

August 11, 2022
Data Sourcing Still a Major Bottleneck for AI, Appen Says
(Pixels Hunter/Shutterstock)
Data is the lifeblood of machine. You’re not building anything AI-related without it. But organizations continue to struggle to obtain good, clean data to sustain their AI and machine learning initiatives, according to Appen’s State of AI and Machine Learning report published this week.
Of the four stages of AI–data sourcing, data preparation, model training and deployment, and human-guided model evaluation–data sourcing consumes the most resources, takes the most time, and is the most challenging, according to Appen’s survey of 504 business leader and technologists.
On average, data sourcing consumes 34% of an organization’s AI budget, versus 24% each for data preparation and model testing and deployment and 15% for model evaluation, according to Appen’s survey, which was conducted by the Harris Poll and included IT decision makers, business leaders and managers, and technical practitioners from the US, UK, Ireland, and Germany.
In terms of time, data sourcing consumes about 26% of an organization’s time, versus 24% for data preparation and 23% each for model testing and deployment and model evaluation. Finally, 42% of technologists find data sourcing to be the most challenging stage of AI lifecycle, compared to model evaluation (41%), model testing and deployment (38%) and data preparation (34%).
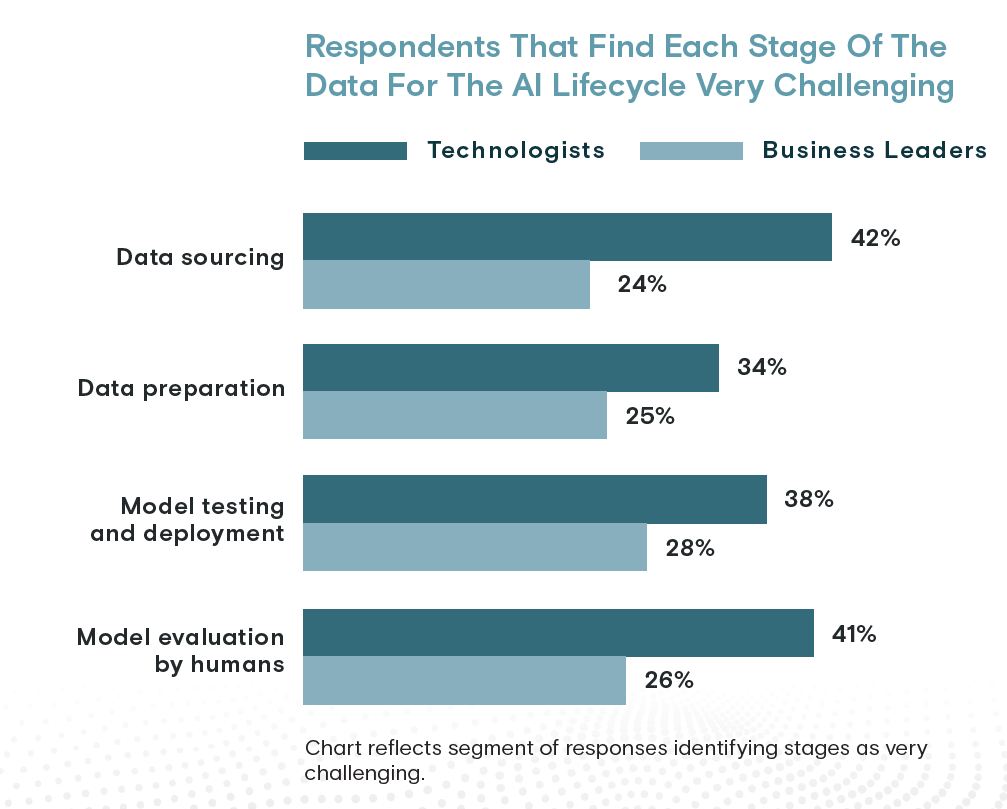
Data sourcing is the biggest challenge in AI, according to technologists. But business leaders see things differently (Graphic courtesy Appen)
Despite the challenges, organizations are making it work. Four out of five (81%) survey-takers say they’re confident that they have enough data to support their AI initiatives, according to Appen. A key to that success may be this: The vast majority (88%) are augmenting their data by using external AI training data providers (such as Appen).
