

January 13, 2014
Cloudera Touts Near Linear Scalability with Impala
Cloudera today unveiled results of internal tests that show its Impala SQL engine is twice as fast as an unnamed commercial data warehouse systems and 24 times faster than Apache Hive. The results also show that Impala scales in nearly a linear fashion on Hadoop, which Cloudera says will give customers the confidence they need to not only absorb legacy business intelligence workloads, but also build the next generation of SQL-powered data analytic applications.
![]() Among Hadoop vendors, the race is on to deliver the best SQL performance. This is important for several reasons, including the fact that most of the world’s existing business intelligence products speak SQL, and getting these to work with Hadoop-resident data would allow Hadoop vendors to absorb legacy BI workloads (think Teradata, IBM Cognos, Oracle Hyperion, and SAP BusinessObjects). Beyond that, vendors like Cloudera see SQL as a key enabling technology for bringing future workloads, such as applications that run new machine learning algorithms, to Hadoop.
Among Hadoop vendors, the race is on to deliver the best SQL performance. This is important for several reasons, including the fact that most of the world’s existing business intelligence products speak SQL, and getting these to work with Hadoop-resident data would allow Hadoop vendors to absorb legacy BI workloads (think Teradata, IBM Cognos, Oracle Hyperion, and SAP BusinessObjects). Beyond that, vendors like Cloudera see SQL as a key enabling technology for bringing future workloads, such as applications that run new machine learning algorithms, to Hadoop.
Cloudera is riding Impala, the open-source processing engine for SQL that it unveiled in October 2012 and shipped in its commercial Cloudera Distribution for Hadoop (CDH) product in May 2013. MapR Technologies and Amazon Web Services are also riding the Impala train, while other Hadoop vendors, such as Hortonworks, continue to ride Apache Hive.
Cloudera set out to demonstrate how far Impala has come since it started shipping the SQL engine in CDH. For starters, the company compared how quickly Impala could chew through 3TB of the TPC-DS decision support benchmark data on a five-node cluster. It then ran the same job using the latest release (version 0.12) of Hive, which continues to be the standard-bearer for SQL processing on Hadoop.
 |
|
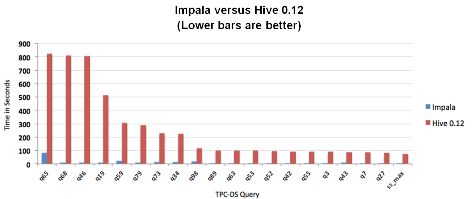
| Impala showed lower response times than Hive | |
The results of the first test showed that Impala was anywhere from six to 69 times faster than Hive, depending on the type of query. The results shouldn’t surprise anybody, considering Hive’s dependence on MapReduce and the considerable work people have gone through to optimize their Hive queries, using Pig and other techniques. (However, Hortonworks is particularly excited about the possibilities to boost Hive processing through the new Tez framework. Stay tuned to Datanami for more on that.)
For the second test, Cloudera compared Impala against a popular analytical database system, dubbed DBMS-Y, using 30TB of the TPC-DS data on a 20-node cluster of X64 servers. Cloudera would not share the name of the DBMS vendor (for “licensing reasons,” it explained), but you can bet it’s from a well-known company–and one who’s legacy data warehousing business Cloudera covets.
