

September 7, 2023
Starburst Brings Dataframes Into Trino Platform

(Semisatch/Shutterstock)
Starburst customers who prefer to manipulate data using dataframes as opposed to regular SQL will be happy with a pair of announcements made today. That includes the introduction of PyStarburst, which provides a PySpark-like syntax for transforming data residing in Starburst’s hosted Galaxy environment, as well as support for Ibis, a portable dataframe library developed by Voltron Data.
Starburst is one of the predominant backers of Trino, the distributed query engine that split off from Presto several years ago. Trino predominantly speaks SQL, the lingua franca for data analysis. However, sometimes SQL isn’t the best language for writing complex transformations in Trino and Galaxy environments, says Starburst Product Manager Alex Breshears.
“Some data transformations can get gnarly when you look at it from a SQL statement perspective,” Breshears says. “Say you want to do a join, and then you want to filter on one of those tables, and then summarize on one of them. It just becomes a giant SQL statement.”
In situations like this, instead of writing multi-page SQL statements, data engineers may prefer to manipulate the data through a dataframe, which is an intuitive type of data structure that organizes data into columns and rows. Python is one of the most popular languages for manipulating dataframes, although dataframes can also be used in R, Scala, and other languages. Pandas is a popular Python-based dataframe library, as is PySpark, a Python API for working with dataframes in Apache Spark. Snowflake also released a Python-based dataframe library in its Snowpark environment.
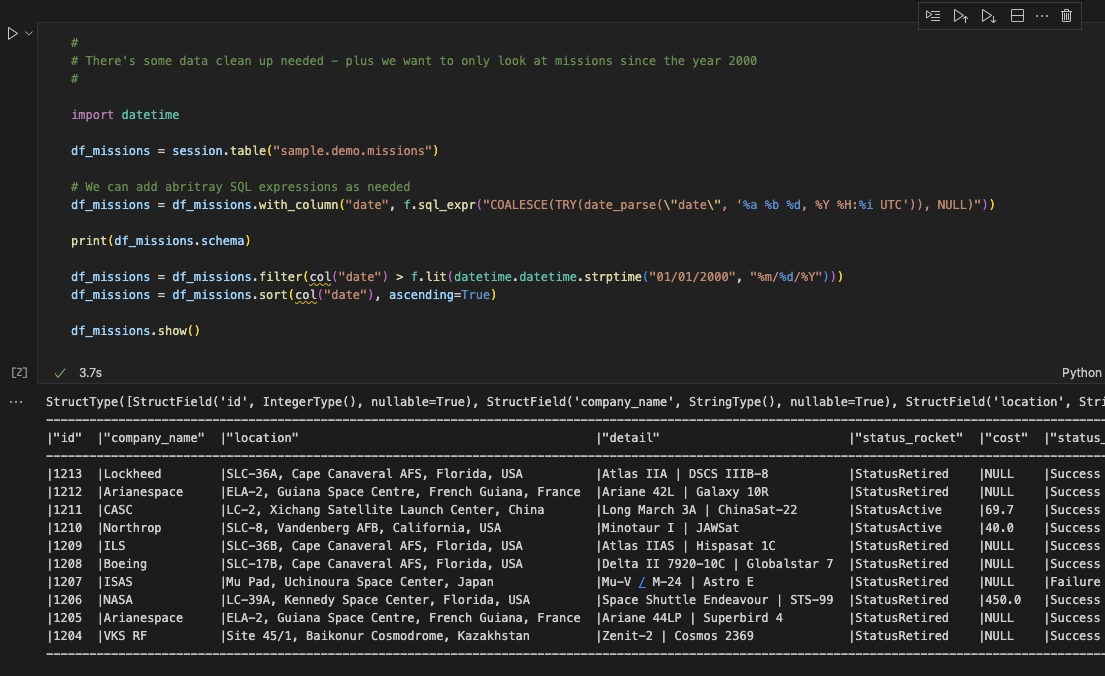
PyStarburst dataframes will simplify data transformation work within Starburst Galaxy (Image courtesy Starburst)
PyStarburst provides a similar capability, with a syntax that is closest to PySpark. According to Breshears, the syntax is 80% to 90% similar, which will allow data engineers who are comfortable with PySpark easily make the move into PyStarburst.
“You’re basically writing PySpark-like data frames that get executed against Trino,” Breshears tells Datanami. “The main target is to allow folks to do those transformations more programmatically, and then make it more friendly to things like CI/CD, version control–basically things that data engineers usually like to do that SQL isn’t necessarily the best use for.”
Starburst has tested PyStarburst with customers to ensure that it’s ready for primetime. According to Breshears, informal benchmarks show performance on the Trino engine with PyStarburst was about 2x what could be achieved using Spark and PySpark.
The integration of Voltron Data’s Ibis library into Starburst also has a dataframe angle.
Ibis is a projected started by Voltron Data founder Wes McKinney (a 2018 Datanami Person to Watch) back in 2016 to make a Python dataframe’s portable across different environments. Data scientists or data engineers can develop a dataframe using, say, Pandas, and Ibis will allow that dataframe to run across a variety of backends, including DuckDB (the default database) as well as BigQuery, Impala, ClickHouse, Druid, Postgres, Snowflake, Oracle, MySQL, SQL Server, Dask, and others.![]()
With today’s announcement, Trino is one of Ibis’ supported backends (or query engine, anyway, since Trino by itself has no storage of its own). This will help data scientists and data engineers move easily from developing code on small laptops to executing it on big clusters, Breshears says.
“You can run it on a local PV [persistent volume] environment, which runs small data, then swap it over to a Trino cluster for at-scale, without changing the code at all,” he says.
While Ibis will run in either Starburst’s enterprise offerings or on open source Trino environments, PyStarbrust is restricted to running only in Starburst Galaxy, the company’s hosted offering that pairs with object storage from any of the big three cloud vendors.
Being able to use dataframes to manipulate data in Trino and Starburst environments is a big plus, as it gives users another coding option when SQL isn’t an ideal fit. But the release of PyStarburst and Ibis are just setting the table for bigger things to come, Breshears says.
“This is the small piece of it compared to what’s coming, from a value perspective, but we have to have this,” he says. “Once we have the ability to create and automate [these jobs] from the tool itself without any local setup, I think customers are going to be excited about that.”
For more info, check out this Starburst blog post from today.
Related Items:
Inside Pandata, the New Open-Source Analytics Stack Backed by Anaconda
Starburst Bolsters Trino Platform as Datanova Begins
Starburst Nabs $250M for Open Analytics on Data Mesh
Applications:
Enterprise Analytics
Tags:
data engineer, data science, data transformation, DataFrame, Ibis, Pandas, PySpark, PyStarburst, python, sql
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States