The accuracy of data, however, is in question. Appen found that only 20% of survey-takers reported achieving data accuracy rates in excess of 80%. Only 6%–about one in 20 individuals–say their data accuracy is 90% or higher. In other words, one out of five pieces of data contains an error for more than 80% of organizations.
With that in mind, it is perhaps not surprising that nearly half (46%) of survey-takers agree that data accuracy is important, “but we can work around it,” according to Appen’s survey. Only 2% say data accuracy is not a big need, while 51% agree that it is a critical need.
It appears that Appen CTO Wilson Pang has a different take on the importance of data quality than the 48% of his customers who don’t think it’s critical.
“Data accuracy is critical to the success of AI and ML models, as qualitatively rich data yields better model outputs and consistent processing and decision-making,” Pang says in the report. “For good results, datasets must be accurate, comprehensive, and scalable.”
More than 90% of Appen’s survey-takers say thei use pre-labeled data (Image courtesy Appen)
The rise of deep learning and data-centric AI have shifted the impetus for AI success from good data science and machine learning modeling to good data collection, management, and labeling, Pang told Datanami in a recent interview. That is particularly true with today’s transfer learning techniques, where AI practitioners lob off the top of a large pre-trained language or computer vision model and retrain just a fraction of the layers with their own data.
Better data can also help prevent unwanted bias from seeping into the AI models, and generally prevent bad outcomes in AI. This is particularly true with large language models, according to Ilia Shifrin, senior director of AI specialists at Appen.
“With the rise of large language models (LLM) trained on multilingual web crawl data, companies are facing yet another challenge,” Shifrin says in the report. “These models oftentimes exhibit undesirable behavior due to the abundance of toxic language, as well as racial, gender, and religious biases in the training corpora.”
The bias in Web data raises tricky issues, and while there are some workarounds (changing training regimens, filtering training data and model outputs, and learning from human feedback and testing), more research is needed to create a good standard for “human-centric LLM” benchmark as well as model evaluation methodologies, Shifrin says.
Data management remains the biggest hurdle for AI, according to Appen. The survey finds 41% of individuals in the AI loop identify data management as the biggest bottleneck. A lack of data came in fourth place, with 30% identifying that as the largest impediment to AI success.
But there is some good news: The amount of time organizations spend managing and preparing data is trending down. It was just over 47% this year, compared to 53% in last year’s report, Appen says.

Data accuracy levels may not be as high as some organizations would like (Graphic courtesy Appen)
“With a large majority of respondents using external data providers, it can be inferred that by outsourcing data sourcing and preparation, data scientists are saving the time needed to properly manage, clean, and label their data,” the data labeling firm says.
However, judging by the relatively high rate of errors in the data, perhaps organizations should not be scaling back their data sourcing and preparation processes (whether internal or external). There are a lot of competing needs when it comes to establishing and maintaining a AI process–with the need to hire qualified data professionals being another top need identified by Appen. But until significant process is made on data management, organizations should keep the pressure on their teams to continue pushing the importance of data quality.
The survey also found that 93% of organizations strongly or somewhat agree that ethical AI should be a “foundation” for AI projects. That is a good start, according to Mark Brayan, CEO of Appen, but there’s work to do. “The problem is, many are facing the challenges of trying to build great AI with poor datasets, and it’s creating a significant roadblock to reaching their goals,” Brayan said in a press release.
Internal, custom-collected data remains the bulk of organizations’ data sets used for AI, representing anywhere from 38% to 42% of the data, per Appen’s report. Synthetic data made a surprsingly strong showing, representing 24% to 38% of organizations’ data, while pre-labeled data (often from a data service provider) represents 23% to 31% of the data.
Synthetic data, in particular, has the potential to reduce the incidence of bias in sensitive AI projects, with 97% of Appen’s survey-takers indicating they use synthetic data “in developing inclusive training data sets.”
Other interesting findings from the report include:
- 77% of organizations retrain their models monthly or quarterly;
- 55% of US organizations claim they’re ahead of competitors versus 44% in Europe;
- 42% of organizations report “widespread” AI rollouts versus 51% in the 2021 State of AI report;
- 7% of organizations report having an AI budget over $5 million, compared to 9% last year.
You can download a copy of the report here.
Related Items:
Only 12% of AI Users Are Maximizing It, Accenture Says
Data Is Everywhere, But Harvest Your Own for Peak AI Performance
Companies Going ‘All In’ on AI, Appen Study Says
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States