 |
|
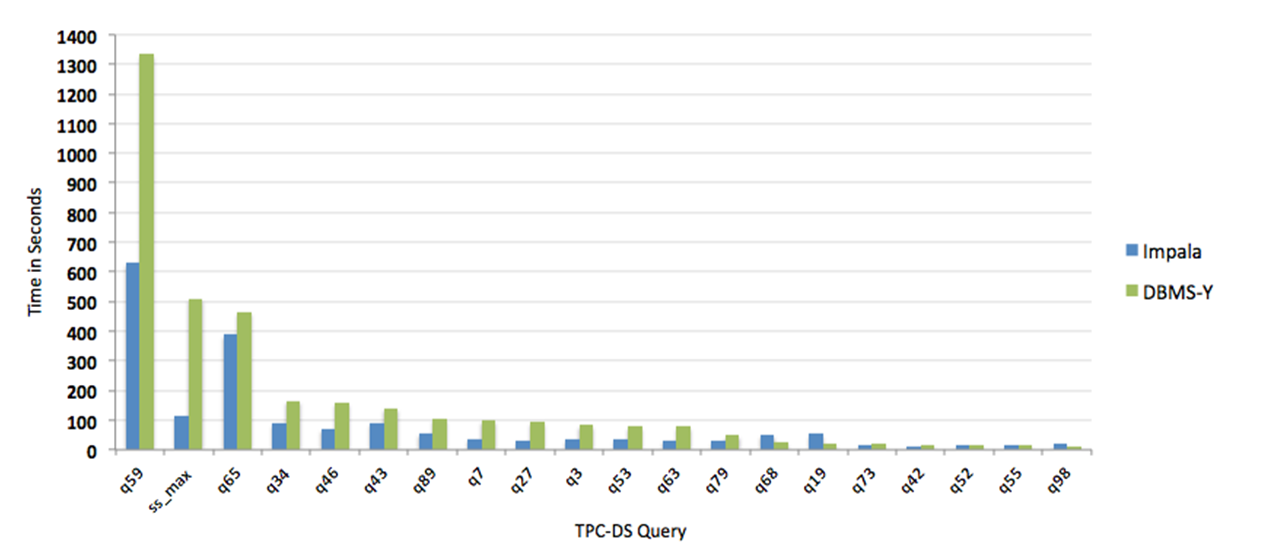
| Impala outperformed the DBMS-Y by an average of 2x | |
To do the comparison, Cloudera loaded the TPC-DS data into legacy database vendor’s proprietary columnar data store for the DBMS-Y test, and for the CDH test, into Parquet, and open columnar data format. CDH outperformed DBMS-Y on 17 of the 20 tests. On average, the queries ran twice as fast, the company says. You can see the results of the tests on Cloudera’s developer blog.
The tests demonstrate that SQL on Hadoop is evolving quickly, says Marcel Kornacker, a Cloudera software engineer at the original architect of Impala. “The goal of Impala is definitely to be able to match the SQL functionality that people are used to from commercial analytic database systems, but at the same time retain the advantages of the Hadoop environment,” he tells Datanami.
“We’re seeing a lot of interest in connectivity to regular BI tools,” Kornacker continued. “We are certified against a number of partners, such as Tableau and MiroStrategy. This is what our customers are interested in–using their existing tooling, and basically trying to run the SQL as unmodified as possible.”
On the scalability front, Cloudera ran three tests to see how query performance changed with the size of the cluster, the number of concurrent users, and the expected response times (latency). In all cases, Impala demonstrated near linear scalability, at least on clusters up to 36 nodes.
The tests show that Impala does scale, in fact, linearly along those dimensions, Kornacker says. “That’s relevant because it says, with Impala you are retaining the Hadoop advantage of basically linear scalability,” he says. “You can simply grow your cluster by adding more hardware, and you can address a larger user pool and/or larger data sets very easily. We think of that as being one of the main advantages of Hadoop, and that is available through Impala.”
 |
|
| Doubling the hardware cut the Impala response times in half | |
The future for Impala looks bright in 2014. For starters, the company plans to ramp scalability testing up, possibly with a 1,000-node test. “We can’t confirm perfect scalability, but that’s on the roadmap,” Kornacker says. The upcoming version 2.0 release of the product calls for new features, such as support for e user defined table generating functions, which will allow Impala to run complex machine-learning type logic inside parallel and scalable data flows, Kornacker says.
“We are looking at making Impala more accessible to data scientists. We see Impala as being complementary to data science and machine learning-type workloads,” he says. “I do expect there to be adoption by users that go beyond the additional analytic and reporting type workloads.”
Related Items:
OLTP Clearly in Hadoop’s Future, Cutting Says
Making Hadoop Into a Real-Time SQL Database
Cloudera Articulates a ‘Data Hub’ Future for Hadoop
Technologies:
Middleware
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States