both technologies enables stream processing at linear scale and assures that every message is reliably processed in real-time,” Hortonworks developer Sriharsha Chintalapani writes on the company’s blog.
Storm already supports using Kafka 0.8.1 (the one supported by HDP 2.1) as a data source for both Storm’s core “Spouts and Bolts” API as well as the higher-level, micro-batching Trident API. “This allows you to choose the messaging reliability guarantees that best fit your individual use case,” Chintalapani writes. “Given this degree of flexibility, a common architectural pattern has emerged where Kafka is used to front an unreliable data source, such as the Twitter firehose, in order to provide fault tolerance and guaranteed message delivery.”
Related Items:
Why Hadoop Isn’t the Big Data Solution You Think It Is
Hortonworks Drives Stinger Home with HDP 2.1
Cloudera Touts Near Linear Scalability with Impala
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States